還在用ES?事實(shí)證明ClickHouse更強(qiáng)悍
在日常工作中,我們通常需要存儲(chǔ)一些日志,譬如用戶請求的出入?yún)ⅰ⑾到y(tǒng)運(yùn)行時(shí)打印的一些 info、error 之類的日志,從而對系統(tǒng)在運(yùn)行時(shí)出現(xiàn)的問題有排查的依據(jù)。
圖片來自 包圖網(wǎng)
日志存儲(chǔ)和檢索是個(gè)很常見且簡單的工作,市面也有很多關(guān)于日志搜集、存儲(chǔ)、檢索的框架可供使用。
譬如我們只有個(gè)位數(shù)機(jī)器時(shí),可以通過登錄服務(wù)器,查看 Log4j 之類的框架打印到本地文件的日志。當(dāng)日志多起來后,可以用 ELK 三劍客處理日志。
當(dāng)日志量進(jìn)一步增多,我們可以上消息隊(duì)列,譬如 Kafka 之類來承接,然后消費(fèi)入庫。或者寫本地文件,再采用 Filebeat 之類上報(bào)再入庫。
以上都是較為常見的日志傳輸和存儲(chǔ)的方案,成本可控的情況下,可適用于絕大多數(shù)場景。
我們可以簡單總結(jié)一下日志框架的功能,大概是暫存、傳輸、入庫保存、快速檢索。
量級(jí)上升,成本高昂
技術(shù)方案的設(shè)計(jì)和取舍,往往強(qiáng)受限于成本。當(dāng)成本高企到難以承受時(shí),將必須導(dǎo)致技術(shù)方案的升級(jí)換代。那么問題來了,我就是存?zhèn)€日志而已,怎么就成本難以承受了呢?
我們以一個(gè)常見的日志傳輸及存儲(chǔ)方案來舉例,如下圖,暫存就是采用客戶端寫本地文件存日志,傳輸即是采用 MQ,消費(fèi)入庫常見的如 ES。
下圖方案,為了減少部分存儲(chǔ)成本,將日志詳情存儲(chǔ)于壓縮更好的 Hbase,僅將查詢時(shí)需要的一些索引字段放在了 ES。
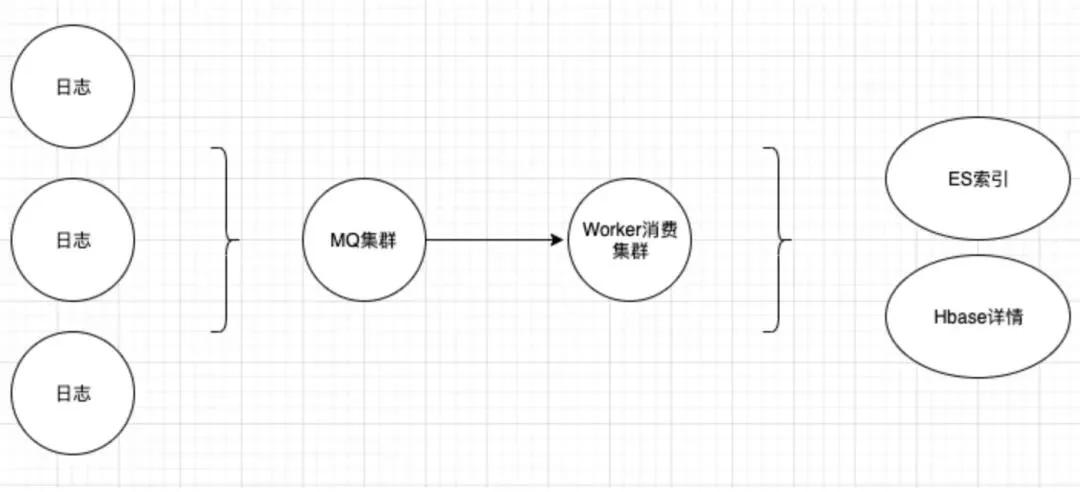
以上作為一個(gè)常用的方案,為什么會(huì)成本高昂呢?
