普林斯頓、英特爾提出ParNet,速度和準(zhǔn)確性顯著優(yōu)于ResNet
深度是深度神經(jīng)網(wǎng)絡(luò)的關(guān)鍵,但更多的深度意味著更多的序列計(jì)算和更多的延遲。這就引出了一個(gè)問題——是否有可能構(gòu)建高性能的「非深度」神經(jīng)網(wǎng)絡(luò)?
近日,普林斯頓大學(xué)和英特爾實(shí)驗(yàn)室的一項(xiàng)研究證明了這一觀點(diǎn)的可行性。該研究使用并行子網(wǎng)絡(luò)而不是一層又一層地堆疊,這有助于在保持高性能的同時(shí)有效地減少深度。

論文地址:https://arxiv.org/abs/2110.07641
通過利用并行子結(jié)構(gòu),該研究首次表明深度僅為 12 的網(wǎng)絡(luò)可在 ImageNet 上實(shí)現(xiàn)超過 80%、在 CIFAR10 上實(shí)現(xiàn)超過 96%、在 CIFAR100 上實(shí)現(xiàn) 81% 的 top-1 準(zhǔn)確率。該研究還表明,具有低深度主干網(wǎng)絡(luò)的模型可以在 MS-COCO 上達(dá)到 48% 的 AP 指標(biāo)。研究者分析了該設(shè)計(jì)的擴(kuò)展規(guī)則,并展示了如何在不改變網(wǎng)絡(luò)深度的情況下提高性能。最后,研究者提供了關(guān)于如何使用非深度網(wǎng)絡(luò)來構(gòu)建低延遲識(shí)別系統(tǒng)的概念證明。
方法
