3 萬字聊聊什么是 Redis
大家好,我是Leo。
結束了漫長了MySQL,開始步入了Redis的殿堂。最近在做Redis技術輸出時,明顯發現進一步熟悉MySQL之后,對Redis的理解容易了許多。或許這就是進步吧!
下面的思路部分,可以幫助你更好的理解這篇文章的知識體系。
思路
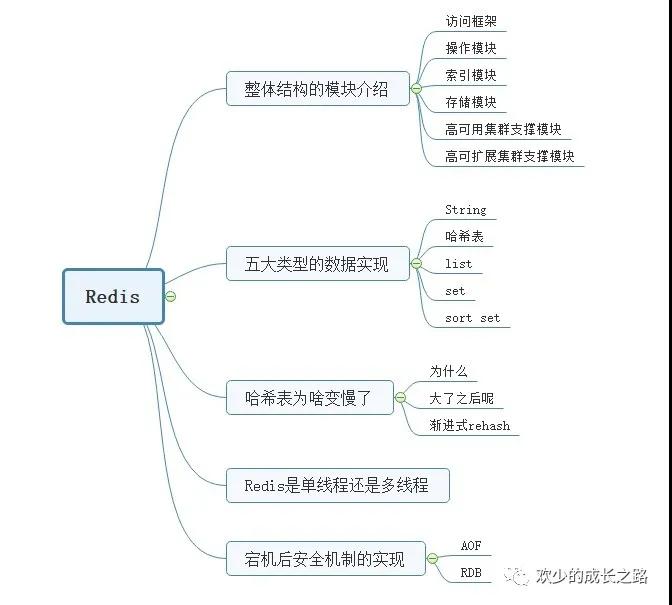
整體結構
Redis主要是由訪問框架,操作模塊,索引模塊,存儲模塊,高可用集群支撐模塊,高可用擴展支撐模塊等組成,
Redis還有一些,豐富的數據類型,數據壓縮,過期機制,數據淘汰策略,分片機制,哨兵模式,主從復制,集群化,高可用,統計模塊,通知模塊,調試模塊,元數據查詢等輔助功能。
接下來的Redis學習之路,主要是圍繞介紹上述模塊,功能,策略,機制,算法等知識的輸出。
五大類型
String
String類型應該是我們用的最多的一種類型,它的底層是由簡單的動態字符串實現的。
hash
hash類型也是我們用的最多的一種類型了,它是由壓縮列表+哈希表共同實現的一種數據類型
list
list它是一種列表類型,也是我們常用類型之一,它是由雙向鏈表+壓縮列表共同實現的一種數據類型
set
set集合和上述類型不同,他不允許重復,所以一些特定的場景會優先考慮set類型,它是由整數數組+哈希表共同實現的一種數據類型
sort set
sortset是在set的基礎上,做的一個提升,不允許重復的時候,還可以處理有序。主要應用與排序表之類的場景需求,它是由壓縮鏈表+跳表實現的一種數據類型
數據結構
哈希表會在下文rehash那里詳細介紹一下。
整數數組和雙向鏈表也很常見,它們的操作特征都是順序讀寫,也就是通過數組下標或者鏈表的指針逐個元素訪問,操作復雜度基本是 O(N),操作效率比較低。
壓縮列表實際上類似于一個數組,數組中的每一個元素都對應保存一個數據。和數組不同的是,壓縮列表在表頭有三個字段 zlbytes、zltail 和 zllen,分別表示列表長度、列表尾的偏移量和列表中的 entry 個數;壓縮列表在表尾還有一個 zlend,表示列表結束。在壓縮列表中,如果我們要查找定位第一個元素和最后一個元素,可以通過表頭三個字段的長度直接定位,復雜度是 O(1)。而查找其他元素時,就沒有這么高效了,只能逐個查找,此時的復雜度就是 O(N) 了。
跳表在鏈表的基礎上,增加了多級索引,通過索引位置的幾個跳轉,實現數據的快速定位。在下述文章中的第五章節介紹過了跳表的相關說明。
哈希為啥變慢了
Redis在處理一個鍵值對時,會進行一次hash處理,把鍵處理成一個地址碼寫入Redis的存儲模塊,隨著我們key的越來越多,有一些key會存在同一個地址碼的情況。(我在寫hashmap的時候就介紹過hash碰撞的問題)
