













阿里可觀測性數據引擎的技術實踐
一 、前言
可觀測性這個概念最早出現于20世紀70年代的電氣工程,核心的定義是:
A system is said to be observable if, for any possible evolution of state and control vectors, the current state can be estimated using only the information from outputs.

相比傳統的告警、監控,可觀測性能夠以更加“白盒”的方式看透整個復雜的系統,幫助我們更好的觀察系統的運行狀況,快速定位和解決問題。就像發動機而言,告警只是告訴你發動機是否有問題,而一些包含轉速、溫度、壓力的儀表盤能夠幫我們大致確定是哪個部分可能有問題,而真正定位細節問題還需要觀察每個部件的傳感器數據才行。
二 、IT系統的可觀測性
電氣化時代起源于第二次工業革命(Second Industrial Revolution)起于19世紀七十年代,主要標志是:電力、內燃機的廣泛應用。而可觀測性這一概念為何在近100年后才會被提出?難道在此之前就不需要依賴各類傳感器的輸出定位和排查故障和問題?顯然不是,排查故障的方式一直都在,只是整個系統和情況更加復雜,所以才需要更加體系化、系統化的方式來支持這一過程,因此演化出來可觀測性這個概念。所以核心點在于:
- 系統更加的復雜:以前的汽車只需要一個發動機、傳送帶、車輛、剎車就可以跑起來,現在隨便一個汽車上至少有上百個部件和系統,故障的定位難度變的更大。
- 開發涉及更多的人:隨著全球化時代的到來,公司、部分的分工也越來越細,也就意味著系統的開發和維護需要更多的部門和人來共同完成,協調的代價也越來越大。
- 運行環境多種多樣:不同的運行環境下,每個系統的工作情況是變化的,我們需要在任何階段都能有效記錄好系統的狀態,便于我們分析問題、優化產品。

而IT系統經過幾十年的飛速發展,整個開發模式、系統架構、部署模式、基礎設施等也都經過了好幾輪的優化,優化帶來了更快的開發、部署效率,但隨之而來整個的系統也更加的復雜、開發依賴更多的人和部門、部署模式和運行環境也更加動態和不確定,因此IT行業也已經到了需要更加系統化、體系化進行觀測的這一過程。
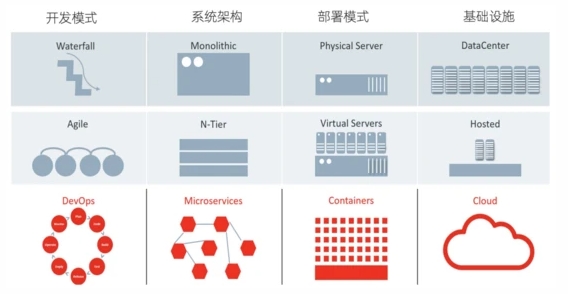
IT系統的可觀測性實施起來其實和電氣工程還是比較類似,核心還是觀察我們各個系統、應用的輸出,通過數據來判斷整體的工作狀態。通常我們會把這些輸出進行分類,總結為Traces、Metrics、Logs。關于這三種數據的特點、應用場景以及關系等,我們會在后面進行詳細展開。
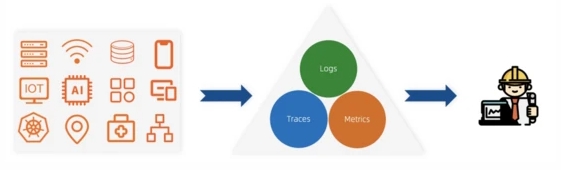
三、IT可觀測性的演進
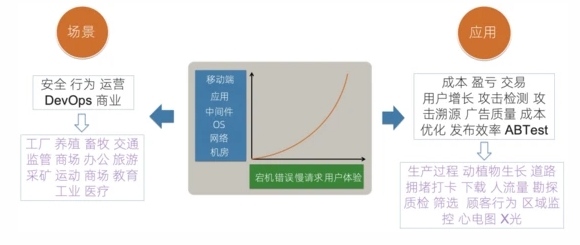