該研究提出了一種深度較低但仍能在多項(xiàng)基準(zhǔn)上實(shí)現(xiàn)高性能的網(wǎng)絡(luò)架構(gòu) ParNet,ParNet 由處理不同分辨率特征的并行子結(jié)構(gòu)組成。這些并行子結(jié)構(gòu)稱為流(stream),來自不同流的特征在網(wǎng)絡(luò)的后期融合,融合的特征用于下游任務(wù)。圖 2a 提供了 ParNet 的示意圖。
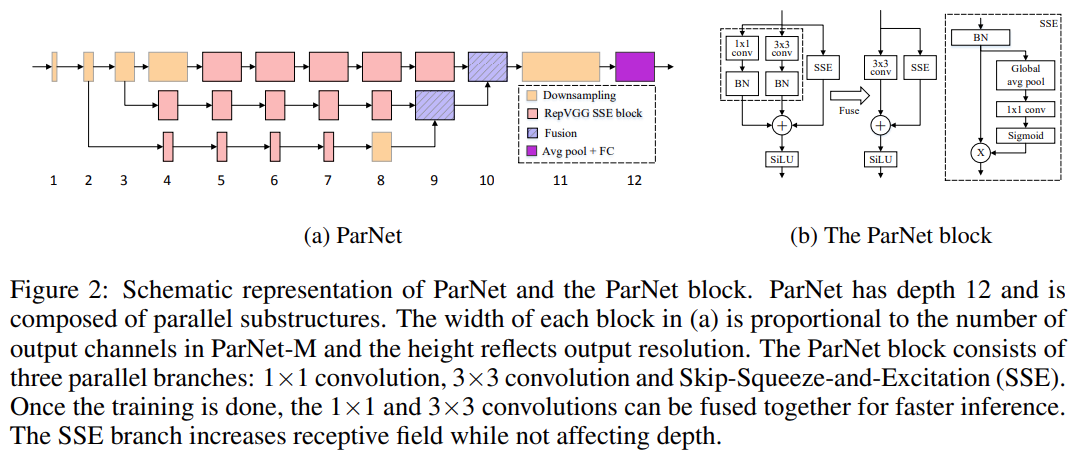
圖 2
ParNet Block
ParNet 中使用了 VGG 風(fēng)格的 block(Simonyan & Zisserman,2015)。為了探究非深度網(wǎng)絡(luò)是否可以實(shí)現(xiàn)高性能,該研究通過實(shí)驗(yàn)發(fā)現(xiàn) VGG 風(fēng)格 block 比 ResNet 風(fēng)格 block 更合適(如下表 8 所示)。一般來說,訓(xùn)練 VGG 風(fēng)格的網(wǎng)絡(luò)比 ResNet 更難(He 等,2016a)。但是最近的一些工作表明,使用「結(jié)構(gòu)重參數(shù)化」方法(Ding 等,2021),會(huì)讓 VGG 風(fēng)格 block 更容易訓(xùn)練。
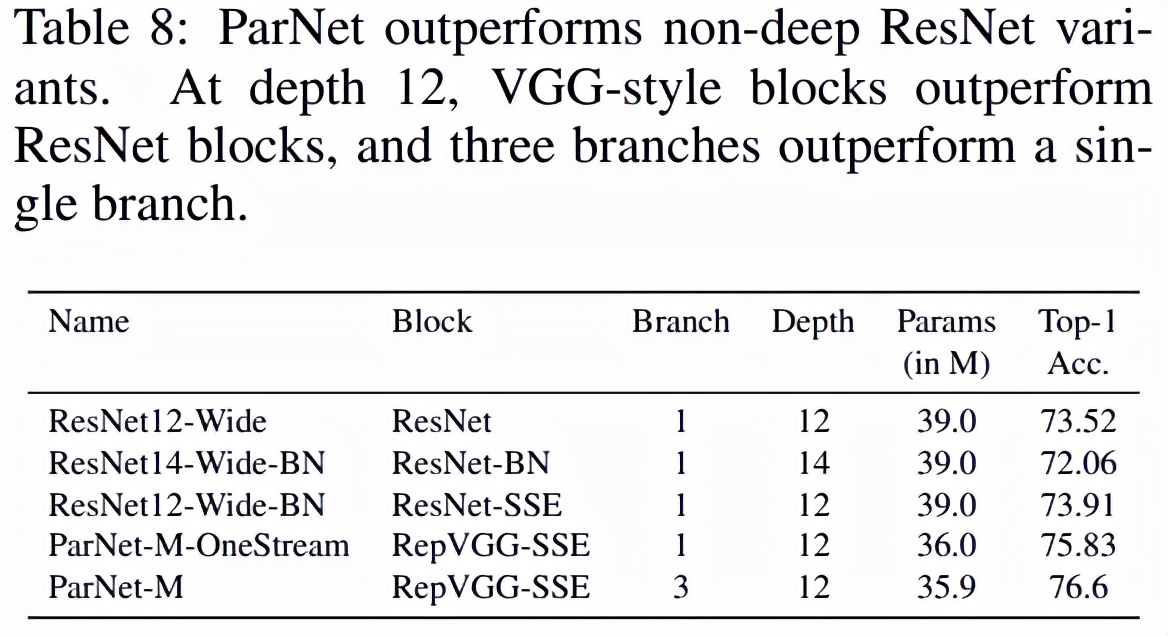
訓(xùn)練期間,該研究在 3×3 卷積 block 上使用多個(gè)分支。訓(xùn)練完成后,多個(gè)分支可以融合為一個(gè) 3×3 的卷積 block。因此,最終得到一個(gè)僅由 3×3 block 和非線性組成的簡(jiǎn)單網(wǎng)絡(luò)。block 的這種重參數(shù)化或融合(fusion)有助于減少推理期間的延遲。
