如何使用 Streamlit 和 Python 構建數據科學應用程序?
譯文【51CTO.com快譯】Web 應用程序仍然是數據科學家向用戶展示他們的數據科學項目的有用工具。由于我們可能沒有 Web 開發技能,因此我們可以使用 Streamlit 等開源 Python 庫在短時間內輕松開發 Web 應用程序。
1. Streamlit 簡介
Streamlit 是一個開源 Python 庫,用于為數據科學和機器學習項目創建和共享 Web 應用程序。該庫可以幫助您使用幾行代碼在幾分鐘內創建和部署數據科學解決方案。
Streamlit 可以與數據科學中使用的其他流行的 Python 庫無縫集成,例如 NumPy、Pandas、Matplotlib、Scikit-learn 等等。
注意:Streamlit 使用 React 作為前端框架來在屏幕上呈現數據。
2. 安裝和設置
Streamlit 在您的機器中需要 python >= 3.7 版本。
要安裝 streamlit,您需要在終端中運行以下命令。
pip install streamlit
您還可以使用以下命令檢查您機器上安裝的版本。
streamlit --version
流線型,版本 1.1.0
成功安裝streamlit后,您可以通過在終端中運行以下命令來測試庫。
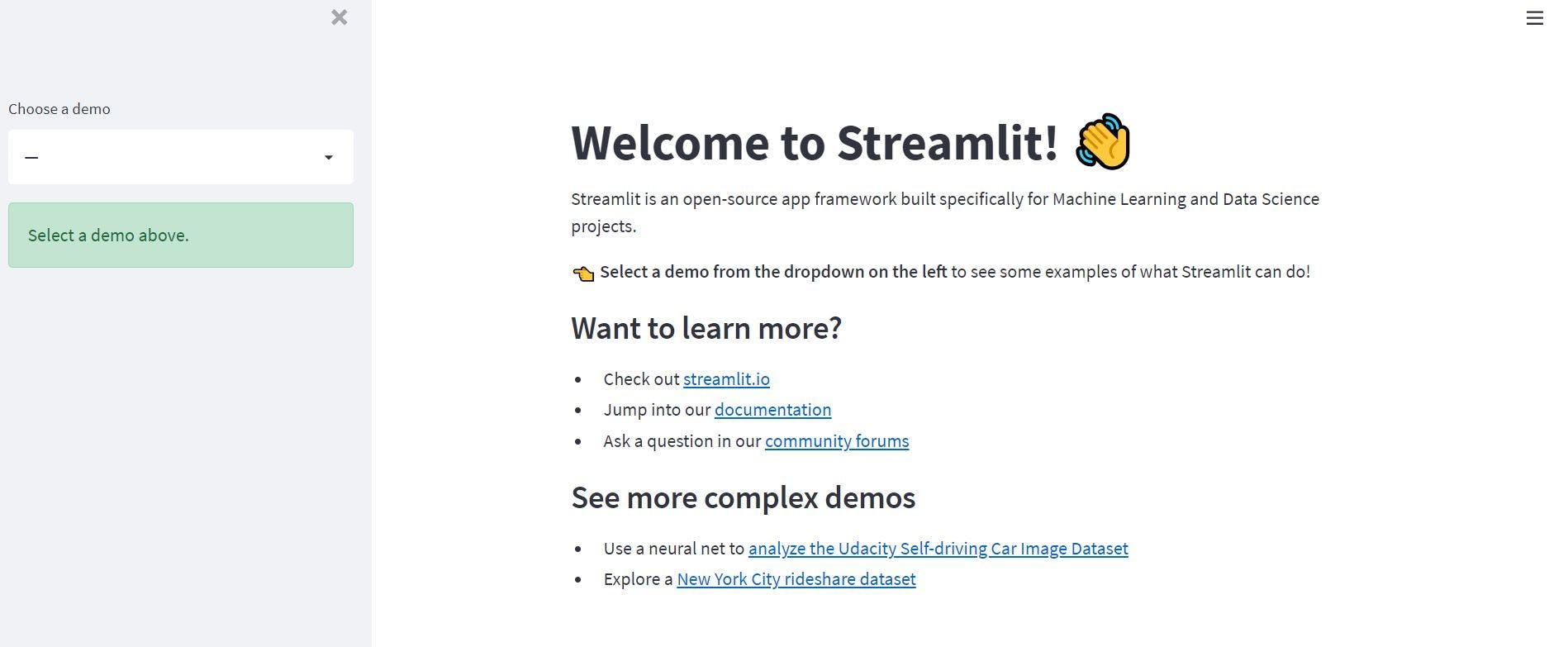
streamlit hello
Streamlit 的 Hello 應用程序將出現在您的網絡瀏覽器的新選項卡中。
? ??