IT的可觀測性技術一直在不斷的發展中,從廣義的角度上講,可觀測性相關的技術除了應用在IT運維的場景外,還可以應用在和公司相關的通用場景以及特殊場景中。
- IT運維場景:IT運維場景從橫向、縱向來看,觀察的目標從最基礎的機房、網絡等開始向用戶的端上發展;觀察的場景也從純粹的錯誤、慢請求等發展為用戶的實際產品體驗。
- 通用場景:觀測本質上是一個通用的行為,除了運維場景外,對于公司的安全、用戶行為、運營增長、交易等都適用,我們可以針對這些場景構建例如攻擊檢測、攻擊溯源、ABTest、廣告效果分析等應用形式。
- 特殊場景:除了場景的公司內通用場景外,針對不同的行業屬性,也可以衍生出特定行業的觀測場景與應用,例如阿里云的城市大腦,就是通過觀測道路擁堵、信號燈、交通事故等信息,通過控制不同紅綠燈時間、出行規劃等手段降低城市整體擁堵率。
四 、Pragmatic可觀測性如何落地
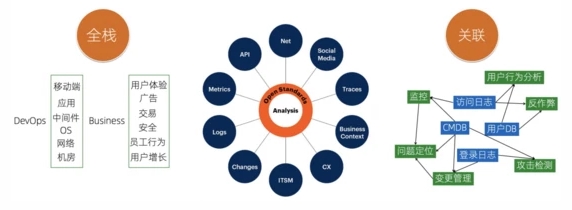
回到可觀測性方案落地上,我們現階段可能無法做出一個適用于各個行業屬性的可觀測引擎,更多的還是專注于DevOps和通用的公司商業方面。這里面的兩個核心工作是:
- 數據的覆蓋面足夠的全:能夠包括各類不同場景的不同類型的數據,除了狹義的日志、監控、Trace外,還需要包括我們的CMDB、變更數據、客戶信息、訂單/交易信息、網絡流、API調用等
- 數據關聯與統一分析:數據價值的發掘不是簡單的通過一種數據來實現,更多的時候我們需要利用多種數據關聯來達到目的,例如結合用戶的信息表以及訪問日志,我們可以分析不同年齡段、性別的用戶的行為特點,針對性的進行推薦;通過登錄日志、CMDB等,結合規則引擎,來實現安全類的攻擊檢測。

從整個流程來看,我們可以將可觀測性的工作劃分為4個組成部分:
- 傳感器:獲取數據的前提是要有足夠傳感器來產生數據,這些傳感器在IT領域的形態有:SDK、埋點、外部探針等。
- 數據:傳感器產生數據后,我們需要有足夠的能力去獲取、收集各種類型的數據,并把這些數據歸類分析。
- 算力:可觀測場景的核心是需要覆蓋足夠多的數據,數據一定是海量的,因此系統需要有足夠的算力來計算和分析這些數據。
- 算法:可觀測場景的終極應用是數據的價值發掘,因此需要使用到各類算法,包括一些基礎的數值類算法、各種AIOps相關的算法以及這些算法的組合。
五 、再論可觀測性數據分類
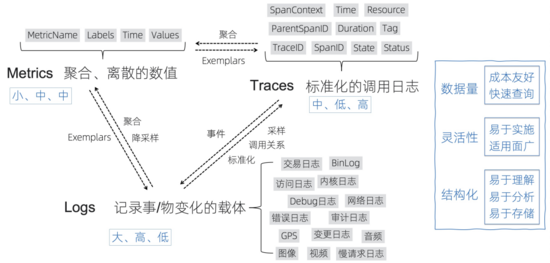
Logs、Traces、Metrics作為IT可觀測性數據的三劍客,基本可以滿足各類監控、告警、分析、問題排查等需求,然而實際場景中,我們經常會搞混每種數據的適用形態,這里再大致羅列一下這三類數據的特點、轉化方式以及適用場景:
- Logs:我們對于Logs是更加寬泛的定義:記錄事/物變化的載體,對于常見的訪問日志、交易日志、內核日志等文本型以及包括GPS、音視頻等泛型數據也包含在其中。日志在調用鏈場景結構化后其實可以轉變為Trace,在進行聚合、降采樣操作后會變成Metrics。
- Metrics:是聚合后的數值,相對比較離散,一般有name、labels、time、values組成,Metrics數據量一般很小,相對成本更低,查詢的速度比較快。
- Traces:是最標準的調用日志,除了定義了調用的父子關系外(一般通過TraceID、SpanID、ParentSpanID),一般還會定義操作的服務、方法、屬性、狀態、耗時等詳細信息,通過Trace能夠代替一部分Logs的功能,通過Trace的聚合也能得到每個服務、方法的Metrics指標。
六 、“割裂”的可觀測性方案

業界也針對這種情況推出了各類可觀察性相關的產品,包括開源、商業化的眾多項目。例如:
- Metrics:Zabbix、Nagios、Prometheus、InfluxDB、OpenFalcon、OpenCensus
- Traces:Jaeger、Zipkin、SkyWalking、OpenTracing、OpenCensus
- Logs:ELK、Splunk、SumoLogic、Loki、Loggly
利用這些項目的組合或多或少可以解決針對性的一類或者幾類問題,但真正應用起來你會發現各種問題:
- 多套方案交織:可能要使用至少Metrics、Logging、Tracing3種方案,維護代價巨大
- 數據不互通:雖然是同一個業務組件,同一個系統,產生的數據由于在不同的方案中,數據難以互通,無法充分發揮數據價值
在這種多套方案組合的場景下,問題排查需要和多套系統打交道,若這些系統歸屬不同的團隊,還需要和多個團隊進行交互才能解決問題,整體的維護和使用代價非常巨大。因此我們希望能夠使用一套系統去解決所有類型可觀測性數據的采集、存儲、分析的功能。
七 、可觀測性數據引擎架構
基于上述我們的一些思考,回歸到可觀測這個問題的本質,我們目標的可觀測性方案需要能夠滿足以下幾點:
- 數據全面覆蓋:包括各類的可觀測數據以及支持從各個端、系統中采集數據
- 統一的系統:拒絕割裂,能夠在一個系統中支持Traces、Metrics、Logs的統一存儲與分析
- 數據可關聯:每種數據內部可以互相關聯,也支持跨數據類型的關聯,能夠用一套分析語言把各類數據進行融合分析
- 足夠的算力:分布式、可擴展,面對PB級的數據,也能有足夠的算力去分析
- 靈活智能的算法:除了基礎的算法外,還應包括AIOps相關的異常檢測、預測類的算法,并且支持對這些算法進行編排
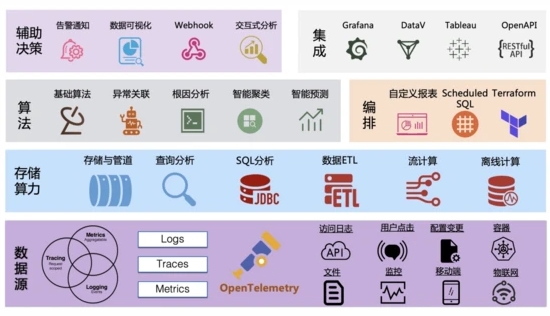
可觀測數據引擎的整體架構如下圖所示,從底到上的四層也基本符合方案落地的指導思想:傳感器+數據+算力+算法。
- 傳感器:數據源以OpenTelemetry為核心,并且支持各類數據形態、設備/端、數據格式的 采集 ,覆蓋面足夠的“廣”。
