高并發 HTTP 請求實踐
當今,正處于互聯網高速發展的時代,每個人的生活都離不開互聯網,互聯網已經影響了每個人生活的方方面面。我們使用淘寶、京東進行購物,使用微信進行溝通,使用美圖秀秀進行拍照美化等等。而這些每一步的操作下面,都離不開一個技術概念HTTP(Hypertext Transfer Protocol,超文本傳輸協議)。
舉個:chestnut:,當我們打開京東APP的時候,首先進入的是開屏頁面,然后進入首頁。在開屏一般是廣告,而首頁是內容相關,包括秒殺,商品推薦以及各個tag頁面,而各個tag也有其對應的內容。當我們在進入開屏之前或者開屏之后(這塊依賴于各個app的技術實現),會向后端服務發送一個http請求,這個請求會帶上該頁面廣告位信息,向后端要內容,后端根據廣告位的配置,挑選一個合適的廣告或者推薦商品返回給APP端進行展示。在這里,為了描述方便,后端當做一個簡單的整體,實際上,后端會有非常復雜的業務調度,比如獲取用戶畫像,廣告定向,獲取素材,計算坐標,返回APP,APP端根據坐標信息,下載素材,然后進行渲染,從而在用戶端進行展示,這一切都是秒級甚至毫秒級響應,一個高效的HTTP Client在這里就顯得尤為重要,本文主要從業務場景來分析,如何實現一個高效的HTTP Client。
一、概念
當我們需要模擬發送一個http請求的時候,往往有兩種方式:
1、通過瀏覽器
2、通過 curl 命令進行發送請求
如果我們在大規模高并發的業務中,如果使用curl來進行http請求,其效果以及性能是不能滿足業務需求的,這就引入了另外一個概念 libcurl。
二、實現
在開始實現client發送http請求之前,我們先理解兩個概念:
同步請求
異步請求
客戶端把請求發送給服務器之后,不會等待服務器返回,而是去做其他事情,待服務器處理完成之后,通知客戶端該事件已經完成,客戶端在獲取到通知后,將服務器處理后的結果返回給調用方。
通過這倆概念,就能看出,異步在實現上,要比同步復雜的多。同步,即我們簡單的等待處理結果,待處理結果完成之后,再返回調用方。而對于異步,往往在實現上,需要各種回調機制,各種通知機制,即在處理完成的時候,需要知道是哪個任務完成了,從而通知客戶端去處理該任務完成后剩下的邏輯。
下面,我們將從代碼實現的角度,來更深一步的理解libcurl在實現同步和異步請求操作上的區別,從而更近異步的了解同步和異步的實現原理。
同步
使用libcurl完成同步http請求,原理和代碼都比較簡單,主要是分位以下幾個步驟:
1、初始化easy handle
2、在該easy handle上設置相關參數,在本例中主要有以下幾個參數
-
CURLOPT_URL,即請求的url
-
CURLOPT_WRITEFUNCTION,即回調函數,將http server返回數據寫入對應的地方
-
CURLOPT_FOLLOWLOCATION,是否獲取302跳轉后的內容
-
CURLOPT_POSTFIELDSIZE,此次發送的數據大小
-
CURLOPT_POSTFIELDS,此次發送的數據內容
-
更多的參數設置,請參考libcurl官網
3、 curl_easy_perform,調用該函數發送http請求,并同步等待返回結果
4、 curl_easy_cleanup,釋放步驟一中申請的easy handle資源
代碼實現(easy_curl.cc)
編譯
結果
異步
接 觸過網絡編程的讀者,都或多或少的了解多路復用的原理。 IO多路復用在Linux下包括了三種, select 、 poll 、 epoll ,抽象來看,他們功能是類似的,但具體細節各有不同:首先都會對一組文件描述符進行相關事件的注冊,然后阻塞等待某些事件的發生或等待超時。
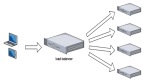
在使用Libcurl進行異步請求,從上層結構來看,簡單來說,就是對easy handle 和 multi 接口的結合使用。其中,easy handle底層也是一個socket,multi接口,其底層實現也用的是epoll,那么我們如何使用easy handle和multi接口,來實現一個高性能的異步http 請求client呢?下面我們將使用代碼的形式,使得讀者能夠進一步了解其實現機制。
multi 接口的使用是在easy 接口的基礎之上,將easy handle放到一個隊列中(multi handle),然后并發發送請求。與easy 接口相比,multi接口是一個異步的,非阻塞的傳輸方式。
multi接口的使用,主要有以下幾個步驟:
-
curl_multi _init初始化一個multi handler對象
-
初始化多個easy handler對象,使用curl_easy_setopt進行相關設置
-
調用curl_multi _add_handle把easy handler添加到multi curl對象中
-
添加完畢后執行curl_multi_perform方法進行并發的訪問
-
訪問結束后curl_multi_remove_handle移除相關easy curl對象,先用curl_easy_cleanup清除easy handler對象,最后curl_multi_cleanup清除multi handler對象。
http_request.h
http_request.cc
main.cc
至此,我們已經可以使用libcurl來實現并發發送http請求,當然這個只是一個簡單異步實現功能,更多的功能,還需要讀者去使用libcurl中的其他功能去實現,此處留給讀者一個問題(這個問題,也是筆者項目中使用的一個功能,該項目已經線上穩定運行4年,日請求量在20E ),業務需要,某一個請求需要并發發送給指定的幾家,即該請求,需要并發發送給幾個http server,在一個特定的超時時間內,獲取這幾個http server的返回內容,并進行處理,那么這種功能應該如何使用libcurl來實現呢?透露下,可以使用libcurl的另外一個參數CURLOPT_PRIVATE。
三、性能對比
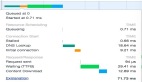
至此,我們已經基本完成了 高性能http 并發功能的設計,那么到底性能如何呢?筆者從 以下幾個角度來做了測試:
1、串行發送同步請求
2、多線程情況下,發送同步請求(此處線程為4個,筆者測試的服務器為4C)
3、使用multi接口
4、使用multi接口,并復用其對應的easy handle
5、使用dns cache(對easy handle設置CURLOPT_DNS_CACHE_TIMEOUT),即不用每次都進行dns解析
|
方法 |
平均耗時(ms) |
最大耗時(ms) |
|
串行 同步 |
21.381 |
30.617 |
|
多線程同步 |
4.331 |
16.751 |
|
multi接口 |
1.376 |
11.974 |
|
multi接口 連接復用 |
0.352 |
0.748 |
|
multi 接口使用dns cache |
0 .381 |
0.731 |
四、一點心得
libcurl是一個高性能,較易用的HTTP client,在使用其直接,一定要對其接口功能進行詳細的了解,否則很容易入坑,猶記得在18年中的時候,上 線了某一個功能,會偶現coredump(在上線之前,也進行了大量的性能測試,都沒有出現過一次coredump),為了分析這個原因,筆者將服務的代碼一直精簡精簡,然后模擬測試,縮小coredump定位范圍,最終發現,只有在超時的時候,才會導致coredump,這就說明了為什么測試環境沒有coredump,而線上會產生coredump,這是因為線上的超時時間設置的是5ms,而測試環境超時時間是20ms,這就基本把原因定位到超時導致的coredump。
然后,分析libcurl源碼,發送時一個libcurl的參數設置導致coredump,至此,筆者耗費了23個小時,問題才得以解決。