降采樣和融合 block
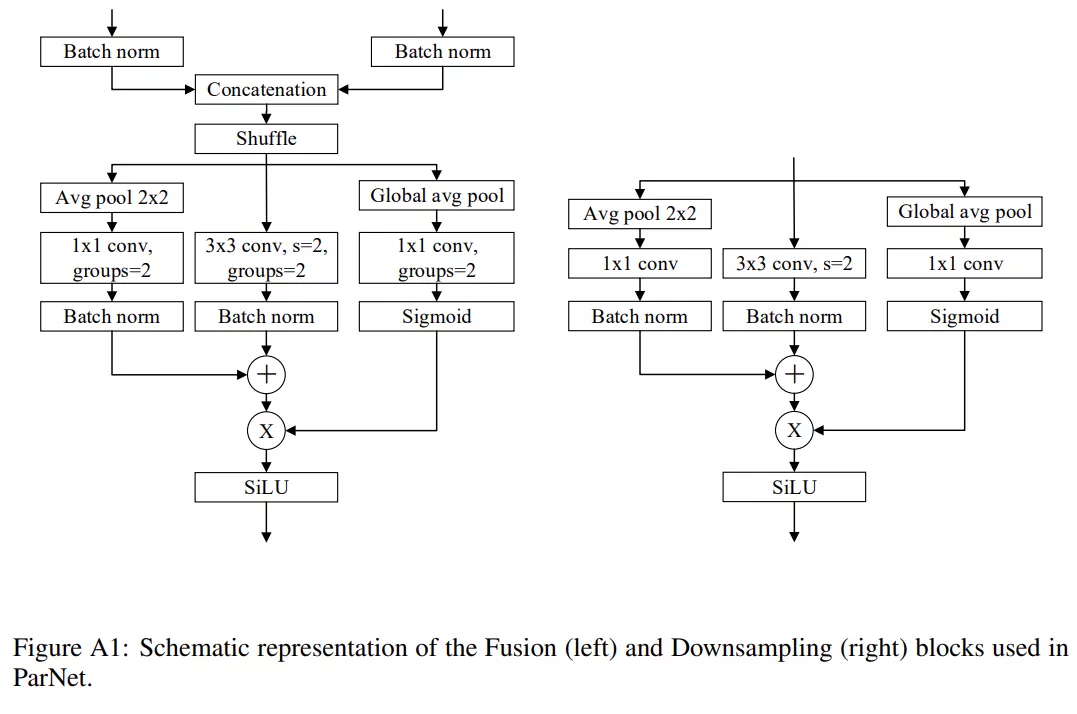
除了輸入和輸出大小相同的 RepVGG-SSE block 之外,ParNet 還包含降采樣(downsampling)和融合 block。降采樣 block 降低了分辨率并增加了寬度以實(shí)現(xiàn)多尺度(multi-scale)處理,而融合 block 將來自多個(gè)分辨率的信息組合。在降采樣 block 中,沒有殘差連接(skip connection);相反,該研究添加了一個(gè)與卷積層并行的單層 SE 模塊。
此外,該研究在 1×1 卷積分支中添加了 2D 平均池化。融合 block 和降采樣 block 類似,但還包含一個(gè)額外的串聯(lián)(concatenation)層。由于串聯(lián),融合 block 的輸入通道數(shù)是降采樣 block 的兩倍。為了減少參數(shù)量,該研究的降采樣和融合 block 的設(shè)計(jì)如下圖所示。
網(wǎng)絡(luò)架構(gòu)
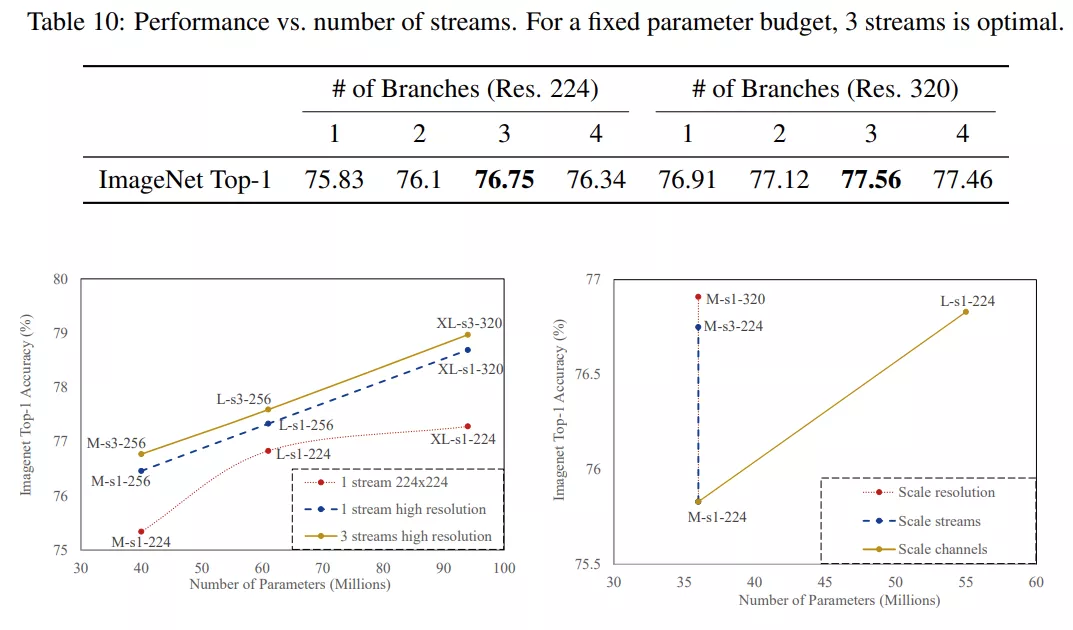
圖 2a 展示了用于 ImageNet 數(shù)據(jù)集的 ParNet 模型示意圖。初始層由一系列降采樣塊組成,降采樣 block 2、3 和 4 的輸出分別饋送到流 1、2 和 3。研究者發(fā)現(xiàn) 3 是給定參數(shù)預(yù)算的最佳流數(shù)(如表 10 所示)。每個(gè)流由一系列不同分辨率處理特征的 RepVGG-SSE block 組成。然后來自不同流的特征由融合 block 使用串聯(lián)進(jìn)行融合。最后,輸出被傳遞到深度為 11 的降采樣 block。與 RepVGG(Ding 等, 2021)類似,該研究對(duì)最后一個(gè)降采樣層使用更大的寬度。
