Eslint 的實現原理,其實挺簡單
Eslint 是我們每天都在用的工具,我們會用它的 cli 或 api 來做代碼錯誤檢查和格式檢查,有時候也會寫一些 rule 來做自定義的檢查和修復。
雖然每天都用,但我們卻很少去了解它是怎么實現的。而了解 Eslint 的實現原理能幫助我們更好的使用它,更好的寫一些插件。
所以,這篇文章我們就通過源碼來探究下 Eslint 的實現原理吧。
Linter
Linter 是 eslint 最核心的類了,它提供了這幾個 api:
- verify // 檢查
- verifyAndFix // 檢查并修復
- getSourceCode // 獲取 AST
- defineParser // 定義 Parser
- defineRule // 定義 Rule
- getRules // 獲取所有的 Rule
SourceCode 就是指的 AST(抽象語法樹),Parser 是把源碼字符串解析成 AST 的,而 Rule 則是我們配置的那些對 AST 進行檢查的規則。這幾個 api 比較容易理解。
Linter 主要的功能是在 verify 和 verifyAndFix 里實現的,當命令行指定 --fix 或者配置文件指定 fix: true 就會調用 verifyAndFix 對代碼進行檢查并修復,否則會調用 verify 來進行檢查。
那 verify 和 fix 是怎么實現的呢?這就是 eslint 最核心的部分了:
確定 parser
我們知道 Eslint 的 rule 是基于 AST 進行檢查的,那就要先把源碼 parse 成 AST。而 eslint 的 parser 也是可以切換的,需要先找到用啥 parser:
默認是 Eslint 自帶的 espree,也可以通過配置來切換成別的 parser,比如 @eslint/babel-parser、@typescript/eslint-parser 等。
下面是 resolve parser 的邏輯:
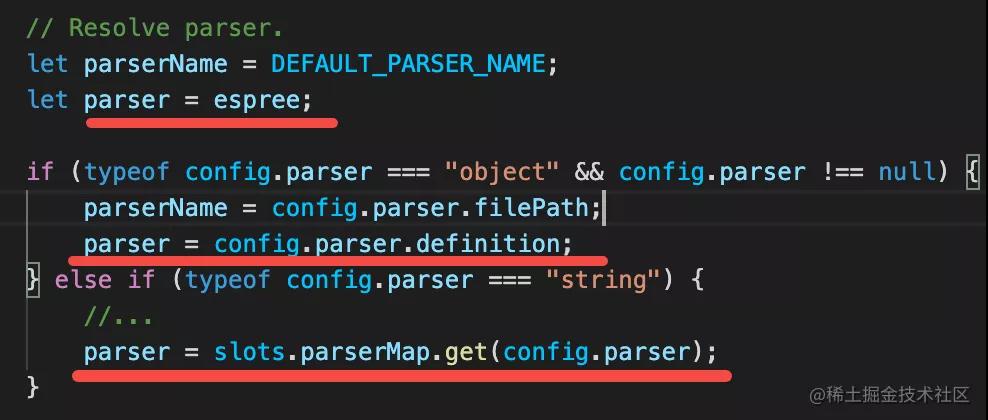
確定了 parser 之后,就是調用 parse 方法了。
parse 成 SourceCode
parser 的 parse 方法會把源碼解析為 AST,在 eslint 里是通過 SourceCode 來封裝 AST 的。后面看到 SourceCode 就是指 AST.