- 數據+算力:采集上來的數據,首先會進入到我們的 管道系統 (類似于Kafka),根據不同的數據類型構建不同的索引,目前每天我們的平臺會有幾十PB的新數據寫入并存儲下。除了常見的 查詢 和 分析 能力外,我們還內置了 ETL 的功能,負責對數據進行清洗和格式化,同時支持對接外部的流計算和離線計算系統。
- 算法:除了基礎的數值算法外,目前我們支持了十多種的 異常檢測/預測算法 ,并且還支持 流式異常檢測 ;同時也支持使用 Scheduled SQL 進行數據的編排,幫助我們產生更多新的數據。
- 價值發掘:價值發掘過程主要通過 可視化 、 告警 、 交互式分析 等人機交互來實現,同時也提供了 OpenAPI 來對接外部系統或者供用戶來實現一些自定義的功能。
八 、數據源與協議兼容
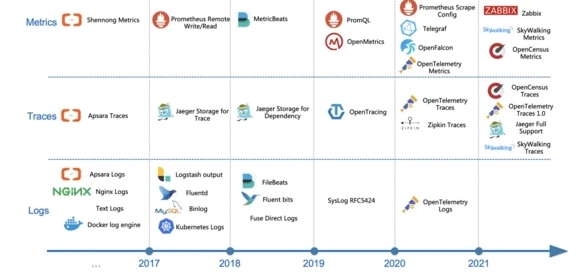
隨著阿里全面擁抱云原生后,我們也開始逐漸去兼容開源以及云原生的可觀測領域的協議和方案。相比自有協議的封閉模式,兼容開源、標準協議大大擴充了我們平臺能夠支持的數據采集范圍,而且減少了不必要的造輪子環節。上圖展示了我們兼容外部協議、Agent的整體進度:
- Traces:除了內部的飛天Trace、鷹眼Trace外,開源的包括Jaeger、OpenTracing、Zipkin、SkyWalking、OpenTelemetry、OpenCensus等。
- Logs:Logs的協議較少,但是設計比較多的日志采集Agent,我們平臺除了自研的Logtail外,還兼容包括Logstash、Beats(FileBeat、AuditBeat)、Fluentd、Fluent bits,同時還提供syslog協議,路由器交換機等可以直接用syslog協議上報數據到服務端。
- Metrics:時序引擎我們在新版本設計之初就兼容了Prometheus,并且支持Telegraf、OpenFalcon、OpenTelemetry Metrics、Zabbix等數據接入。
九 、統一存儲引擎
對于存儲引擎,我們的設計目標的第一要素是統一,能夠用一套引擎存儲各類可觀測的數據;第二要素是快,包括寫入、查詢,能夠適用于阿里內外部超大規模的場景(日寫入幾十PB)。

對于Logs、Traces、Metrics,其中Logs和Traces的格式和查詢特點非常相似,我們放到一起來分析,推導的過程如下:
Logs/Traces:
- 查詢的方式主要是通過關鍵詞/TraceID進行查詢,另外會根據某些Tag進行過濾,例如hostname、region、app等
- 每次查詢的命中數相對較少,尤其是TraceID的查詢方式,而且命中的數據極有可能是離散的
- 通常這類數據最適合存儲在搜索引擎中,其中最核心的技術是倒排索引
Metrics:
- 通常都是range查詢,每次查詢某一個單一的指標/時間線,或者一組時間線進行聚合,例如統一某個應用所有機器的平均CPU