擴(kuò)展 ParNet
據(jù)觀察,神經(jīng)網(wǎng)絡(luò)可以通過擴(kuò)大網(wǎng)絡(luò)規(guī)模來獲得更高的準(zhǔn)確度。之前的研究 (Tan & Le, 2019) 擴(kuò)展了寬度、分辨率和深度。由于本研究的目標(biāo)是評(píng)估是否可以在深度較低的情況下實(shí)現(xiàn)高性能,因此研究者將模型的深度保持不變,通過增加寬度、分辨率和流數(shù)來擴(kuò)展 ParNet。
對(duì)于 CIFAR10 和 CIFAR100,該研究增加了網(wǎng)絡(luò)的寬度,同時(shí)將分辨率保持為 32,流數(shù)保持為 3。對(duì)于 ImageNet,該研究在三個(gè)不同的維度上進(jìn)行了實(shí)驗(yàn),如下圖 3 所示。
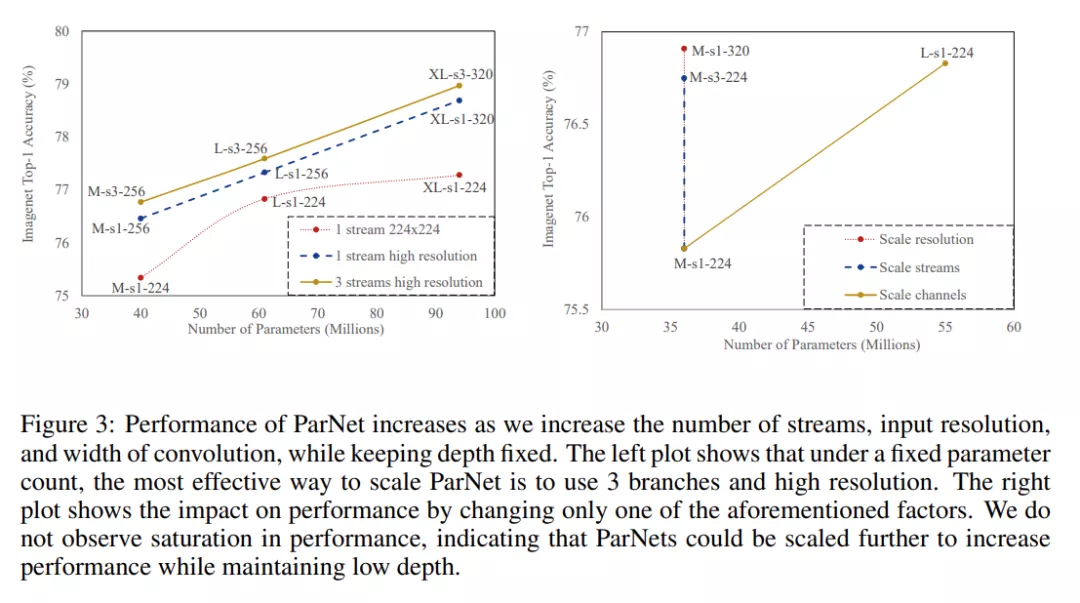
并行架構(gòu)的實(shí)際優(yōu)勢(shì)
目前 5 納米光刻工藝已接近 0.5 納米晶硅尺寸,處理器頻率進(jìn)一步提升的空間有限。這意味著神經(jīng)網(wǎng)絡(luò)的更快推理必須依賴計(jì)算的并行化。單個(gè)單片 GPU 的性能增長(zhǎng)也在放緩,預(yù)計(jì)傳統(tǒng)光刻可實(shí)現(xiàn)的最大芯片尺寸將達(dá)到 800 平方毫米(Arunkumar 等,2017)。總體而言,未來在處理器頻率、芯片尺寸以及每個(gè)處理器的晶體管數(shù)等方面都將維持一個(gè)平穩(wěn)狀態(tài)。