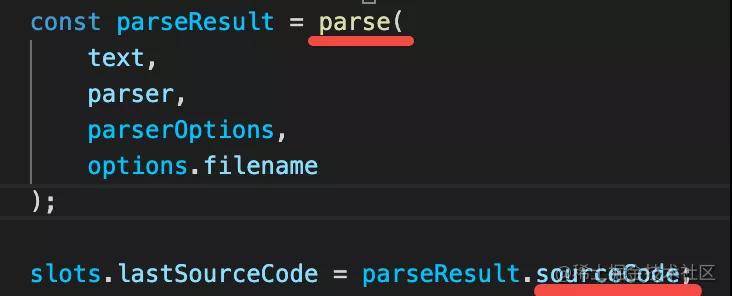
有了 AST,就可以調用 rules 對 AST 進行檢查了
調用 rule 對 SourceCode 進行檢查,獲得 lintingProblems
parse 之后,會調用 runRules 方法對 AST 進行檢查,返回結果就是 problems,也就是有什么錯誤和怎么修復的信息。
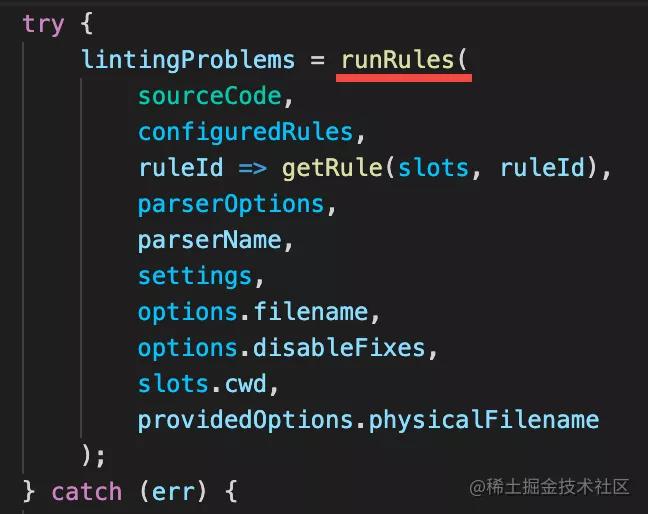
那 runRules 是怎么運行的 rule 呢?