我們來簡單計(jì)算一下,京東 App 某個(gè)模塊(是一個(gè)模塊,非整個(gè) App 累計(jì)),單次用戶請求,用戶的入?yún)?返回值+流程中打印的日志占用的大小在 40k-2M 之間,中位數(shù)在 60k 左右。
該模塊日常每秒約 2-5 萬次訪問,高峰時(shí)會(huì)翻 10 倍,極高峰可達(dá)百萬。
以 3 萬每秒來算,產(chǎn)生的日志大小為 1.8G,也就是說即便是低負(fù)載時(shí),這個(gè)日志框架要吞下 1.8G 的傳輸與存儲(chǔ)。
但這是遠(yuǎn)遠(yuǎn)不夠的,因?yàn)槲覀兗幢惴艞墭O高峰,僅僅支撐偶現(xiàn)的高峰,也需要該系統(tǒng)能支撐秒級(jí) 15G 以上的吞吐。但是這僅僅才是一個(gè)模塊而已,算上前中臺(tái)這樣的模塊還有很多。
那么我們就可以來算一算了,一秒 1.5 G,一個(gè)小時(shí)就是 5.4TB。小高峰是肯定要支撐的,也就是秒級(jí) 30 萬是要保的,那么我們的系統(tǒng)就要能支撐秒級(jí) 15G 單模塊,算上各模塊,200G 秒級(jí)是跑不了了。
這只是各個(gè)機(jī)器所打印在各自本地的原始日志文件占用的大小,然后要發(fā)到 MQ 集群。
大家都知道,MQ 也是寫磁盤的,這 200G 一點(diǎn)不少的在 MQ 機(jī)器上做了保存,并且 MQ 還有備份機(jī)制。
就以最簡陋的單備份來說,MQ 每秒要承接 400G 的磁盤,并且離刪除后釋放磁盤還有挺長一段時(shí)間,哪怕只存 1 個(gè)小時(shí),也是一個(gè)巨大的數(shù)字。
我們知道,一般服務(wù)器在磁盤還不錯(cuò)的情況下,單機(jī)秒級(jí)寫入量 200 多 M 算比較不錯(cuò)的情況,通過上面的了解,我們僅僅做到日志的暫存和傳輸就需要 2000 臺(tái)以上的服務(wù)器資源。
然后就到了 worker 消費(fèi)集群,該集群只是純粹的內(nèi)存數(shù)據(jù)交換,不占磁盤,worker 消費(fèi)后寫入數(shù)據(jù)庫。大家基本可以想象到,數(shù)據(jù)庫的占用是如何。
OK,我們終于把數(shù)據(jù)存了進(jìn)去,查詢問題就成了另外一個(gè)必須面對的事情,如何快速從無數(shù)億中找到你要查詢的那個(gè)用戶的鏈路日志。
到了此時(shí),成本就成了非常要命的事情,尤其方案的設(shè)計(jì),會(huì)導(dǎo)致原本就很龐大的數(shù)據(jù),在鏈路上再次放大多倍,那么巨大的硬件成本如何解決。
縮短流程,縮減流量
通過上面的分析,我們已經(jīng)發(fā)現(xiàn),即便是市面上最通用的日志方案,在如此巨大的流量面前,也難以持續(xù)下去,高昂的硬件成本,將迫使我們?nèi)ふ腋线m的技術(shù)方案。