為了解決這個(gè)問題,最近的一些工作提出了多芯片模塊 GPU (MCM-GPU),比最大的可實(shí)現(xiàn)單片 GPU 更快。用中型芯片取代大型芯片有望降低硅成本。這樣的芯片設(shè)計(jì)有利于具有并行分支的分區(qū)算法,算法之間交換有限的數(shù)據(jù)并且盡可能地分別獨(dú)立執(zhí)行。基于這些因素,非深度并行結(jié)構(gòu)將有利于實(shí)現(xiàn)快速推理,尤其是對(duì)于未來的硬件。
實(shí)驗(yàn)結(jié)果
表 1 展示了 ParNet 在 ImageNet 上的性能。該研究發(fā)現(xiàn),深度僅為 12 的網(wǎng)絡(luò)就可以實(shí)現(xiàn)驚人的高性能。為了與 ResNet 進(jìn)行公平比較,研究者使用相同的訓(xùn)練協(xié)議和數(shù)據(jù)增強(qiáng)重新訓(xùn)練 ResNet,這將 ResNet 的性能提升到了超越官方結(jié)果的水平。值得注意的是,該研究發(fā)現(xiàn) ParNet-S 在參數(shù)數(shù)量較少的情況下(19M vs 22M)在準(zhǔn)確率上比 ResNet34 高出 1 個(gè)百分點(diǎn)以上。ParNet 還通過瓶頸設(shè)計(jì)實(shí)現(xiàn)了與 ResNet 相當(dāng)?shù)男阅埽瑫r(shí)深度減少到 1/4-1/8。
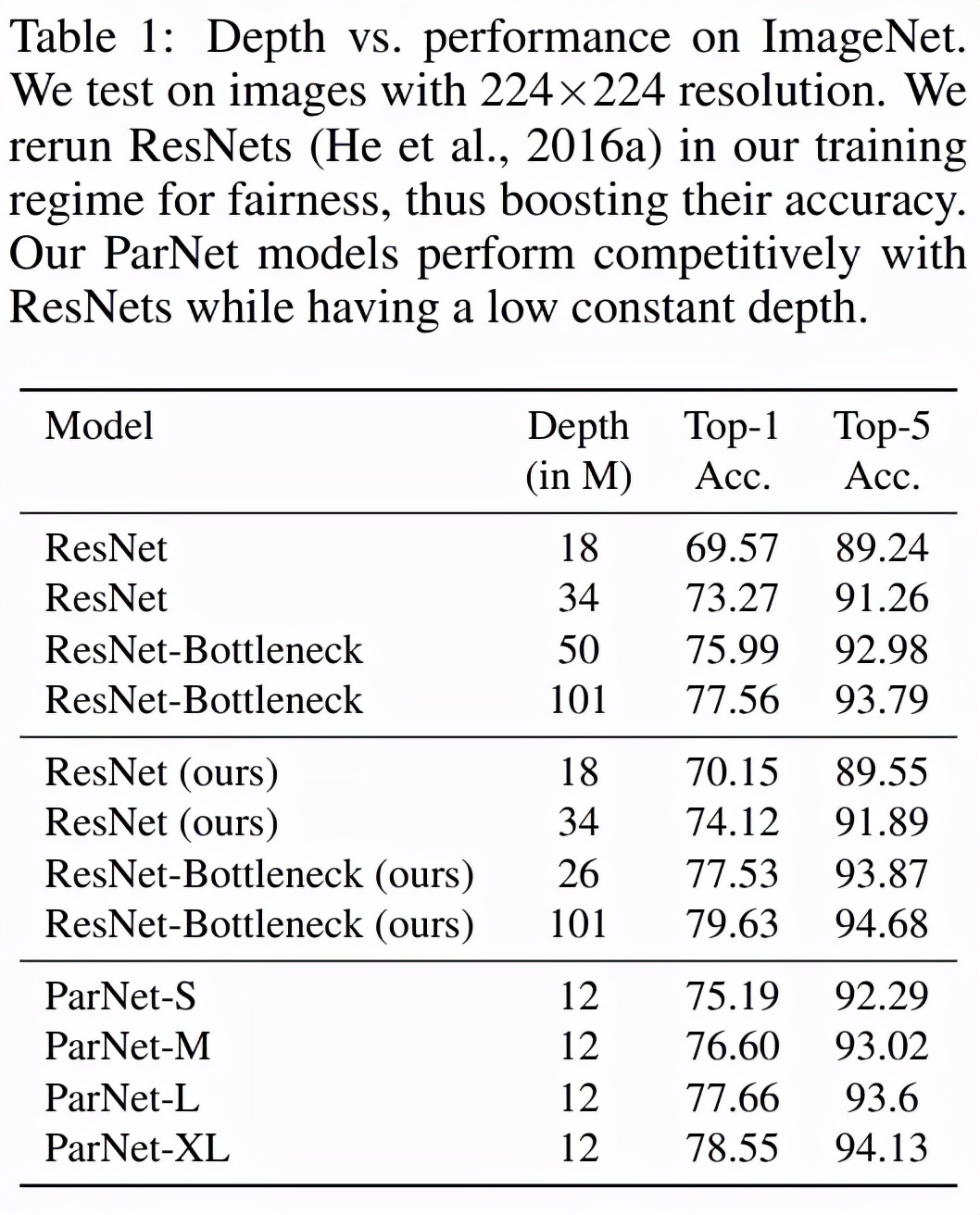