- 時序類的查詢一般QPS都較高(主要有很多告警規則),為了適應高QPS查詢,需要把數據的聚合性做好
- 對于這類數據都會有專門的時序引擎來支撐,目前主流的時序引擎基本上都是用類似于LSM Tree的思想來實現,以適應高吞吐的寫入和查詢(Update、Delete操作很少)
同時可觀測性數據還有一些共性的特點,例如高吞吐寫入(高流量、QPS,而且會有Burst)、超大規模查詢特點、時間訪問特性(冷熱特性、訪問局部性等)。
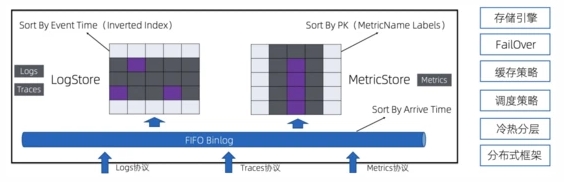
針對上述的特性分析,我們設計了一套統一的可觀測數據存儲引擎,整體架構如下:
- 接入層支持各類協議寫入,寫入的數據首先會進入到一個FIFO的管道中,類似于Kafka的MQ模型,并且支持數據消費,用來對接各類下游
- 在管道之上有兩套索引結構,分別是倒排索引以及SortedTable,分別為Traces/Logs和Metrics提供快速的查詢能力
- 兩套索引除了結構不同外,其他各類機制都是共用的,例如存儲引擎、FailOver邏輯、緩存策略、冷熱數據分層策略等
- 上述這些數據都在同一個進程內實現,大大降低運維、部署代價
- 整個存儲引擎基于純分布式框架實現,支持橫向擴展,單個Store最多支持日PB級的數據寫入
十 、統一分析引擎

如果把存儲引擎比喻成新鮮的食材,那分析引擎就是處理這些食材的刀具,針對不同類型的食材,用不同種類的刀來處理才能得到最好的效果,例如蔬菜用切片刀、排骨用斬骨刀、水果用削皮刀等。同樣針對不同類型的可觀測數據和場景,也有對應的適合的分析方式:
- Metrics:通常用于告警和圖形化展示,一般直接獲取或者輔以簡單的計算,例如PromQL、TSQL等
- Traces/Logs:最簡單直接的方式是關鍵詞的查詢,包括TraceID查詢也只是關鍵詞查詢的特例
- 數據分析(一般針對Traces、Logs):通常Traces、Logs還會用于數據分析和挖掘,所以要使用圖靈完備的語言,一般程序員接受最廣的是SQL
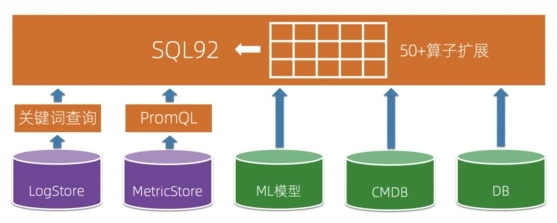
上述的分析方式都有對應的適用場景,我們很難用一種語法/語言去實現所有的功能并且具有非常好的便捷性(雖然通過擴展SQL可以實現類似PromQL、關鍵詞查詢的能力,但是寫起來一個簡單的PromQL算子可能要用一大串SQL才能實現),因此我們的分析引擎選擇去兼容關鍵詞查詢、PromQL的語法。同時為了便于將各類可觀測數據進行關聯起來,我們在SQL的基礎上,實現了可以連接關鍵詞查詢、PromQL、外部的DB、ML模型的能力,讓SQL成為頂層分析語言,實現可觀測數據的融合分析能力。
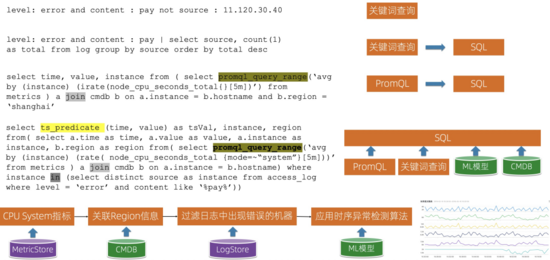
