













模型泛化不必隨機訓練全批量GD媲美SGD,網友:計算成本負擔不起
近來機器學習模型呈現出一種向大模型發展的趨勢,模型參數越來越多,但依然具有很好的泛化性能。一些研究者認為泛化性能得益于隨機梯度下降算法(SGD)所帶來的隨機噪聲。但最近一篇 ICLR 2022 的投稿《Stochastic Training is Not Necessary for Generalization》通過大量實驗證實全批量的梯度下降算法(GD)可以達到與 SGD 不相上下的測試準確率,且隨機噪聲所帶來的隱式正則化效應可以由顯式的正則化替代。

論文地址:https://arxiv.org/pdf/2109.14119.pdf
該論文隨即在社區內引發了一些討論,有人質疑論文的含金量,覺得個例不具代表性:
也有人表示這篇論文就像一篇調查報告,提出的觀點和證明過程并無新意:

圖源:知乎用戶 @Summer Clover
雖然內容有些爭議,但從標題上看,這篇論文應該包含大量論證,下面我們就來看下論文的具體內容。
隨機訓練對泛化并不是必需的
隨機梯度下降算法 (SGD) 是深度神經網絡優化的支柱,至少可以追溯 1998 年 LeCun 等人的研究。隨機梯度下降算法成功的一個核心原因是它對大型數據集的高效——損失函數梯度的嘈雜估計通常足以改進神經網絡的參數,并且在整個訓練集上可以比全梯度更快地進行計算。
人們普遍認為,隨機梯度下降 (SGD) 的隱式正則化是神經網絡泛化性能的基礎。然而該研究證明非隨機全批量訓練可以在 CIFAR-10 上實現與 SGD 相當的強大性能。基于此,該研究使用調整后的超參數,并表明 SGD 的隱式正則化可以完全被顯式正則化取代。研究者認為這說明:嚴重依賴隨機采樣來解釋泛化的理論是不完整的,因為在沒有隨機采樣的情況下仍然可以得到很好的泛化性能。并進一步說明:深度學習可以在沒有隨機性的情況下取得成功。此外,研究者還表示,全批量訓練存在感知難度主要是因為:優化特性和機器學習社區為小批量訓練調整優化器和超參數所花費的時間和精力不成比例。
具有隨機數據增強的全批量 GD
SGD 相對于 GD 有兩個主要優勢:首先,SGD 的優化過程在穩定性和超出臨界批量大小的收斂速度方面表現出質的飛躍。其次,有研究表明,小批量上由步長較大的 SGD 引起的隱式偏差可以用等式(5)和等式(7)中導出的顯式正則化代替。
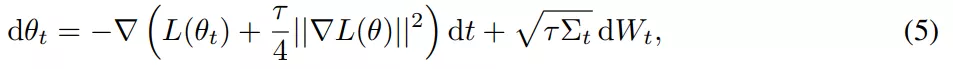
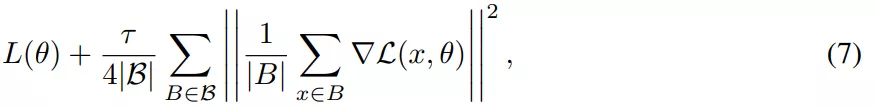
該研究對假設進行了實證研究,試圖建立訓練,使得在沒有來自小批量的梯度噪聲的情況下也能實現強泛化,核心目標是實現全批量性能。因此該研究在 CIFAR-10 上訓練了一個用于圖像分類的 ResNet 模型進行實驗。
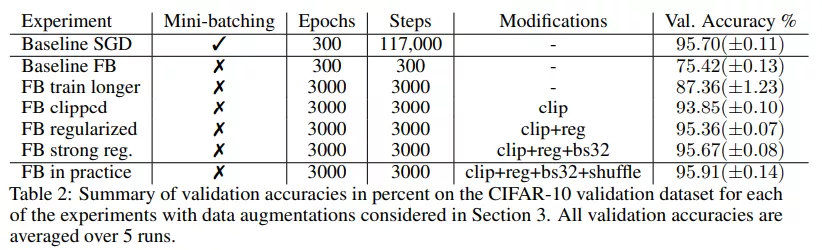
對于基線 SGD ,該研究使用隨機梯度下降進行訓練、批大小為 128 、 Nesterov 動量為 0.9、權重衰減為 0.0005。