如下表 2 所示,ParNet 在準(zhǔn)確率和速度上優(yōu)于 ResNet,但參數(shù)和 flop 也更多。例如,ParNet-L 實(shí)現(xiàn)了比 ResNet34 和 ResNet50 更快的速度和更好的準(zhǔn)確度。類似地,ParNet-XL 實(shí)現(xiàn)了比 ResNet50 更快的速度和更好的準(zhǔn)確度,但具有更多的參數(shù)和 flop。這表明使用 ParNet 代替 ResNet 時(shí)存在速度與參數(shù)和 flop 之間的權(quán)衡。請(qǐng)注意,可以通過利用可以分布在 GPU 上的并行子結(jié)構(gòu)來實(shí)現(xiàn)高速。
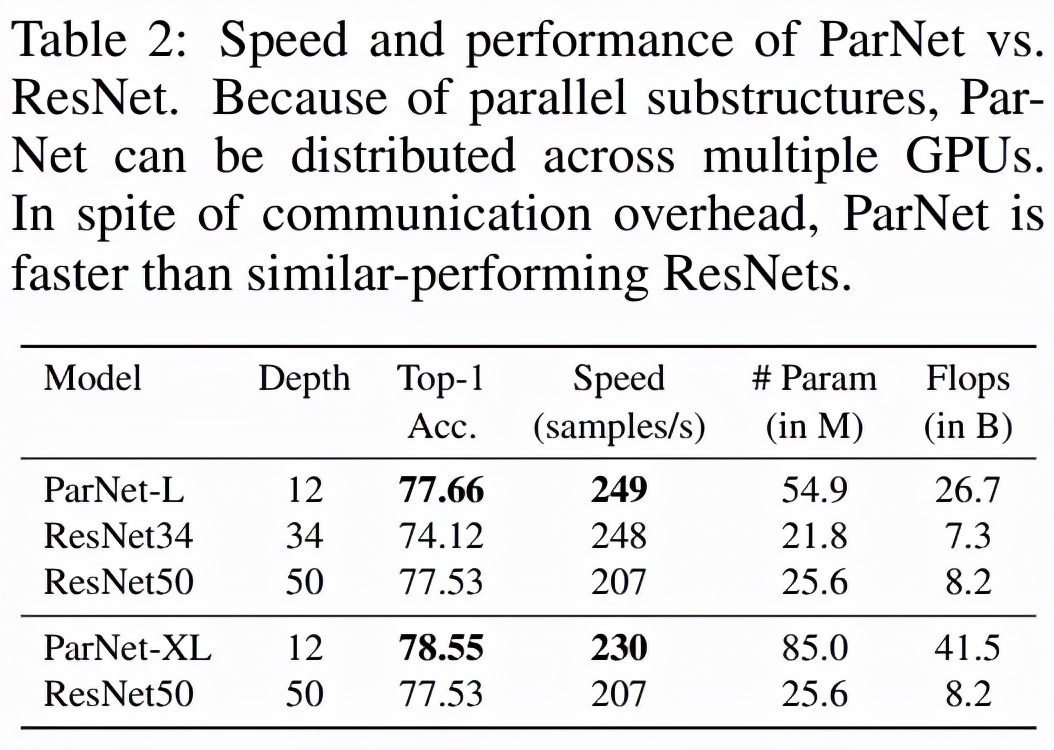
該研究測(cè)試了 ParNet 三種變體的速度:未融合、融合和多 GPU,結(jié)果如下表 3 所示。未融合的變體由 RepVGG-SSE 塊中的 3×3 和 1×1 分支組成。在融合變體中,使用結(jié)構(gòu)重參數(shù)化技巧將 3×3 和 1×1 分支合并為一個(gè) 3×3 分支。對(duì)于融合和未融合變體,該研究使用單個(gè) GPU 進(jìn)行推理,而對(duì)于多 GPU 變體,使用了 3 個(gè) GPU。對(duì)于多 GPU 變體,每個(gè)流都在單獨(dú)的 GPU 上啟動(dòng)。當(dāng)一個(gè)流中的所有層都被處理時(shí),來自兩個(gè)相鄰流的結(jié)果將在其中一個(gè) GPU 上連接并進(jìn)一步處理。為了跨 GPU 傳輸數(shù)據(jù),該研究使用了 PyTorch 中的 NCCL 后端。
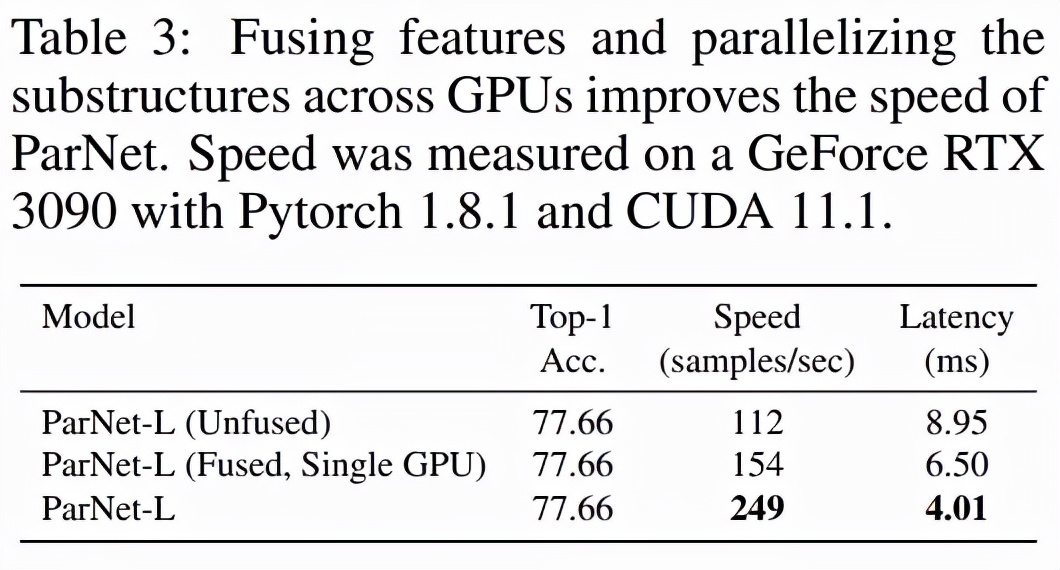