??
這表明一切運行正常,我們可以繼續使用 Streamlit 創建我們的第一個 Web 應用程序。
3. 開發 Web 應用程序
在這一部分,我們將部署經過訓練的 NLP 模型來預測電影評論的情緒(正面或負面)。您可以在[此處](https://hackernoon.com/how-to-build-and-deploy-an-nlp-model-with-fastapi-part-1-n5w35cj?ref=hackernoon.com)訪問源代碼和數據集。
數據科學 Web 應用程序將顯示一個文本字段以添加電影評論和一個簡單按鈕以提交評論并進行預測。
導入重要包
第一步是創建一個名為 app.py 的 python 文件,然后為 streamlit 和訓練的 NLP 模型導入所需的 python 包。
# import packages import streamlit as st import os import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer # text preprocessing modules from string import punctuation # text preprocessing modules from nltk.tokenize import word_tokenize import nltk from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer import re # regular expression import joblib import warnings warnings.filterwarnings("ignore") # seeding np.random.seed(123) # load stop words stop_words = stopwords.words("english")
清理評論的功能
評論可能包含我們在進行預測時不需要的不必要的單詞和字符。
我們將通過刪除停用詞、數字和標點符號來清理評論。然后我們將使用 NLTK 包中的詞形還原過程將每個單詞轉換為其基本形式。
該**text_cleaning()**函數將處理所有必要的步驟進行預測之前清理我們的審查。
# function to clean the text @st.cache def text_cleaning(text, remove_stop_words=True, lemmatize_words=True): # Clean the text, with the option to remove stop_words and to lemmatize word # Clean the text text = re.sub(r"[^A-Za-z0-9]", " ", text) text = re.sub(r"\'s", " ", text) text = re.sub(r"http\S+", " link ", text) text = re.sub(r"\b\d+(?:\.\d+)?\s+", "", text) # remove numbers # Remove punctuation from text text = "".join([c for c in text if c not in punctuation]) # Optionally, remove stop words if remove_stop_words: texttexttext = text.split() text = [w for w in text if not w in stop_words] text = " ".join(text) # Optionally, shorten words to their stems if lemmatize_words: texttexttext = text.split() lemmatizer = WordNetLemmatizer() lemmatized_words = [lemmatizer.lemmatize(word) for word in text] text = " ".join(lemmatized_words) # Return a list of words return text
預測功能
名為**make_prediction()**的 python 函數將執行以下任務。
1. 收到審查并清理它。
2. 加載經過訓練的 NLP 模型。
3. 做個預測。
4. 估計預測的概率。
5. 最后,它將返回預測的類別及其概率。
# functon to make prediction @st.cache def make_prediction(review): # clearn the data clean_review = text_cleaning(review) # load the model and make prediction model = joblib.load("sentiment_model_pipeline.pkl") # make prection result = model.predict([clean_review]) # check probabilities probas = model.predict_proba([clean_review]) probability = "{:.2f}".format(float(probas[:, result])) return result, probability
**注意:**如果訓練后的 NLP 模型預測為 1,則表示 Positive,如果預測為 0,則表示 Negative。
**創建應用標題和描述**
您可以使用 streamlit 中的 title() 和 write() 方法創建 Web 應用程序的標題及其描述。
# Set the app title st.title("Sentiment Analyisis App") st.write( "A simple machine laerning app to predict the sentiment of a movie's review" )
要顯示 Web 應用程序,您需要在終端中運行以下命令。
streamlit run app.py
然后您將看到 Web 應用程序自動在您的 Web 瀏覽器中彈出,或者您可以使用創建的本地 URL http://localhost:8501。
? ??