下面舉幾個我們的查詢/分析的應用示例,前面3個相對比較簡單,可以用純粹的關鍵詞查詢、PromQL,也可以結合SQL一起使用。最后一個展示了實際場景中進行融合分析的例子:
- 背景:線上發現有支付失敗的錯誤,需要分析這些出現支付失敗的錯誤的機器CPU指標有沒有問題
- 實現:首先查詢機器的CPU指標;關聯機器的Region信息(需要排查是否某個Region出現問題);和日志中出現支付失敗的機器進行Join,只關心這些機器;最后應用時序異常檢測算法來快速的分析這些機器的CPU指標;最后的結果使用線圖進行可視化,結果展示更加直觀。
上述的例子同時查詢了LogStore、MetricStore,而且關聯CMDB以及ML模型,一個語句實現了非常復雜的分析效果,在實際的場景中還是經常出現的,尤其是分析一些比較復雜的應用和異常。
十一、數據編排
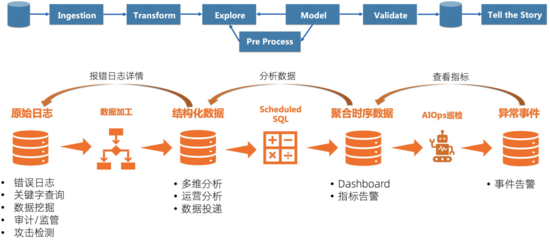
可觀測性相比傳統監控,更多的還是在于數據價值的發掘能力更強,能夠僅通過輸出來推斷系統的運行狀態,因此和數據挖掘這個工作比較像,收集各類繁雜的數據、格式化、預處理、分析、檢驗,最后根據得到的結論去“講故事”。因此在可觀測性引擎的建設上,我們非常關注數據編排的能力,能夠讓數據流轉起來,從茫茫的原始日志中不斷的去提取出價值更高的數據,最終告訴我們系統是否在工作以及為什么不工作。為了讓數據能夠“流轉”起來,我們開發了幾個功能:
- 數據加工:也就是大數據ETL(extract, transform, and load)中T的功能,能夠幫我們把非結構化、半結構化的數據處理成結構化的數據,更加容易分析。
- Scheduled SQL:顧名思義,就是定期運行的SQL,核心思想是把龐大的數據精簡化,更加利于查詢,例如通過AccessLog每分鐘定期計算網站的訪問請求、按APP、Region粒度聚合CPU、內存指標、定期計算Trace拓撲等。
- AIOps巡檢:針對時序數據特別開發的基于時序異常算法的巡檢能力,用機器和算力幫我們去檢查到底是哪個指標的哪個維度出現問題。
十二、可觀測性引擎應用實踐
目前我們這套平臺上已經積累了10萬級的內外部用戶,每天寫入的數據40PB+,非常多的團隊在基于我們的引擎在構建自己公司/部門的可觀測平臺,進行全棧的可觀測和業務創新。下面將介紹一些常見的使用我們引擎的場景:
1 全鏈路可觀測
全鏈路的可觀測性一直都是DevOps環節中的重要步驟,除了通常的監控、告警、問題排查外,還承擔用戶行為回放/分析、版本發布驗證、A/B Test等功能,下圖展示的是阿里內部某個產品內部的全鏈路可觀測架構圖:
- 數據源包括移動端、Web端、后端的各類數據,同時還包括一些監控系統的數據、第三方的數據等
- 采集通過SLS的Logtail和TLog實現
- 基于離在線混合的數據處理方式,對數據進行打標、過濾、關聯、分發等預處理
- 各類數據全部存儲在SLS可觀測數據引擎中,主要利用SLS提供的索引、查詢和聚合分析能力