世界上有一個(gè)著名的法則叫"奧卡姆剃刀定律",講的是程序員該如何選擇合適的剃刀,來讓自己的秀發(fā)光滑柔順有光澤。
其實(shí)不是的,該定律主要就是八個(gè)字"如無必要,勿增實(shí)體"。當(dāng)一個(gè)流程難以支撐當(dāng)前的業(yè)務(wù)時(shí),我們就該審視一下,哪些步驟是不必要的。
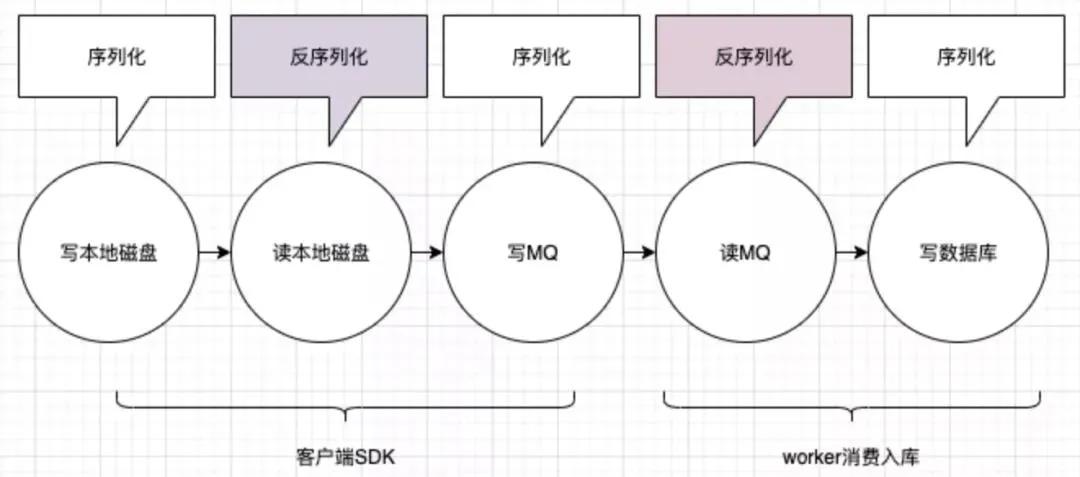
從這個(gè)通用流程中,其實(shí)我們很容易就能發(fā)現(xiàn),我們經(jīng)歷了很多讀寫,每次讀寫都伴隨著磁盤的讀寫(包括 MQ 也是寫磁盤的),和頻繁的序列化反序列化,以及翻倍的網(wǎng)絡(luò) IO。
那么讓我們揮舞起奧卡姆的剃刀,做一些刪減,把非必要的部分給刪掉,就變成了下圖的流程:
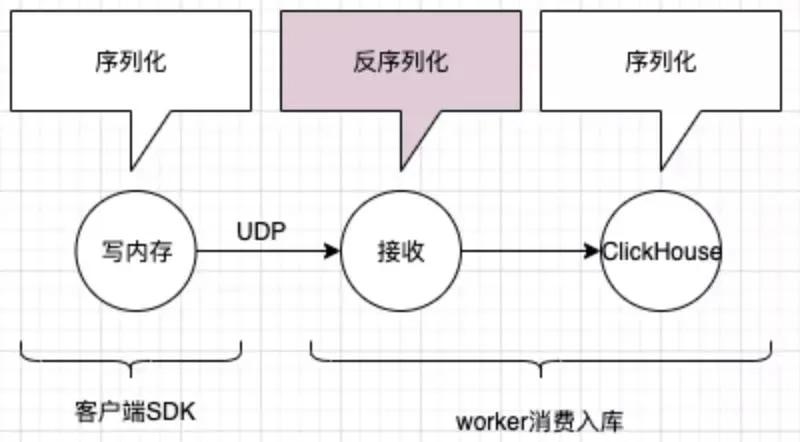
我們發(fā)現(xiàn),其實(shí)寫本地磁盤、和 MQ 都是沒有必要的,我們完全可以將日志數(shù)據(jù)寫到本地內(nèi)存,然后搞個(gè)線程,定時(shí)通過 UDP 將日志直接發(fā)送到 worker 端即可。
worker 接收到之后,解析一下,寫入自己的內(nèi)存隊(duì)列,再起數(shù)個(gè)異步線程,批量將隊(duì)列的數(shù)據(jù)寫入 ClickHouse 數(shù)據(jù)庫即可。
大家可能看到了,下圖的流程中,那個(gè)圓圈明顯比上圖的圓圈要小,這是為什么呢?因?yàn)槲易隽藟嚎s。
前文講過,我們單條報(bào)文 40k-2M,這是一個(gè)非常大的報(bào)文,這里面都是一些用戶請求的入?yún)?Json 和出參 Json 以及一些中途日志,我們完全沒有必要將原文原封不動(dòng)往外傳輸。
通過采用主流的 snappy、zstd 等壓縮工具類,可以直接將字符串壓縮成 byte[] 再往外傳輸,這個(gè)被壓縮后的字符串,直至入庫都是 byte[],全程不對大報(bào)文解壓。
那么這個(gè)壓縮能壓多少呢,80%-90%,一個(gè) 60k 的報(bào)文,往外送時(shí)就剩 6-8k 了,可想而知,僅僅壓縮一下原始數(shù)據(jù),就在整個(gè)流程中,節(jié)省了巨大的帶寬,同時(shí)也大幅提升了 worker 的吞吐量。
這里有個(gè)小細(xì)節(jié),udp 單個(gè)最大報(bào)文是 64kb,如果我們壓縮后,還是超過了 64kb 的話,udp 是送不出去的,這里可以選擇發(fā)個(gè) http 請求送到 worker 即可。
