阿里面試官:談?wù)剬?duì)Redis哈希表的理解
Hash表回顧
哈希表是一種存儲(chǔ)數(shù)據(jù)的結(jié)構(gòu),他有很多名字(鍵值對(duì)、字典、符號(hào)表、映射、關(guān)聯(lián)數(shù)組)。在哈希表中,鍵和值是一一對(duì)應(yīng)的關(guān)系,一個(gè)鍵key對(duì)應(yīng)一個(gè)值value。哈希表這個(gè)數(shù)據(jù)結(jié)構(gòu)可以通過(guò)鍵key,在O(1)時(shí)間復(fù)雜度的情況下獲得對(duì)應(yīng)的值。
由于C語(yǔ)言自己沒(méi)有內(nèi)置哈希表這一數(shù)據(jù)結(jié)構(gòu),因此Redis自己實(shí)現(xiàn)了Hash表。
哈希沖突及處理辦法
哈希表最關(guān)鍵的問(wèn)題就在于哈希沖突。即,兩個(gè)項(xiàng),經(jīng)過(guò)哈希函數(shù)計(jì)算,發(fā)現(xiàn)其對(duì)應(yīng)的存儲(chǔ)方式位置一致。對(duì)于這種情況,就需要進(jìn)行進(jìn)一步處理了。
解決哈希沖突的辦法
大家應(yīng)該背過(guò)我寫(xiě)的數(shù)據(jù)結(jié)構(gòu)與算法八股文背誦版,還記得解決Hash沖突的方法嘛。
線性探查法(開(kāi)放地址)。
這個(gè)方法的核心是:一旦碰見(jiàn)有沖突,該項(xiàng)往后順延.
來(lái)看個(gè)例子吧。
1.按hash算法,新鍵值對(duì)應(yīng)該存在箭頭所處位置,可惜該位置有值了:
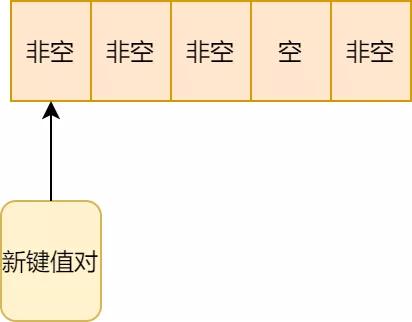
開(kāi)放地址法
2.因此需要存儲(chǔ)順延的位置:
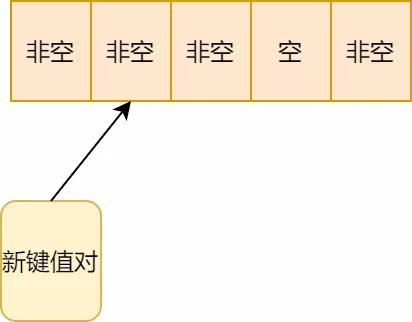
開(kāi)放地址法
3.順延位置也有值了,再往后順延
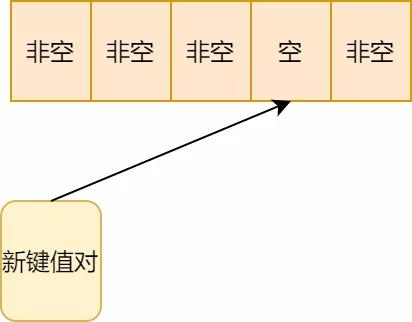
開(kāi)放地址法
4.順延位置還是有值,再往后順延,終于存儲(chǔ)上了
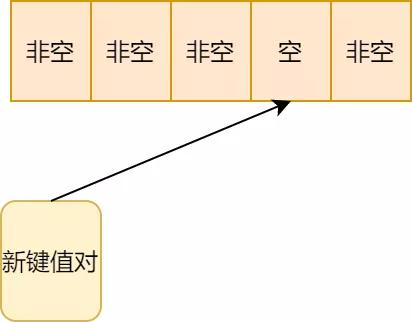
開(kāi)放地址法
鏈地址法(拉鏈法)
Redis采用的方法就是這種拉鏈法。來(lái)看下面例子。新鍵值對(duì)計(jì)算應(yīng)該存到二號(hào),二號(hào)此時(shí)已經(jīng)有一個(gè)鍵值對(duì)了。因此,直接通過(guò)鏈表的方式掛到二號(hào)鍵值對(duì)1的下面。
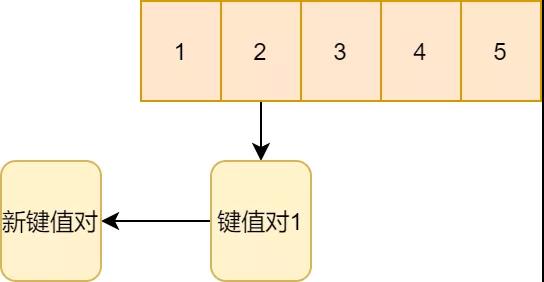
拉鏈法
對(duì)于新的鍵值對(duì)也是如此,通過(guò)鏈表的方式掛到二號(hào)鍵值對(duì)2的下面。
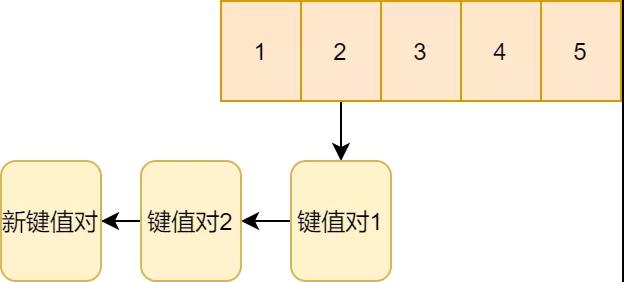
Rehash
在講rehash之前,首先需要引入一個(gè)定義:負(fù)載因子。來(lái)看一下負(fù)載因子的定義吧:
負(fù)載因子 = 散列表內(nèi)元素個(gè)數(shù)/散列表的長(zhǎng)度
如果負(fù)載因子高,就說(shuō)明哈希沖突概率大,這樣會(huì)嚴(yán)重拖慢查找效率。
如果負(fù)載因子低,就說(shuō)明這哈希表好像占用空間太多了,大部分空間都沒(méi)元素。
為了使負(fù)載因子值在合理范圍內(nèi),程序需要對(duì)哈希表進(jìn)行擴(kuò)展或收縮。由于空間變大或縮小,之前的鍵在老表的存儲(chǔ)位置,在新表中就不一定一樣了,需要重新計(jì)算。這個(gè)重新計(jì)算,并把老表元素轉(zhuǎn)移到新表元素的過(guò)程就叫做rehash。當(dāng)然無(wú)論是java中的hashmap,concurrenthashmap,還是今天要講的Redis哈希表,都涉及rehash過(guò)程。
Redis中哈希表的數(shù)據(jù)結(jié)構(gòu)
來(lái)看一下Redis的Hash表邏輯設(shè)計(jì)結(jié)構(gòu) Redis的哈希表主要由三個(gè)結(jié)構(gòu)構(gòu)成:
dictht。單純表示一個(gè)哈希表
dictEntry。哈希表的一項(xiàng),可以看作就是一個(gè)鍵值對(duì)
dict。Redis給外層調(diào)用的哈希表結(jié)構(gòu),包含兩個(gè)dictht
- typedef struct dictht {
- dictEntry **table; //哈希表數(shù)組(哈希表項(xiàng)集合)
- unsigned long size; //Hash表大小
- unsigned long sizemask; //哈希表掩碼
- unsigned long used;//Hash表已使用的大小
- } dictht;
稍微解釋一下各個(gè)項(xiàng)。
- table:哈希表項(xiàng)的指針數(shù)組
- size:哈希表大小,這應(yīng)該不用多解釋吧
- sizemask:掩碼。這個(gè)值其實(shí)設(shè)計(jì)思想很棒,假設(shè)Redis長(zhǎng)度是3,你想訪問(wèn)第5個(gè)元素,如果按之前的方法,那肯定是訪問(wèn)到超出redis哈希表范圍的地址空間了。所以redis規(guī)定,你想訪問(wèn)元素,先把index與size做與,把超過(guò)redis長(zhǎng)度的部分就截?cái)嗔耍筒粫?huì)發(fā)生內(nèi)存安全問(wèn)題。
- Hash表已使用的大小。不解釋。
講了Hash表,來(lái)看看哈希項(xiàng)
- typedef struct dictEntry {
- void *key;
- union {
- void *val;
- uint64_t u64;
- int64_t s64;
- double d;
- } v;
- struct dictEntry *next;
- } dictEntry;
我們知道,Redis采用拉鏈法解決哈希沖突的問(wèn)題。因此,Redis的哈希表項(xiàng)就有一個(gè)next指針,指向下一個(gè)元素,通過(guò)該指針,就可以訪問(wèn)多個(gè)具有相同哈希值的鍵值對(duì)。