出現這種情況之后Redis作了一個鍵值對的擴展,也就是鍵值對+鏈表的方式。如下圖,多個數據經過hash處理之后,都落到了key1值上。一個卡槽不可能存放兩個值,于是就在這個卡槽存了指向一個鏈表的指針,通過鏈表存儲多個值。
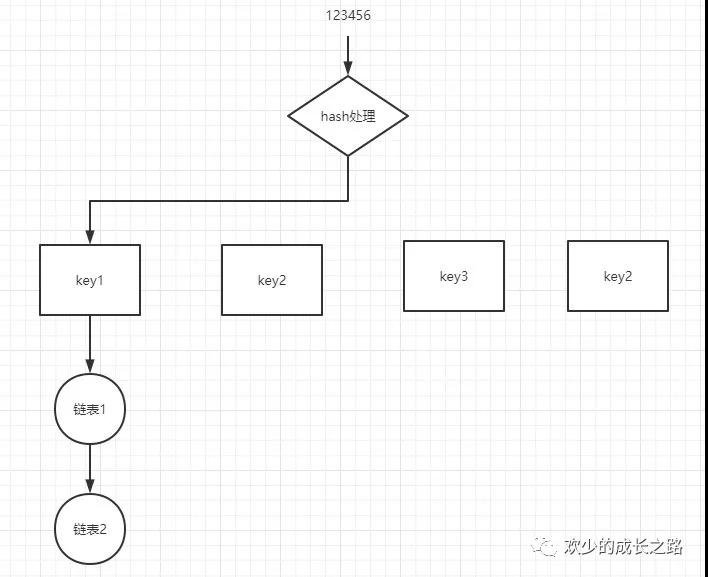
哈希鏈表
鏈表處理的就是多個key一樣的問題,隨著數據量的發展,哈希碰撞的情況越來越頻繁,鏈表的數據也就越來越多。hash的性能是O(1),鏈表的性能是O(n)。所以整體的性能被拖下來了。為了改變這一現狀,Redis引入了rehash。
rehash
rehash就是增加現有的哈希桶的數量,讓逐漸增多的元素能在更多的哈希桶之間分散保存。從而減少單個桶的鏈表的元素數量,同時也減少單個桶的沖突。
首先Redis會先創建兩個全局哈希表,我們這里定義為哈希表A,哈希表B。我們在插入一個數據時,先先存入A,隨著A越來越多,Redis開始執行rehash操作。主要分為三步:
- 給B分配更多的空間,一般都是A的兩倍
- 把A中的數據全部拷貝到B中
- 釋放A
上述rehash流程我們可以看出,當A中存在大量的數據,拷貝的效率是非常慢的!因為Redis的單線程性還會造成阻塞,導致Redis短時間無法提供服務。為了避免這一問題,Redis在rehash的基礎上,采用了漸進式rehash。
漸進式 rehash
進化點就是在第二步拷貝的時候,并不是一次性拷貝的,而是分批次拷貝。在處理一個請求時,從A中的第一個索引位置開始,順帶著將這個索引位置上的所有元素拷貝到B中。等下一個請求后,再從A表中的下一個索引位置繼續拷貝操作。這樣就巧妙地把一次性大量拷貝的開銷,分攤到了多次處理請求的過程中,避免了耗時操作,保證了數據的快速訪問。
Redis單線程還是多線程
先來普及一下多線程的知識,一個CPU在運行多個線程時,會有一個多線程調用的消耗問題,而且還有多個線程調用時數據一致性的問題。這些都要單獨處理,單獨處理又會消耗性能。于是Redis統籌兼顧采用了單,多線程并用的思路。
在處理數據寫入,讀取屬于鍵值對數據操作,采用單線程操作。在請求連接,從socket中讀取請求,解析客戶端發送請求,采用多線程操作。
Redis巧妙的把所有需要延遲等待的操作全部轉交給了多線程處理,在不需要等待的全部單線程處理。個人感覺這種設計思路很棒
tip:如果不按照這種方式設計的,連接之后等待,發送等待,接收等待估計要等死你哦。造成Redis線程阻塞,無法處理其他請求。
多路復用機制
IO多路復用機制是指一個線程處理多個IO流,也是我們經常聽到的select/epoll機制。那么那些連接,等待的操作Redis都是如何處理的呢?