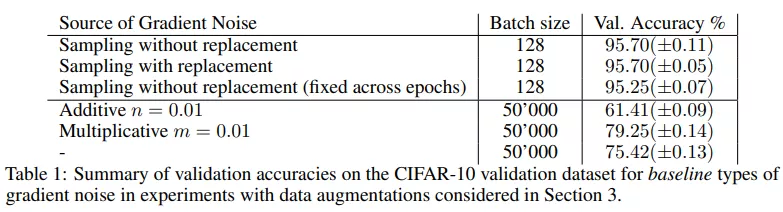
小批量 SGD 的驗證準確率達到了 95.70%(±0.05)。小批量 SGD 提供了一個強大的基線,在很大程度上是獨立于小批量處理的。如下表 1 所示,在有替換采樣時也達到相同的準確率 95.70%。在這兩種情況下,隨機小批量處理引起的梯度噪聲都會導致很強的泛化。
然后,該研究將同樣的設置用于全批量梯度下降。用全批量替換小批量,并累積所有小批量梯度。為了排除批歸一化帶來的影響,該研究仍然在批大小為 128 的情況下計算批歸一化,在整個訓練過程中將數據點分配給保持固定的一些塊,使得批歸一化不會引入隨機性。與其他大批量訓練的研究一致,在這些設置下應用全批量梯度下降的驗證準確率僅為 75.42%(±00.13),SGD 和 GD 之間的準確率差距約為 20%。
該研究注意到,通過注入簡單形式的梯度噪聲不容易彌補這一差距,如下表 1 所示。接下來的實驗該研究努力縮小了全批量和小批量訓練之間的差距。
由于全批量訓練不穩定,因此該研究在超過 400 step(每一個 step 是一個 epoch)的情況下將學習率從 0.0 提升到 0.4 以保持穩定,然后在 3000 step 的情況下通過余弦退火衰減到 0.1。
實驗表明在對訓練設置進行了一些修改后,全批量梯度下降性能提高到了 87.36%(±1.23),比基線提高了 12%,但仍與 SGD 的性能相去甚遠。表 2 中總結了驗證分數:
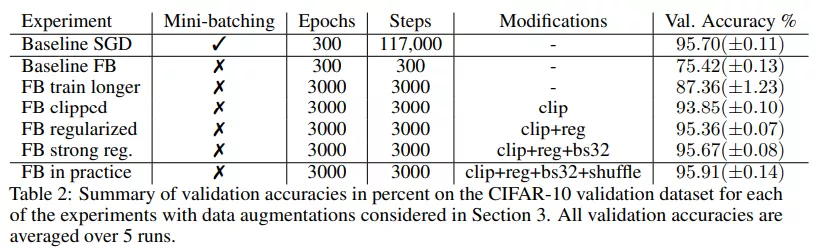
該研究用顯式正則化來彌補這種差距,并再次增加了初始學習率。在第 400 次迭代時將學習率增加到 0.8,然后在 3000 step 內衰減到 0.2。在沒有正則化因子的情況下,使用該學習率和 clipping 操作進行訓練,準確率為 93.75%(±0.13)。當加入正則化因子時,增大學習率的方法顯著提高了性能,最終與 SGD 性能相當。
總體而言,該研究發現經過所有修改后,全批量(帶有隨機數據增強)和 SGD 的性能相當,驗證準確率顯著超過 95%。
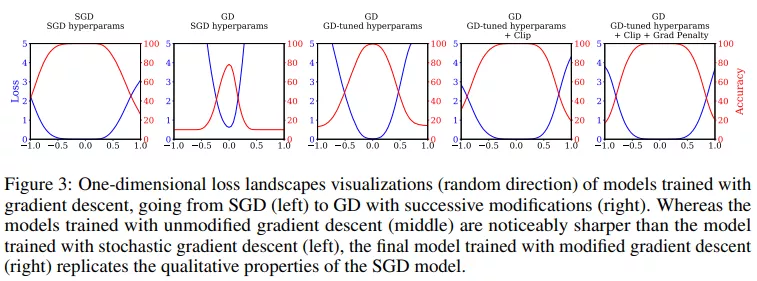
該研究還評估了一系列具有完全相同超參數的視覺模型。ResNet-50、ResNet-152 和 DenseNet-121 的結果見表 3,該研究發現所提方法也同樣適用于這些模型。
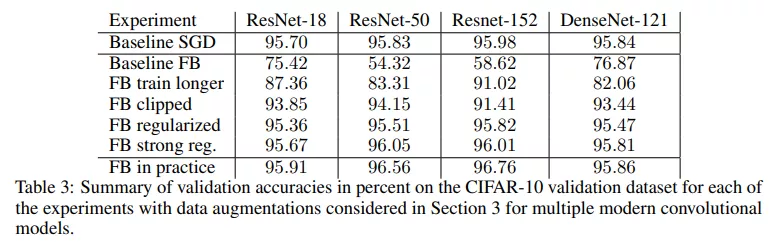
非隨機設置下的全批量梯度下降
如果全批量實驗能夠捕捉小批量 SGD 的影響,那么隨機數據增強又會給梯度噪聲帶來什么影響?研究者又進行了以下實驗。
無數據增強:如果不使用任何數據增強方法,并且重復之前的實驗,那么經過 clipping 和正則化的 GD 驗證準確率為 89.17%,顯著優于默認超參數的 SGD(84.32%(±1.12)),并且與新調整超參數的 SGD(90.07%(±0.48)) 性能相當,如下表 4 所示。