最后我們來(lái)看看dict結(jié)構(gòu)。
- typedef struct dict {
- dictType *type;
- void *privdata;
- dictht ht[2];
- int reshaidx;
- } dict;
大家肯定很好奇,好好的dict,搞兩個(gè)哈希表做啥?當(dāng)然也有不好奇的小伙伴,但沒(méi)辦法,架不住面試官也很好奇啊。
答案揭曉,兩個(gè)hash表是為了rehash。
那什么情況下需要rehash呢?
- 如果redis沒(méi)在執(zhí)行后臺(tái)備份,當(dāng)負(fù)載因子大于等于1就執(zhí)行。(反正CPU閑著也是閑著)
- 如果redis在執(zhí)行后臺(tái)備份,當(dāng)負(fù)載因子大于等于5就執(zhí)行。(CPU在干備份了,咱對(duì)于實(shí)在擠的表改一改,等CPU閑下來(lái),再把稍微偏擠的rehash)
我們來(lái)看一下如果出現(xiàn)需要rehash的情況,需要的執(zhí)行步驟:
- 分配空間給ht[1]。分配空間由ht[0]的具體參數(shù)決定。
- 將ht[0]存儲(chǔ)的鍵值對(duì),重新計(jì)算hash值和索引值,并賦值到ht[1]的對(duì)應(yīng)位置中。
- 當(dāng)賦值完成后,釋放ht[0]所占用空間,并把ht[0]指向ht[1]目前的地址。
- ht[1]指向空表。
漸進(jìn)式rehash
由于步驟二采用的計(jì)算方式如果在一定時(shí)間做,占用資源過(guò)高,所以redis提出了漸進(jìn)式rehash的方式。拿大白話來(lái)講,就是原來(lái)是一次,一次性的搬運(yùn),現(xiàn)在變成了分批搬運(yùn)。
在分批搬運(yùn)的過(guò)程中,難免會(huì)收到其他各式各樣的請(qǐng)求。
- 對(duì)于寫(xiě)請(qǐng)求,即往redis哈希表增加新的鍵值對(duì)時(shí),redis會(huì)把數(shù)據(jù)直接存放到ht[1]表中。
- 對(duì)于查請(qǐng)求,即查詢(xún)特定鍵對(duì)應(yīng)的值時(shí),redis首先會(huì)在ht[0]中查找,如果查找失敗,就會(huì)在ht[1]表中查找。
- 對(duì)于更新請(qǐng)求,redis首先會(huì)在ht[0]中查找,如果查找失敗,就會(huì)在ht[1]表中更新。
- 對(duì)于刪除請(qǐng)求,redis首先會(huì)在ht[0]中查找,如果查找失敗,就會(huì)在ht[1]表中刪除。
參考
https://www.cnblogs.com/tekkaman/p/5141936.html
https://blog.csdn.net/yangbodong22011/article/details/78467583
Redis的設(shè)計(jì)與實(shí)現(xiàn)
Redis源碼剖析與實(shí)戰(zhàn)