在Redis只運行單線程的情況下,同一時間存在多個監聽套接字,和已連接的套接字,內核會一直監聽這些連接請求和數據請求。一旦客戶端發送請求就會以事件的方式通知Redis主線程處理。這就是Redis線程處理多個IO流的效果。
上文說到以事件方式通知Redis這里我們做一個擴展,select/epoll提供了基于事件的回調機制,不同的事件會調用相應的處理函數。一旦請求來了,立刻加到事件隊列中,Redis單線程就會源源不斷的處理該事件隊列。解決了等待與掃描的資源浪費問題。
安全機制
Redis的持久化安全機制主要有兩大塊,一塊是AOF日志,一塊是RDB快照,接下來我們聊聊AOF與RDB的一些區別吧
AOF
Redis為了提升性能采用的是寫后日志,先執行命令,后寫日志,這樣做的好處主要有兩點
- 只有當命令執行成功之后才會寫入日志。這樣就避免了寫入日志之后,命令執行錯誤還要把日志刪掉的問題。
- 先執行寫入操作,后寫日志,這樣同時也避免了阻塞當前的寫操作
壞處是:
- 如果一個命令執行完后,還沒記錄日志就宕機了,那么這個命令和相應的數據就有丟失的風險。
- AOF雖然避免了對當前命令的阻塞,但可能會對下一個操作帶來阻塞風險。因為AOF日志也是在主線程中執行的,并且是
- 寫入磁盤。
文件格式:
Redis收到一個 "set huanshao 公眾號歡少的成長之路" 命令后,AOF的日志內容是,"*3" 表示當前命令有三個部分,每部分都是由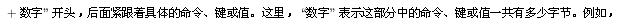
+數字”開頭,后面緊跟著具體的命令、鍵或值。這里,“數字”表示這部分中的命令、鍵或值一共有多少字節。例如,“
3 set”表示這部分有 3 個字節,也就是“set”命令。
AOF寫入策略
AOF提供了三種appendfsync可選值
- Always,同步寫回:每個寫命令執行完,立馬同步地將日志寫回磁盤;
- Everysec,每秒寫回:每個寫命令執行完,只是先把日志寫到 AOF 文件的內存緩沖區,每隔一秒把緩沖區中的內容寫入磁盤;
- No,操作系統控制的寫回:每個寫命令執行完,只是先把日志寫到 AOF 文件的內存緩沖區,由操作系統決定何時將緩沖區內容寫回磁盤。
這三種都無法做到兩全其美,同步寫會可以做到數據一致性,但是寫入磁盤的這個性能對比內存來說太差了,如果是每秒寫的話,就會丟失1秒的數據,如果No配置的話宕機后丟失數據比較多。
最后三種配置如何選擇,應該根據特定的業務場景。如果數據安全性過高就選擇同步寫回,如果適中就每秒寫回,沒安全性的話就選擇No。
AOF重寫機制
AOF日志是追加形式的,避免不了的就是文件過大之后,再寫入日志的性能會有所下降,Redis為了解決這一難題,引入了重寫機制。
重寫機制主要做的事情是記錄一個key值的最終修改結果,修改的歷史記錄一律排除。這樣一來,一個命令就只有一個日志。如果要拿AOF日志恢復數據的話也能恢復出正確的數據。
重寫機制流程就是主線程fork出一個后臺子線程 bgrewriteaof后,fork會把主線程的內存拷貝一份給子線程bgrewriteaof,這樣子線程就可以在不影響主線程阻塞的情況下進行重寫操作了。