rule 的實現如下,就是注冊了對什么 AST 做什么檢查,這點和 babel 插件很類似。
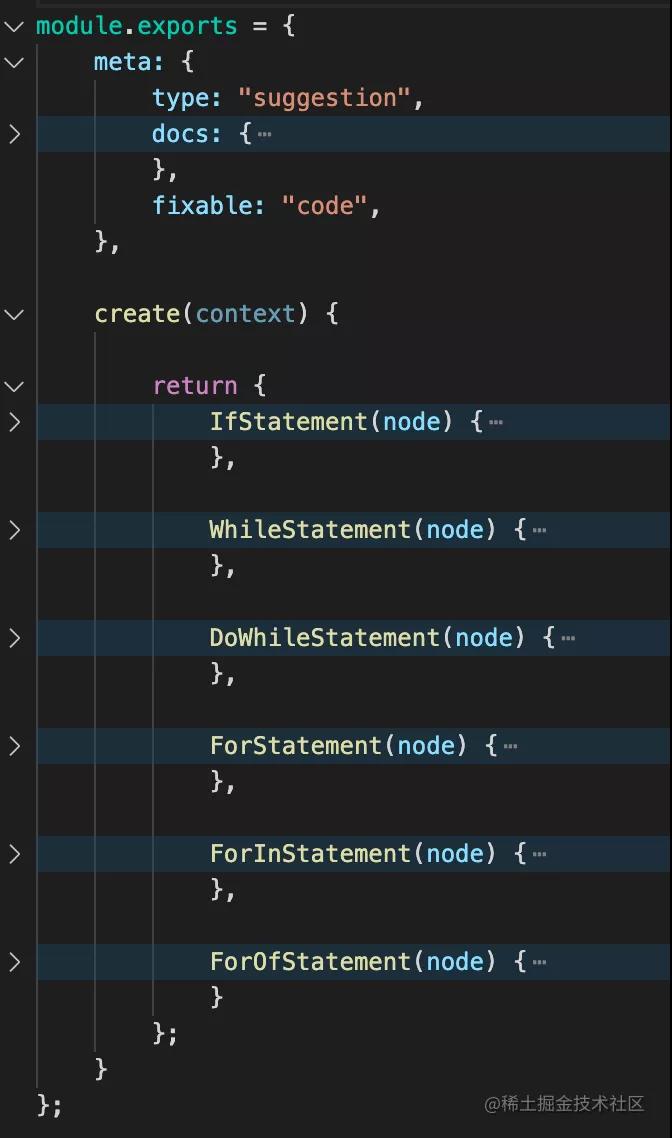
runRules 會遍歷 AST,然后遇到不同的 AST 會 emit 不同的事件。rule 里處理什么 AST 就會監聽什么事件,這樣通過事件監聽的方式,就可以在遍歷 AST 的過程中,執行不同的 rule 了。
注冊 listener:
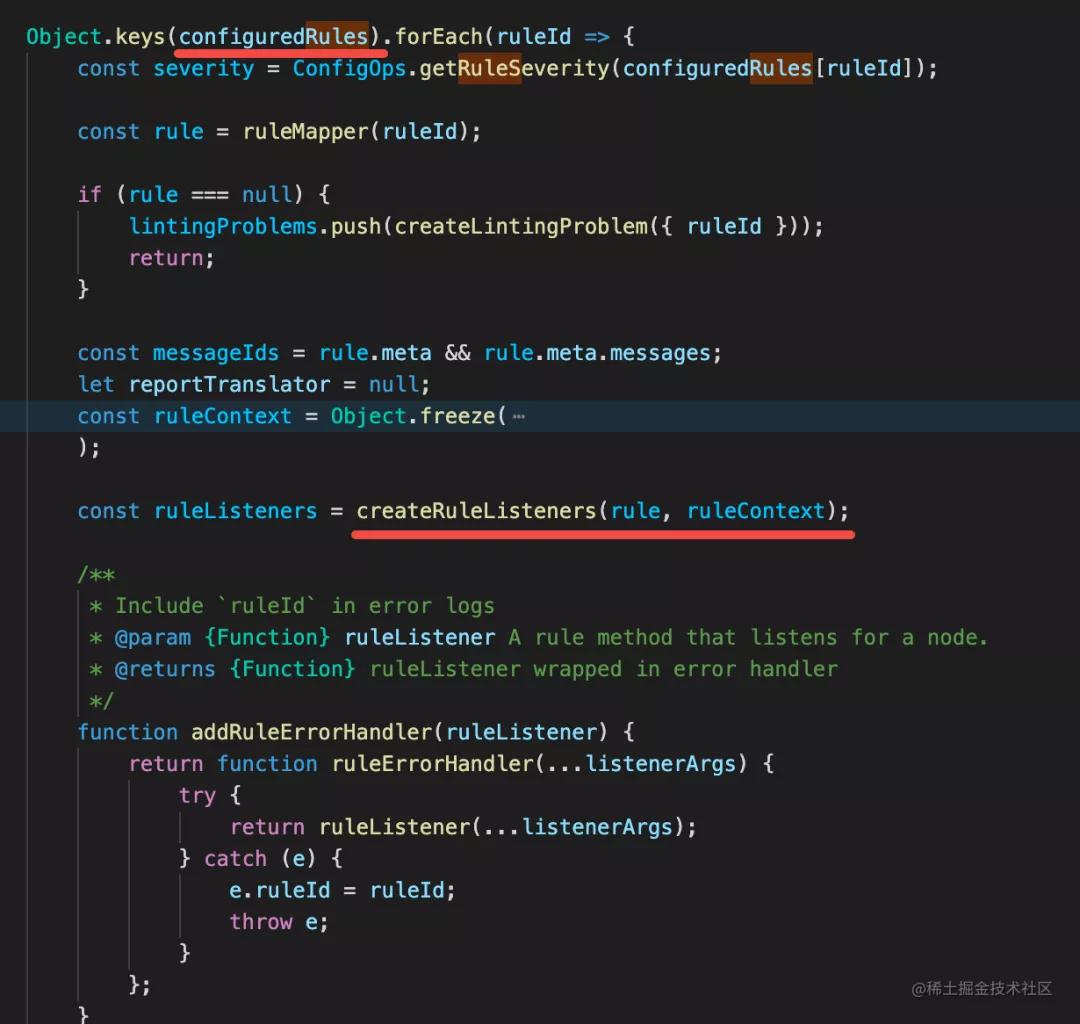
遍歷 AST,emit 不同的事件,觸發 listener:
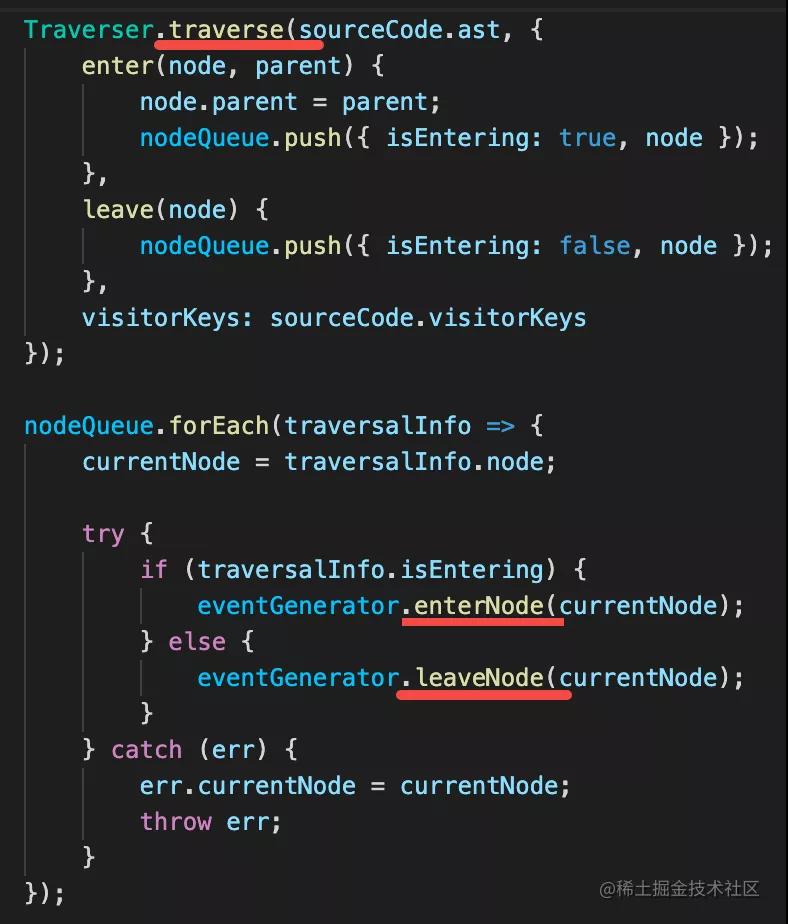
這樣,遍歷完一遍 AST,也就調用了所有的 rules,這就是 rule 的運行機制。
還有,遍歷的過程中會傳入 context,rule 里可以拿到,比如 scope、settings 等。
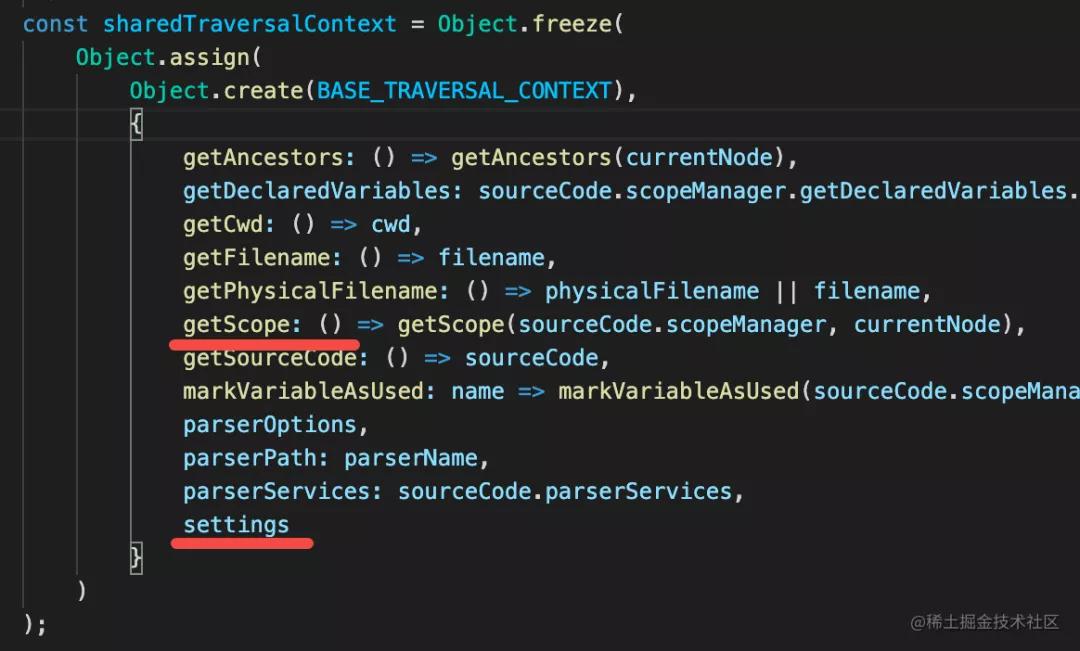
還有 ruleContext,調用 AST 的 listener 的時候可以拿到:
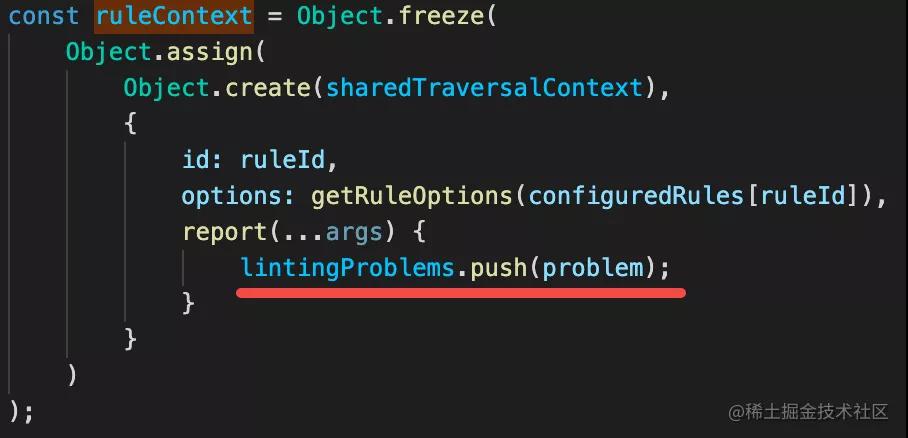
而 rule 里面就是通過這個 report 的 api 進行報錯的,那這樣就可以把所有的錯誤收集起來,然后進行打印。