- 上層基于SLS的接口構建全鏈路的數據展示和監控系統

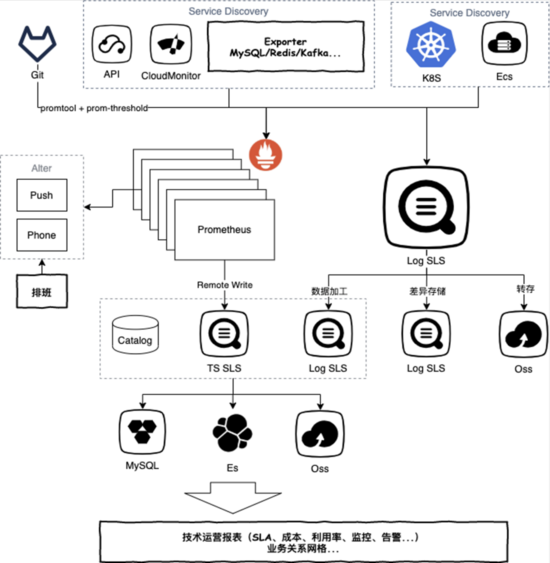
2 成本可觀測
商業公司的第一要務永遠是營收、盈利,我們都知道盈利=營收-成本,IT部門的成本通常也會占據很大一個部分,尤其是互聯網類型的公司。現在阿里全面云化后,包括阿里內部的團隊也會在乎自己的IT支出,盡可能的壓縮成本。下面的示例是我們阿里云上一家客戶的監控系統架構,系統除了負責IT基礎設施和業務的監控外,還會負責分析和優化整個公司的IT成本,主要收集的數據有:
- 收集云上每個產品(虛擬機、網絡、存儲、數據庫、SaaS類等)的費用,包括詳細的計費信息
- 收集每個產品的監控信息,包括用量、利用率等
- 建立起Catalog/CMDB,包括每個資源/實例所屬的業務部門、團隊、用途等
利用Catalog + 產品計費信息,就可以計算出每個部門的IT支出費用;再結合每個實例的用量、利用率信息,就可以計算出每個部門的IT資源利用率,例如每臺ECS的CPU、內存使用率。最終計算出每個部門/團隊整體上使用IT資源的合理度,將這些信息總結成運營報表,推動資源使用合理度低的部門/團隊去優化。
3 Trace可觀測
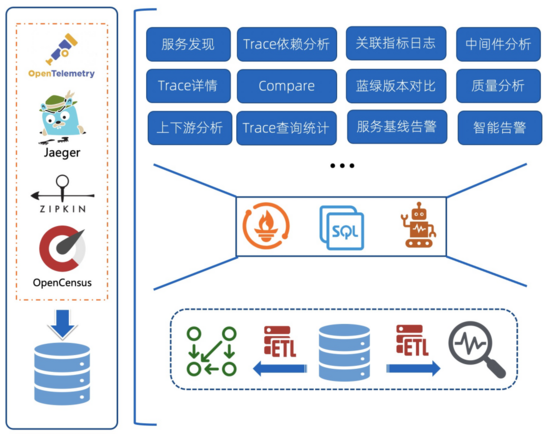
隨著云原生、微服務逐漸在各個行業落地,分布式鏈路追蹤(Trace)也開始被越來越多的公司采用。對于Trace而言,最基礎的能力是能夠記錄請求在多個服務之間調用的傳播、依賴關系并進行可視化。而從Trace本身的數據特點而言,它是規則化、標準化且帶有依賴關系的訪問日志,因此可以基于Trace去計算并挖掘更多的價值。
下面是SLS OpenTelemetry Trace的實現架構,核心是通過數據編排計算Trace原始數據并得到聚合數據,并基于SLS提供的接口實現各類Trace的附加功能。例如:
- 依賴關系:這是絕大部分的Trace系統都會附帶的功能,基于Trace中的父子關系進行聚合計算,得到Trace Dependency
- 服務/接口黃金指標:Trace中記錄了服務/接口的調用延遲、狀態碼等信息,基于這些數據可以計算出QPS、延遲、錯誤率等黃金指標。
- 上下游分析:基于計算的Dependency信息,按照某個Service進行聚合,統一Service依賴的上下游的指標
- 中間件分析:Trace中對于中間件(數據庫/MQ等)的調用一般都會記錄成一個個Span,基于這些Span的統計可以得到中間件的QPS、延遲、錯誤率。
- 告警相關:通常基于服務/接口的黃金指標設置監控和告警,也可以只關心整體服務入口的告警(一般對父Span為空的Span認為是服務入口調用)。
4 基于編排的根因分析
可觀測性的前期階段,很多工作都是需要人工來完成,我們最希望的還是能有一套自動化的系統,在出現問題的時候能夠基于這些觀測的數據自動進行異常的診斷、得到一個可靠的根因并能夠根據診斷的根因進行自動的Fix。現階段,自動異常恢復很難做到,但根因的定位通過一定的算法和編排手段還是可以實施的。