該研究發(fā)現(xiàn)盡管存在通信開銷,但 ParNet 仍可以跨 GPU 有效并行化以進(jìn)行快速推理。使用專門的硬件可以減少通信延遲,甚至可以實(shí)現(xiàn)更快的速度。
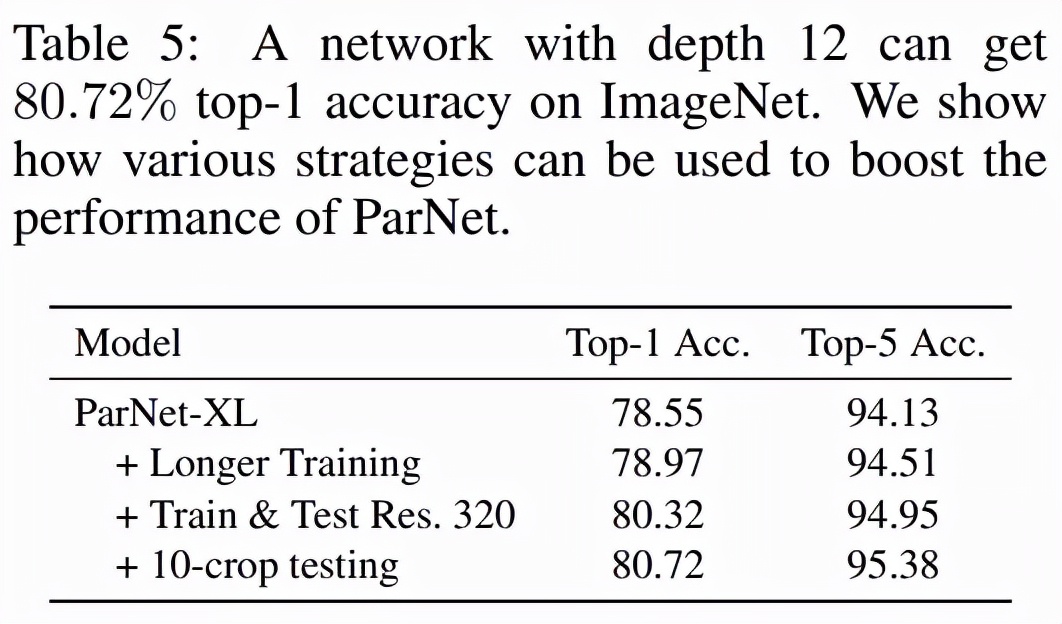
表 5 展示了提高 ParNet 性能的其他方法,例如使用更高分辨率的圖像、更長(zhǎng)的訓(xùn)練機(jī)制(200 個(gè) epoch、余弦退火)和 10-crop 測(cè)試。這項(xiàng)研究有助于評(píng)估非深度模型在 ImageNet 等大規(guī)模數(shù)據(jù)集上可以實(shí)現(xiàn)的準(zhǔn)確性。
MS-COCO (Lin 等,2014) 是一個(gè)目標(biāo)檢測(cè)數(shù)據(jù)集,其中包含具有常見對(duì)象的日常場(chǎng)景圖像。研究者用 COCO-2017 數(shù)據(jù)集進(jìn)行了評(píng)估。如下表 4 所示,即使在單個(gè) GPU 上,ParNet 也實(shí)現(xiàn)了比基線更高的速度。這闡明了如何使用非深度網(wǎng)絡(luò)來制作快速目標(biāo)檢測(cè)系統(tǒng)。
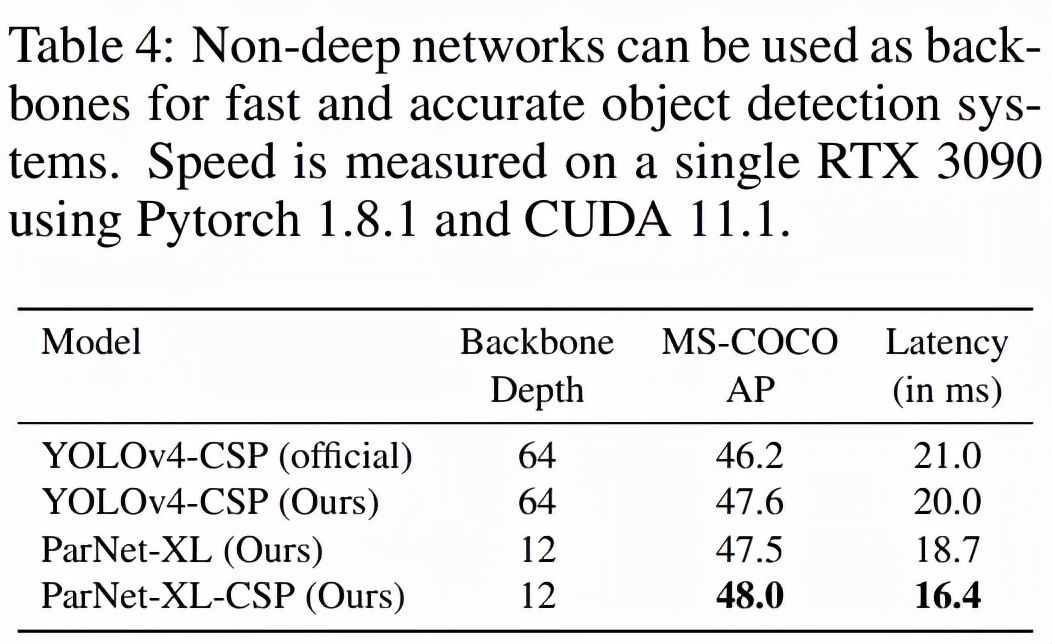
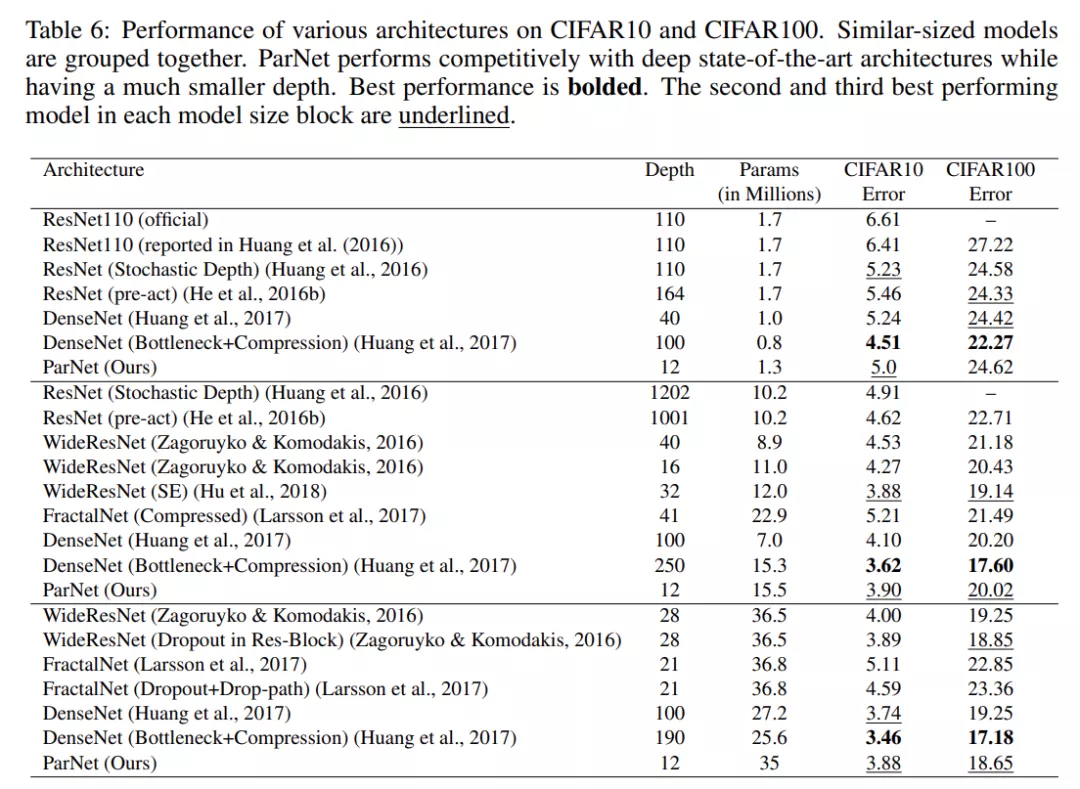
表 6 總結(jié)了各種網(wǎng)絡(luò)在 CIFAR10 和 CIFAR100 上的性能。
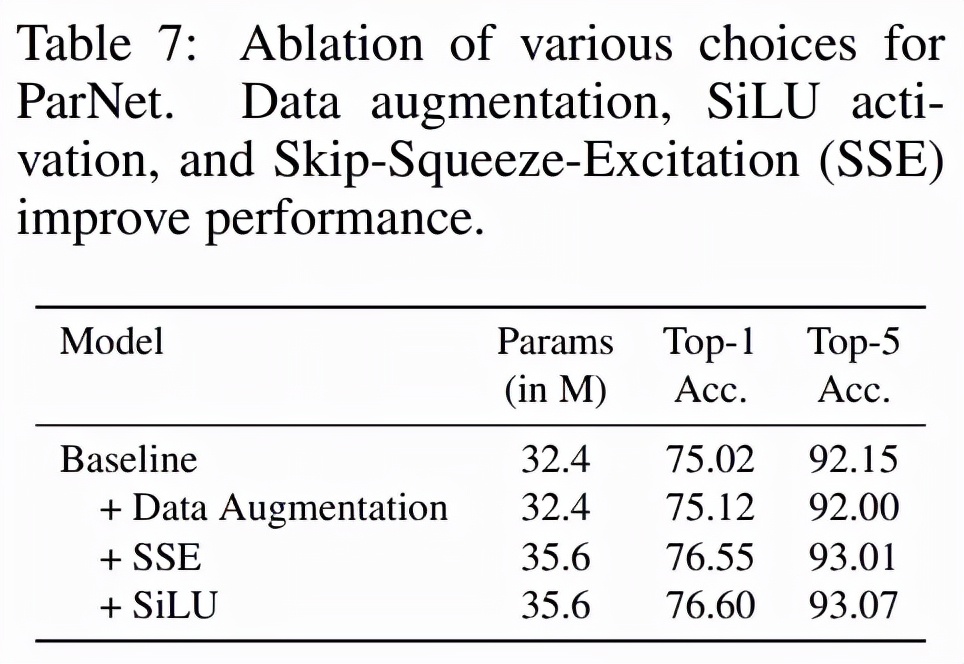
消融實(shí)驗(yàn)