這個 problem 是什么呢?
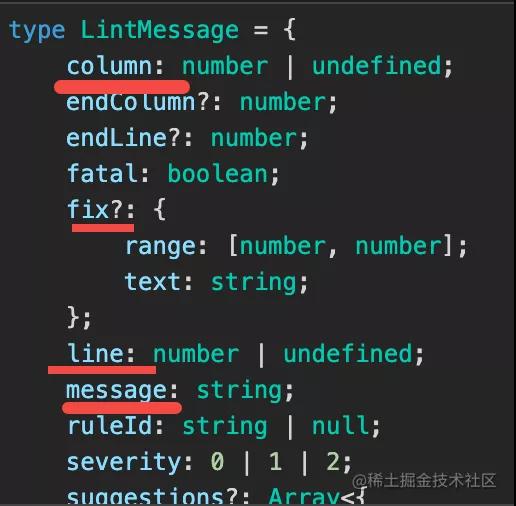
linting problem
lint problem 是檢查的結果,也就是從哪一行(line)哪一列(column)到哪一行(endLine)哪一列(endColumn),有什么錯誤(message)。
還有就是怎么修復(fix),修復其實就是 從那個下標到哪個下標(range),替換成什么文本(text)。
為什么 fix 是 range 返回和 text 這樣的結構呢?因為它的實現就是簡單的字符串替換。