下圖是一個典型的IT系統架構的觀測抽象,每個APP都會有自己的黃金指標、業務的訪問日志/錯誤日志、基礎監控指標、調用中間件的指標、關聯的中間件自身指標/日志,同時通過Trace還可以得到上下游APP/服務的依賴關系。通過這些數據再結合一些算法和編排手段就可以進行一定程度的自動化根因分析了。這里核心依賴的幾點如下:
- 關聯關系:通過Trace可以計算出APP/服務之間的依賴關系;通過CMDB信息可以得到APP和PaaS、IaaS之間的依賴關系。通過關聯關系就可以“順藤摸瓜”,找到出現問題的原因。
- 時序異常檢測算法:自動檢測某一條、某組曲線是否有異常,包括ARMA、KSigma、Time2Graph等,詳細的算法可以參考: 異常檢測算法 、 流式異常檢測 。
- 日志聚類分析: 將相似度高的日志聚合,提取共同的日志模式(Pattern),快速掌握日志全貌,同時 利用Pattern的對比功能,對比正常/異常時間段的Pattern,快速找到日志中的異常。
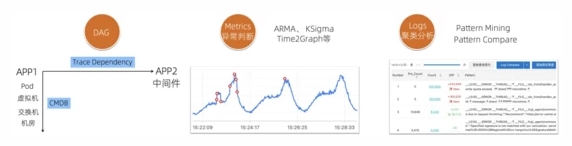
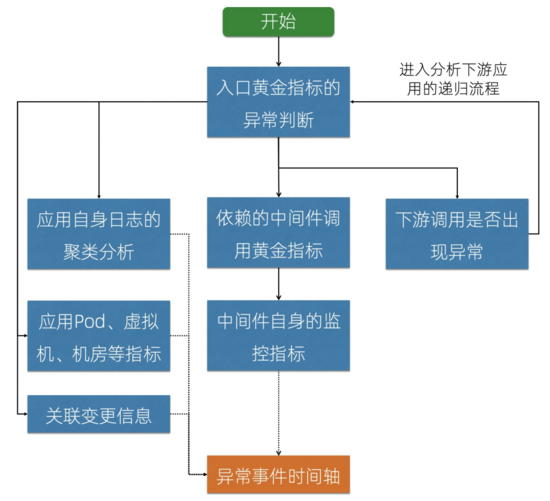
時序、日志的異常分析能夠幫我們確定某個組件是否存在問題,而關聯關系能夠讓我們進行“順藤摸瓜”。通過這三個核心功能的組合就可以編排出一個異常的根因分析系統。下圖就是一個簡單的示例:首先從告警開始分析入口的黃金指標,隨后分析服務本身的數據、依賴的中間件指標、應用Pod/虛擬機指標,通過Trace Dependency可以遞歸分析下游依賴是否出現問題,其中還可以關聯一些變更信息,以便快速定位是否由于變更引起的異常。最終發現的異常事件集中到時間軸上進行推導,也可以由運維/開發來最終確定根因。
十三、寫在最后
可觀測性這一概念并不是直接發明的“黑科技”,而是我們從監控、問題排查、預防等工作中逐漸“演化”出來的詞。同樣我們一開始只是做日志引擎(阿里云上的產品: 日志服務 ),在隨后才逐漸優化、升級為可觀測性的引擎。對于“可觀測性”我們要拋開概念/名詞本身來發現它的本質,而這個本質往往是和商業(Business)相關,例如:
- 讓系統更加穩定,用戶體驗更好
- 觀察IT支出,消除不合理的使用,節省更多的成本
- 觀察交易行為,找到刷單/作弊,即時止損
- 利用AIOps等自動化手段發現問題,節省更多的人力,運維提效
而我們對于可觀測性引擎的研發,主要關注的也是如何服務更多的部門/公司進行可觀測性方案的快速、有效實施。包括引擎中的傳感器、數據、計算、算法等工作一直在不斷進行演進和迭代,例如更加便捷的eBPF采集、更高壓縮率的數據壓縮算法、性能更高的并行計算、召回率更低的根因分析算法等。
