在這段期間,如果有新的請求寫入過來,Redis會有兩個日志,一個日志指正在使用的 AOF 日志,Redis 會把這個操作寫到它的緩沖區。這樣一來,即使宕機了,這個 AOF 日志的操作仍然是齊全的,可以用于恢復。另一處日志指新的 AOF 重寫日志。這個操作也會被寫到重寫日志的緩沖區。這樣,重寫日志也不會丟失最新的操作。等到拷貝數據的所有操作記錄重寫完成后,重寫日志記錄的這些最新操作也會寫入新的 AOF 文件,以保證數據庫最新狀態的記錄。此時,我們就可以用新的 AOF 文件替代舊文件了。
RDB
RDB是一種內存快照,它是系統某一刻的數據備份寫到磁盤上。這樣就可以達到宕機后,可以恢復某一刻之前的所有數據。
生成RDB的兩種方式
- save:在主線程中執行,會導致阻塞;
- bgsave:創建一個子進程,專門用于寫入 RDB 文件,避免了主線程的阻塞,這也是 Redis RDB 文件生成的 默認配置。
寫時復制技術
首先介紹一下寫時復制技術的由來,在Redis做RDB快照時(當前RDB還沒有做完),來了一個修改數據的請求。如果把這個請求寫入快照,那么就不符合那一刻的數據一致性。如果不寫入快照把他丟棄,就會造成數據丟失還是會有數據一致性的問題。所以Redis借助操作系統提供的寫時復制技術,在執行快照的同時,正常處理寫操作。
處理流程
主線程fork創建子線程bgsave,可以共享主線程的所有內存數據,bgsave子線程運行后,開始讀取主線程的內存數據,并把它們寫入 RDB 文件。如果主線程對這些數據都是讀操作,那么互不影響。如果是修改操作的話就會把這塊數據復制一份,生成該數據的副本。然后主線程在這個副本上進行修改。同時bgsave 子進程可以繼續把原來的數據寫入 RDB 文件。
這樣保證了快照的數據一致性,也保證了快照期間對正常業務的影響。
既然RDB那么牛逼,可否用RDB做持久化呢?
如果我們采用RDB做持久化的話,那么就要一直進行RDB快照,如果每2秒做一次快照的話,最壞的打算就要少50%的數據量,如果每秒做一次快照,可以完全保證數據的一致性但是帶來的負面影響也是非常大的。
- 頻繁快照,導致磁盤IO占用影響,且磁盤內存開銷非常大
- RDB由bgsave處理,雖然不阻塞主線程,但是主線程新建bgsave時,會影響主線程,如果每秒新建一次,有可能會阻塞主線程的。
全量備份不行的話,增量備份是否可以用RDB做持久化呢?
增量備份與全量備份的區別就是,增量備份只備份修改的數據。如果是這樣的話,我們就需要對每一個數據都加一個記錄,這樣開銷是十分大的。如果為了增量備份犧牲了寶貴的內存資源,這就有點得不償失了。
實戰應用
上述我們介紹了AOF與RDB的區別,流程,優缺點。我們可以發現,如果只依靠某一種方式進行持久化都無法有效的達到數據一致性。
如果只用RDB,快照的頻率不好把握,如果使用AOF,文件持續變大也是吃不消的。
最優的策略就是 RDB + AOF 假如每小時備份一次RDB,我們就可以利用RDB文件恢復那一刻的所有數據,然后再用AOF日志恢復這一小時的數據。