通過上圖,我們可以看到,當(dāng)流程中的某些環(huán)節(jié)并不是必需的時(shí),我們應(yīng)該果斷砍掉,不要輕易照搬網(wǎng)上的方案,而應(yīng)該選擇更適合自己的方案。下面我們詳細(xì)講一下系統(tǒng)是如何設(shè)計(jì)、運(yùn)轉(zhuǎn)的。
更強(qiáng)悍的日志搜集系統(tǒng)
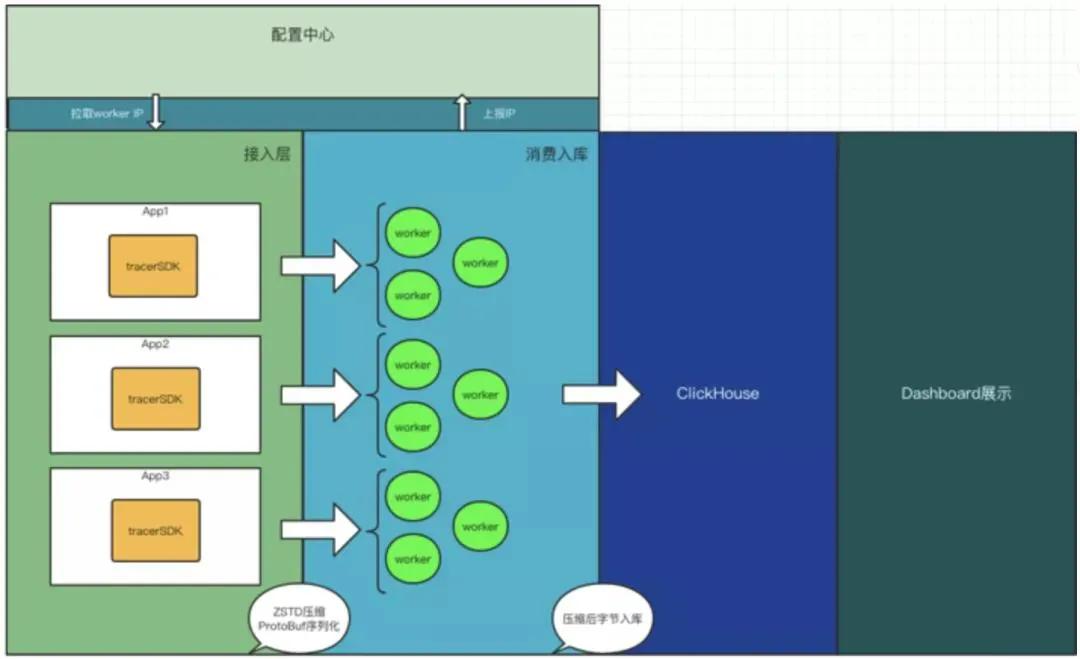
我們來審視一下這個(gè)鏈路極短的日志搜集系統(tǒng):
- 配置中心:用來存儲(chǔ) worker 的 IP 地址,供客戶端獲取自己模塊所分配的 worker 集群的 ip。
- client:客戶端啟動(dòng)后,從配置中心拉取分配給自己這個(gè)模塊的 worker 集群的 IP,并輪詢將搜集的日志壓縮后發(fā)送過去,通過 UDP 的方式。
- worker:每個(gè)模塊會(huì)分配數(shù)量不等的 worker 機(jī)器,啟動(dòng)后上報(bào)自己的 IP 地址到配置中心。接受到客戶端發(fā)來的日志后,解析相應(yīng)的字段,批量寫入 clickhouse 數(shù)據(jù)庫。
- clickhouse:一個(gè)強(qiáng)大的數(shù)據(jù)庫,壓縮比很高,寫入性能極強(qiáng),按天分片,查詢速度佳。非常適合應(yīng)用于日志系統(tǒng)這種寫入極大,查詢較少的系統(tǒng)。
- dashboard:可視化界面,從 clickhouse 查詢數(shù)據(jù)展示給用戶,具有多條件多維度查詢功能。
大家都能看出來,這其中最關(guān)鍵的地方是 worker 端,它的承接流量、消費(fèi)性能、入庫性能將決定著整個(gè)鏈路能否良好地運(yùn)轉(zhuǎn)。
我們主要分別講解一下 client 端和 worker 端的實(shí)現(xiàn)。
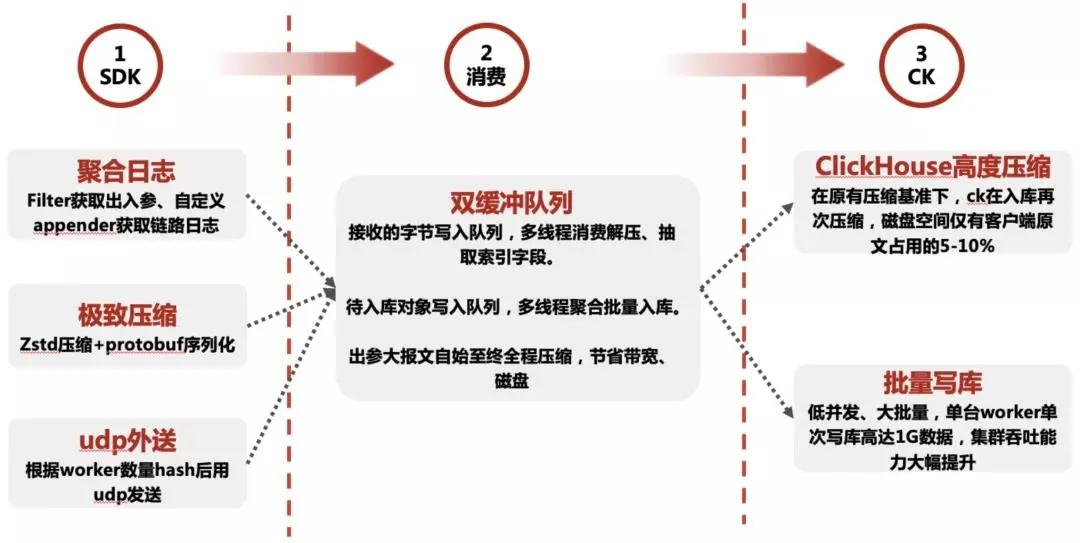
Client 端聚合日志
一次請求中,我們通常要保留的日志信息主要有:
①請求的出入?yún)?/h3>
如果是 http web 應(yīng)用,要獲取出入?yún)⒈容^簡單的方式就是通過自定義 filter 即可。client 的 sdk 里定義了一個(gè) filter,接入方通過配置該 filter 生效即可搜集到出入?yún)ⅰ?/p>
如果是其他 rpc 應(yīng)用非 http 請求的,也提供了對應(yīng)的 filter 攔截器來獲取出入?yún)ⅰ?/p>
在獲取到出入?yún)⒑螅瑂dk 對其中大報(bào)文,主要是出參進(jìn)行了壓縮,并將整個(gè)數(shù)據(jù)定義為一個(gè) Java 對象,做 protobuf 序列化,通過 UDP 方式往自己對應(yīng)的 worker 集群輪詢傳輸。