??
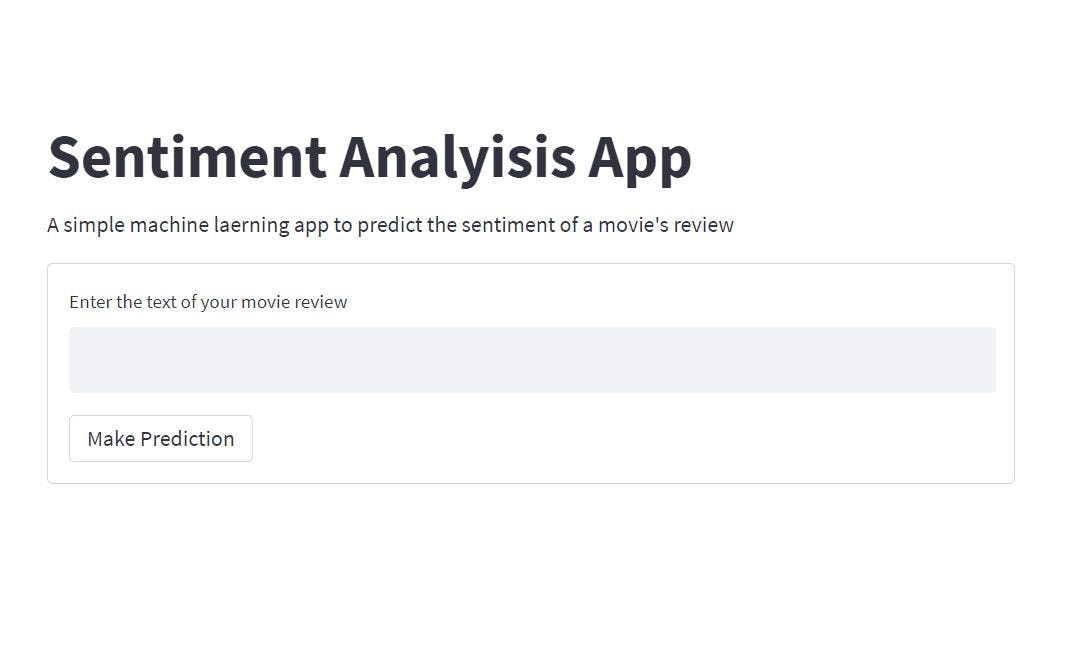
創建表格以接收電影評論
下一步是使用 streamlit 創建一個簡單的表單。表單將顯示一個文本字段來添加您的評論,在文本字段下方,它將顯示一個簡單的按鈕來提交添加的評論,然后進行預測。
# Declare a form to receive a movie's review form = st.form(key="my_form") review = form.text_input(label="Enter the text of your movie review") submit = form.form_submit_button(label="Make Prediction")
現在,您可以在 Web 應用程序上看到該表單。
? ??
??