為了測(cè)試是否可以簡(jiǎn)單地減少 ResNet 的深度并使它們變寬,研究者測(cè)試了三個(gè) ResNet 變體:ResNet12-Wide、ResNet14-Wide-BN 和 ResNet12-Wide-SSE。ResNet12-Wide 使用 ResNet 基礎(chǔ) block,深度為 12,而 ResNet14-Wide-BN 使用 ResNet 瓶頸 block,深度為 14。表 7 展示了對(duì)網(wǎng)絡(luò)架構(gòu)和訓(xùn)練協(xié)議的各種設(shè)計(jì)的消融研究結(jié)果,其中包括使用數(shù)據(jù)增強(qiáng)、SSE block 和 SiLU 激活函數(shù)的 3 種情況。
在表 10 中,研究者評(píng)估了參數(shù)總數(shù)相同但分支數(shù)不同( 1、2、3、4)的網(wǎng)絡(luò)。實(shí)驗(yàn)表明,對(duì)于固定數(shù)量的參數(shù),具有 3 個(gè)分支的網(wǎng)絡(luò)具有最高的準(zhǔn)確率,并且在網(wǎng)絡(luò)分辨率分別為 224x224 和 320x320 這兩種情況下都是最優(yōu)的。
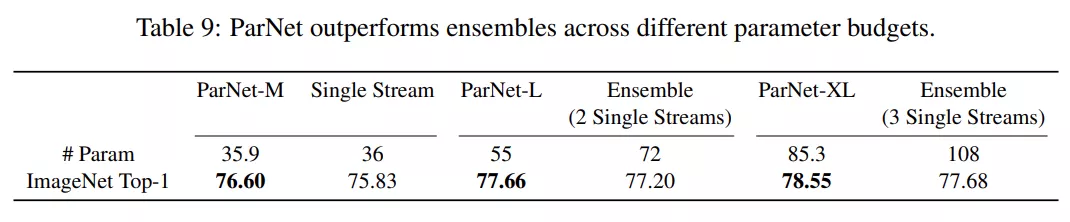
另一種網(wǎng)絡(luò)并行化的方法是創(chuàng)建由多個(gè)網(wǎng)絡(luò)組成的集合體。因此,該研究將 ParNet 和集成的網(wǎng)絡(luò)進(jìn)行對(duì)比。如下表 9 所示,當(dāng)使用較少的參數(shù)時(shí),ParNet 的性能優(yōu)于集成的網(wǎng)絡(luò)。