②鏈路上自己打印的一些關(guān)鍵信息,如調(diào)用其他系統(tǒng)的的出入?yún)ⅲ约捍蛴〉囊恍?info、error 信息
sdk 分別提供了 log4j、logback、log4j2 三個(gè)常用日志框架的自定義 appender。
用戶可以通過在自己的日志配置文件(如 logback.xml)中,將我自定義的 appender 定義出來即可,那么后續(xù)用戶在代碼里所有打印的 info、error 等日志都會(huì)執(zhí)行這個(gè)自定義 appender。
同樣,這個(gè)自定義 appender 也是將日志暫存內(nèi)存,然后異步 UDP 外送到 worker。
這里主要有兩個(gè)地方需要注意,一是當(dāng)壓縮后的報(bào)文依舊超出 udp 最大報(bào)文值時(shí),即通過 http 送出。
二是這一次請求,鏈路中可能會(huì)使用多線程、線程池技術(shù),為避免鏈路 tracer 的唯一 id 在線程池丟失,sdk 采用了 TransmittableThreadLocal 來保持鏈路的 ID,這個(gè)查一下就懂。
總體來說,client 端實(shí)現(xiàn)較為簡單,省略了寫本地磁盤、消費(fèi)文件發(fā) MQ 等等步驟。
整體只有一次 Protobuf 序列化操作,對 CPU、接入方性能影響極小,采用 UDP 外送,不需要 worker 的任何回復(fù),也不用考慮 tcp 模式下 worker 消費(fèi)慢導(dǎo)致自己阻塞的問題。整體非常簡潔高效。
Worker 端消費(fèi)日志并入庫
worker 端是調(diào)優(yōu)的重點(diǎn),由于要接收海量客戶端發(fā)來的日志,解析后入庫,所以 worker 需要具備很強(qiáng)的緩沖能力。
我們都能看出來,系統(tǒng)的瓶頸點(diǎn)肯定在入庫這個(gè)階段,解析日志,抽取字段都是效率很高的,而且完全可以通過控制線程的數(shù)量來控制住,而入庫將強(qiáng)受限于 clickhouse 的寫入性能。
至于 clickhouse 是如何做的優(yōu)化,后面會(huì)有 clickhouse 集群負(fù)責(zé)人來講一下做了哪些優(yōu)化。
為了做好這個(gè)緩沖,即便日志接收量大于入庫量,我們也要能接下來這些數(shù)據(jù),盡量不丟失。
首先硬件上,采用大內(nèi)存機(jī)器,8 核 32G 的容器,來盡量多屯一些數(shù)據(jù)。其次,采用了雙緩沖隊(duì)列,先將所有接收的數(shù)據(jù)放一個(gè)隊(duì)列,然后多線程消費(fèi)、解析成可供入庫的行數(shù)據(jù),再放入一個(gè)待入庫隊(duì)列,然后批量入庫。