通過字符串替換實現自動 fix
遍歷完 AST,調用了所有的 rules,收集到了 linting problems 之后,就可以進行 fix 了。
fix 部分的相關源碼是這樣的:
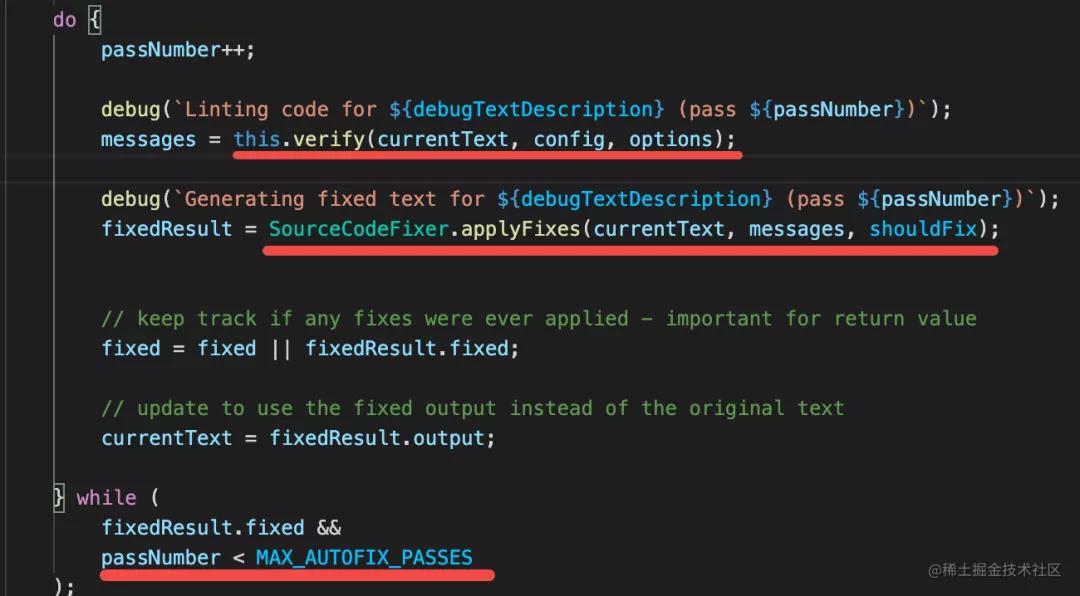
也就是 verify 進行檢查,然后根據 fix 信息自動 fix。
fix 其實就是個字符串替換:
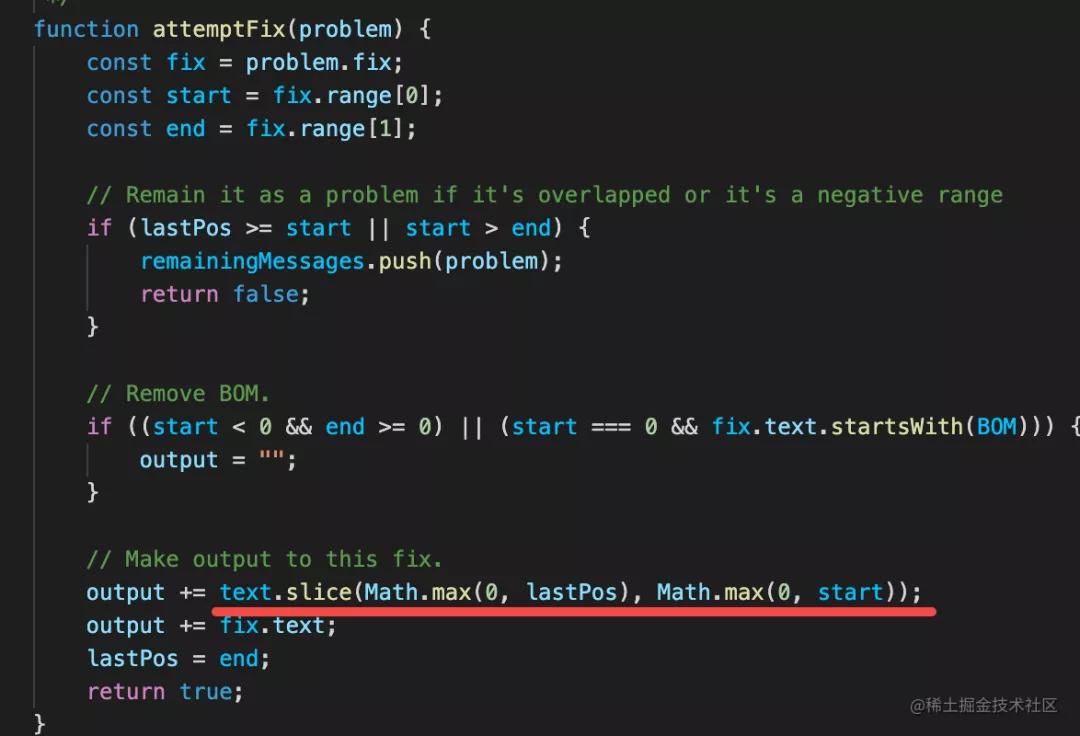
有的同學可能注意到了,字符串替換為什么要加個 while 循環呢?
