大型語言模型中的隱私注意事項
經過訓練以預測句子中下一個單詞的基于機器學習的語言模型變得越來越強大、普遍和有用,從而導致問答、翻譯等應用程序的突破性改進。但隨著語言模型的不斷發(fā)展,新的和意想不到的風險可能會暴露出來,這就要求研究界積極努力開發(fā)新的方法來緩解潛在的問題。
其中一種風險是模型可能會從訓練數據中泄露細節(jié)。雖然這可能是所有大型語言模型都關心的問題,但如果要公開使用基于私有數據訓練的模型,則可能會出現其他問題。由于這些數據集可能很大(數百 GB)并且來自各種來源,因此它們有時可能包含敏感數據,包括個人身份信息 (PII)——姓名、電話號碼、地址等,即使是根據公共數據進行訓練的. 這增加了使用此類數據訓練的模型可以在其輸出中反映其中一些私人細節(jié)的可能性。因此,重要的是要識別并最大限度地降低此類泄漏的風險,并制定策略以解決未來模型的問題。
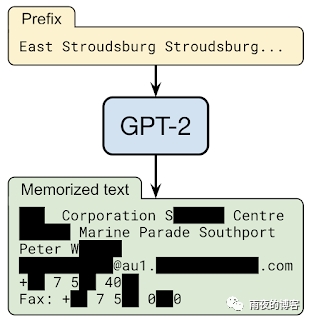
在與OpenAI、Apple、斯坦福大學、伯克利分校和東北大學合作的“從大型語言模型中提取訓練數據”中,我們證明,只要能夠查詢預訓練的語言模型,就可以提取特定的片段模型記憶的訓練數據。因此,訓練數據提取攻擊是對最先進的大型語言模型的現實威脅。這項研究代表了早期的關鍵步驟,旨在讓研究人員了解此類漏洞,以便他們可以采取措施減輕這些弱點。
語言模型攻擊的倫理
訓練數據提取攻擊在應用于公眾可用但訓練中使用的數據集不可用的模型時最有可能造成傷害。然而,由于在這樣的數據集上進行這項研究可能會產生有害的后果,我們改為對GPT-2進行概念驗證訓練數據提取攻擊,GPT-2是一種由 OpenAI 開發(fā)的大型公開可用語言模型,僅使用公共數據進行訓練。雖然這項工作特別關注 GPT-2,但結果適用于理解大型語言模型上可能存在的隱私威脅。
與其他與隱私和安全相關的研究一樣,在實際執(zhí)行此類攻擊之前考慮此類攻擊的道德規(guī)范很重要。為了最大限度地降低這項工作的潛在風險,這項工作中的訓練數據提取攻擊是使用公開可用的數據開發(fā)的。此外,GPT-2 模型本身在 2019 年由 OpenAI 公開,用于訓練 GPT-2 的訓練數據是從公共互聯(lián)網收集的,任何遵循GPT中記錄的數據收集過程的人都可以下載-2 紙。
此外,根據負責任的計算機安全披露規(guī)范,我們會跟蹤提取了 PII 的個人,并在發(fā)布對這些數據的引用之前獲得了他們的許可。此外,在這項工作的所有出版物中,我們已經編輯了任何可能識別個人身份的個人識別信息。我們還在 GPT-2 的分析中與 OpenAI 密切合作。
訓練數據提取攻擊
根據設計,語言模型使得生成大量輸出數據變得非常容易。通過用隨機短語為模型播種,該模型可以生成數百萬個延續(xù),即完成句子的可能短語。大多數情況下,這些延續(xù)將是合理文本的良性字符串。例如,當被要求預測字符串“ Mary had a little… ”的連續(xù)性時,語言模型將有很高的置信度認為下一個標記是“ lamb ”這個詞。但是,如果某個特定的訓練文檔碰巧多次重復字符串“ Mary had a little wombat ”,模型可能會改為預測該短語。
訓練數據提取攻擊的目標是篩選來自語言模型的數百萬個輸出序列,并預測記住哪些文本。為了實現這一點,我們的方法利用了這樣一個事實,即模型往往對直接從訓練數據中捕獲的結果更有信心。這些成員推理攻擊使我們能夠通過檢查模型對特定序列的置信度來預測結果是否用于訓練數據。
這項工作的主要技術貢獻是開發(fā)了一種高精度推斷成員資格的方法,以及以鼓勵輸出記憶內容的方式從模型中采樣的技術。我們測試了許多不同的采樣策略,其中最成功的一種生成以各種輸入短語為條件的文本。然后我們比較兩種不同語言模型的輸出。當一個模型對序列有很高的置信度,而另一個(同樣準確的)模型對序列的置信度較低時,很可能第一個模型已經記住了數據。
結果
在 GPT-2 語言模型的 1800 個候選序列中,我們從公共訓練數據中提取了 600 多個記憶,總數受限于需要手動驗證。記住的示例涵蓋了廣泛的內容,包括新聞標題、日志消息、JavaScript 代碼、PII 等。盡管這些示例在訓練數據集中很少出現,但它們中的許多示例都被記住了。例如,對于我們提取的許多 PII 樣本,僅在數據集中的單個文檔中找到。但是,在大多數情況下,原始文檔包含 PII 的多個實例,因此模型仍將其作為高似然文本進行學習。
最后,我們還發(fā)現語言模型越大,它就越容易記住訓練數據。例如,在一項實驗中,我們發(fā)現 15 億個參數的 GPT-2 XL 模型比 1.24 億個參數的 GPT-2 Small 模型記憶的信息多 10 倍。鑒于研究界已經訓練了 10 到 100 倍大的模型,這意味著隨著時間的推移,需要做更多的工作來監(jiān)控和緩解越來越大的語言模型中的這個問題。
經驗教訓
雖然我們專門演示了對 GPT-2 的這些攻擊,但它們顯示了所有大型生成語言模型中的潛在缺陷。這些攻擊是可能的,這一事實對使用這些類型模型的機器學習研究的未來產生了重要影響。
幸運的是,有幾種方法可以緩解這個問題。最直接的解決方案是確保模型不會在任何可能有問題的數據上進行訓練。但這在實踐中很難做到。
差分隱私 的使用允許對數據集進行訓練,而無需透露單個訓練示例的任何細節(jié),是訓練具有隱私的機器學習模型的最有原則的技術之一。在 TensorFlow 中,這可以通過使用tensorflow/privacy 模塊(或類似的 PyTorch 或 JAX)來實現,該模塊是現有優(yōu)化器的直接替代品。即使這樣也會有限制,并且不會阻止對重復次數足夠多的內容的記憶。如果這是不可能的,我們建議至少測量發(fā)生了多少記憶,以便采取適當的行動。
語言模型繼續(xù)展示出巨大的實用性和靈活性——然而,與所有創(chuàng)新一樣,它們也可能帶來風險。負責任地發(fā)展它們意味著主動識別這些風險并開發(fā)減輕它們的方法。我們希望這項突出大語言建模當前弱點的努力將提高更廣泛的機器學習社區(qū)對這一挑戰(zhàn)的認識,并激勵研究人員繼續(xù)開發(fā)有效的技術來訓練模型,減少記憶。