進行預測并顯示結果
我們的最后一段代碼是在用戶添加電影評論并單擊表單部分上的“進行預測”按鈕時進行預測并顯示結果。
單擊按鈕后,Web 應用程序將運行**make_prediction()**函數并在瀏覽器中的 Web 應用程序上顯示結果。
if submit: # make prediction from the input text result, probability = make_prediction(review) # Display results of the NLP task st.header("Results") if int(result) == 1: st.write("This is a positive review with a probabiliy of ", probability) else: st.write("This is a negative review with a probabiliy of ", probability)
4. 測試 Web 應用程序
通過幾行代碼,我們創建了一個簡單的數據科學網絡應用程序,它可以接收電影評論并預測它是正面評論還是負面評論。
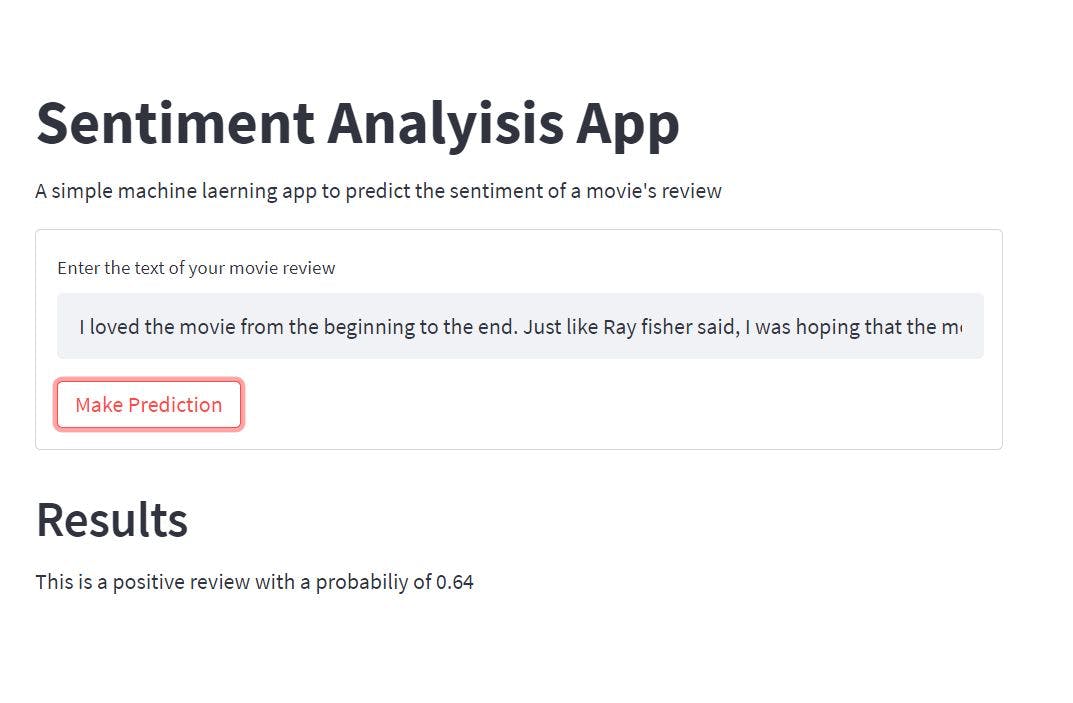
要測試 Web 應用程序,請通過添加您選擇的電影評論來填充文本字段。我添加了以下關于 **扎克·施奈德**2021 年上映**的正義聯盟**電影的影評。
> “我從頭到尾都很喜歡這部電影。就像雷·費舍爾說的,我希望這部電影不要結束。乞討的場景令人興奮,非常喜歡那個場景。不像電影《正義聯盟》那樣展示每個英雄最擅長自己的事情,讓我們熱愛每個角色。謝謝,扎克和整個團隊。”
然后單擊進行預測按鈕并查看結果。
? ??
??
正如您在我們創建的 Web 應用程序中看到的那樣,經過訓練的 NLP 模型預測添加的評論是**正面的**,概率為**0.64。
我建議您在我們創建的數據科學 Web 應用程序上添加另一條影評并再次測試。
5. 結論
Streamlit 提供了許多功能和組件,您可以使用它們以您想要的方式開發數據科學 Web 應用程序。您在此處學到的是來自 streamlit 的一些常見元素。
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】