因為多個 fix 之間的 range 也就是替換的范圍可能是有重疊的,如果有重疊就放到下一次來修復,這樣 while 循環最多修復 10 次,如果還有 fix 沒修復就不修了。
這就是 fix 的實現原理,通過字符串替換來實現的,如果有重疊就循環來 fix。
preprocess 和 postprocess
其實核心的 verify 和 fix 的流程就是上面那些,但是 Eslint 還支持之前和之后做一些處理。也就是 pre 和 post 的 process,這些也是在插件里定義的。
- module.exports = {
- processors: {
- ".txt": {
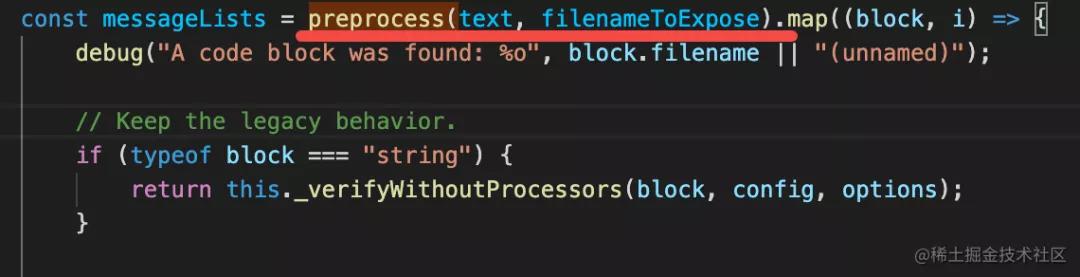
- preprocess: function(text, filename) {
- return [ // return an array of code blocks to lint
- { text: code1, filename: "0.js" },
- { text: code2, filename: "1.js" },
- ];
- },
- postprocess: function(messages, filename) {
- return [].concat(...messages);
- }
- }
- }
- };
之前的處理是把非 js 文件解析出其中的一個個 js 文件來,這和 webpack 的 loader 很像,這使得 Eslint 可以處理非 JS 文件的 lint。
之后的處理呢?那肯定是處理 problems 啊,也就是 messages,可以過濾掉一些 messages,或者做一些修改之類的。
那 preprocess 和 postprocess 是怎么實現的呢?
這個就比較簡單了,就是在 verify 之前和之后調用就行。

通過 comment directives 來過濾掉一些 problems
我們知道 eslint 還支持通過注釋來配置,比如 /* eslint-disable */ /*eslint-enable*/ 這種。
那它是怎么實現的呢?
注釋的配置是通過掃描 AST 來收集所有的配置的,這種配置叫做 commentDirective,也就是哪行那列 Eslint 是否生效。
然后在 verify 結束的時候,對收集到的 linting problems 做一次過濾即可。