為了相同的設置下分析 GD 和 SGD,探究數據增強(不含隨機性)的影響,該研究使用固定增強的 CIFAR-10 數據集替換隨機數據增強,即在訓練前為每個數據點采樣 N 個隨機數據進行數據增強。這些樣本在訓練期間保持固定,也不會被重新采樣,從而產生放大 N 倍的 CIFAR-10 數據集。
最后,該研究得出結論:在沒有小批量、shuffling 以及數據增強產生的梯度噪聲后,模型也完全可以在沒有隨機性的情況下達到 95% 以上的驗證準確率。這表明,通過數據增強引入的噪聲可能不會影響泛化,并且也不是泛化所必需的。
引發討論
這篇論文在社區內引發了大家的討論,有人從實驗的角度分析了一下論文的價值。
該論文把 ResNet18 用 SGD 在 CIFAR-10 訓練 300 個 epoch 作為基線,并在結果部分展示了每一個 trick 分別提升了多少準確率。
但是這幾個 trick 太常見了,反而讓人質疑真的如此有效嗎?有網友指出「train longer」這個 trick 應該只在 CIFAR-10 上這么有效,而 gradient clipping 在其他數據集上甚至可能無效。

圖源:知乎用戶 @Summer Clover
看來論文中的改進可能是個例,難以代表一般情況。不過,他也在評論中指出 SGD 近似正則化項
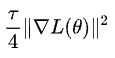
是個很有效的 trick,具備很好的理論基礎,但是計算成本可能會翻倍:

圖源:知乎用戶 @Summer Clover
還有網友指出,這篇論文的研究結果實際用途很有限,因為全批量設置的成本太高了,不是普通開發者負擔得起的。相比之下,SGD 訓練魯棒性強,泛化性更好,也更省一次迭代的計算資源。
看來該論文進行了一些理論和實驗驗證,但正如網友提議的:能否在其他數據集上進行更多的實驗來驗證其結論?

對此,你怎么看?