上面講的這些就是 Eslint 的實現原理:
Eslint 和 CLIEngine 類
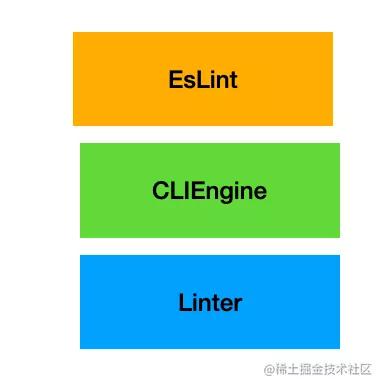
Linter 是實現核心功能的,上面我們介紹過了,但是在命令行的場景下還需要處理一些命令行參數,也就需要再包裝一層 CLIEngine,用來做文件的讀寫,命令行參數的解析。
它有 executeOnFiles 和 executeOnText 等 api,是基于 Linter 類的上層封裝。
但是 CLIEngine 并沒有直接暴露出去,而是又包裝了一層 EsLint 類,它只是一層比較好用的門面,隱藏了一些無關信息。
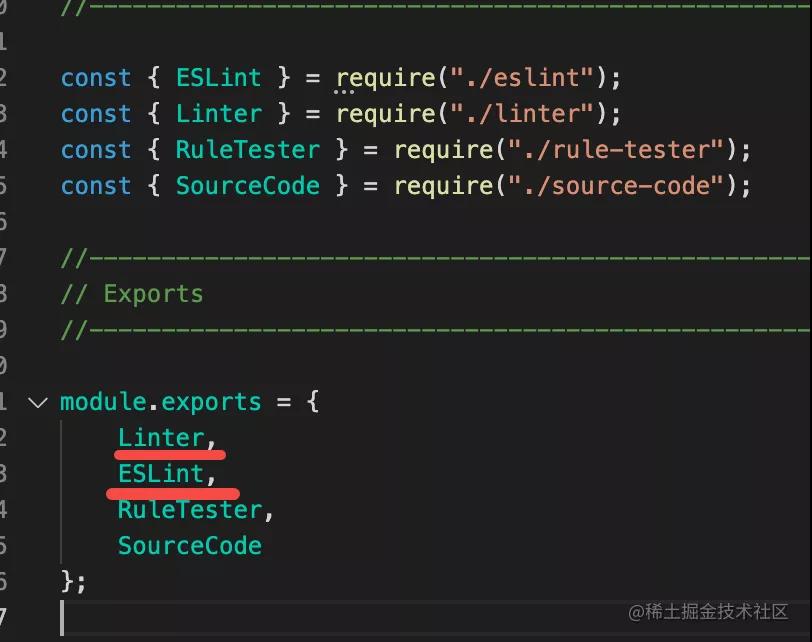
我們看下 eslint 最終暴露出來的這幾個 api:
- Linter 是核心的類,直接對文本進行 lint
- ESLint 是處理配置、讀寫文件等,然后調用 Linter 進行 lint(中間的那層 CLIEngine 并沒有暴露出來)
- SourceCode 就是封裝 AST 用的
- RuleTester 是用于 rule 測試的一些 api。
總結
我們通過源碼理清了 eslint 的實現原理:
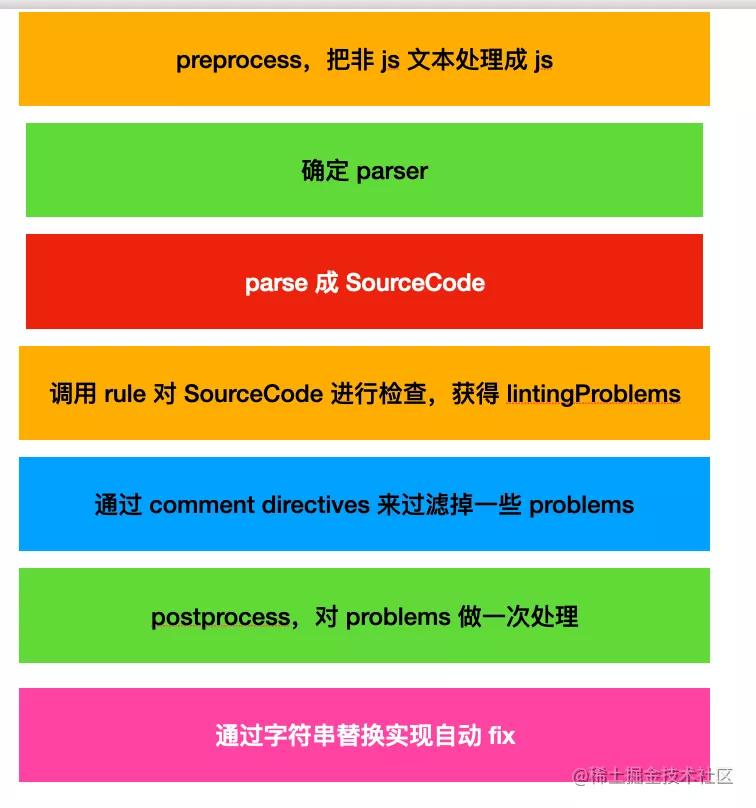
ESLint 的核心類是 Linter,它分為這樣幾步:
- preprocess,把非 js 文本處理成 js
- 確定 parser(默認是 espree)
- 調用 parser,把源碼 parse 成 SourceCode(ast)
- 調用 rules,對 SourceCode 進行檢查,返回 linting problems
- 掃描出注釋中的 directives,對 problems 進行過濾
- postprocess,對 problems 做一次處理
- 基于字符串替換實現自動 fix
除了核心的 Linter 類外,還有用于處理配置和讀寫文件的 CLIEngine 類,以及最終暴露出去的 Eslint 類。
這就是 Eslint 的實現原理,其實還是挺簡單的:
基于 AST 做檢查,基于字符串做 fix,之前之后還有 pre 與 post 的process,支持注釋來配置過濾掉一些 problems。
把這些理清楚之后,就算是源碼層面掌握了 Eslint 了。