那么我們做的這些操作,能支撐什么樣的數(shù)據(jù)量呢?
通過線上的應(yīng)用和嚴(yán)苛的壓測,這樣一臺(tái)單機(jī) docker 容器,每秒可以處理原始日志 1-5 千萬行。
譬如一條用戶請求,中途產(chǎn)生了共計(jì) 1 千多行日志,那么這樣的一臺(tái) worker 單機(jī),每秒可以處理 2 萬客戶端 QPS。對外寫 clickhouse 數(shù)據(jù)庫,每秒可以寫 160M-200M 比較穩(wěn)定。
通過對上文的了解,我們知道,這些數(shù)據(jù)都是被壓縮過的,直至庫里面的都是壓縮過的,只有當(dāng)最終用戶查詢時(shí),才會(huì)進(jìn)行解壓。所以,這 200M,基本相當(dāng)于原始數(shù)據(jù) 1G 多的大小。
也就是說,只要 clickhouse 寫入速度跟的上,這個(gè)系統(tǒng)僅需 100 臺(tái)就可以極其高效地處理原始秒級(jí)百 G 的日志。
對比寫 MQ 的方案,中途所有會(huì)出現(xiàn)瓶頸的點(diǎn)如 MQ 寫磁盤速度、消費(fèi)拉取速度等,都將不復(fù)存在。這是一個(gè)純內(nèi)存交換的鏈路系統(tǒng)。
強(qiáng)悍的 Clickhouse
通過以上的了解,我們可以清楚的看到,worker 作為一個(gè)純內(nèi)存計(jì)算的組件,client 端通過 worker 的數(shù)量進(jìn)行 hash 均勻分發(fā)到各個(gè) worker。
所以 worker 可以動(dòng)態(tài)擴(kuò)容而且不存在性能瓶頸,其唯一受限制的就是寫入庫的速度。
倘若寫庫速度跟不上,則 worker 必須要拿有限的內(nèi)存去屯下發(fā)來的大量數(shù)據(jù),一旦寫滿則就會(huì)開始丟棄接收到的數(shù)據(jù)。所以整個(gè)系統(tǒng)的瓶頸點(diǎn),就是寫庫的速度。
Clickhouse 是面向海量數(shù)據(jù)實(shí)時(shí)、多維分析、高性能的新一代 OLAP 數(shù)據(jù)庫管理系統(tǒng),實(shí)現(xiàn)了向量化執(zhí)行和 SIMD 指令,對內(nèi)存中的列式數(shù)據(jù),一個(gè) batch 調(diào)用一次 SIMD 指令,大幅縮短了計(jì)算耗時(shí),帶來數(shù)倍的性能提升。
目前已成為驅(qū)動(dòng)京東集團(tuán)業(yè)務(wù)增長、創(chuàng)新的“超級(jí)引擎”。那么在京東 App 秒級(jí)百 G 日志傳輸存儲(chǔ)架構(gòu)中,Clickhouse 如何支撐大吞吐量數(shù)據(jù)的寫入?
主要在于以下兩點(diǎn):
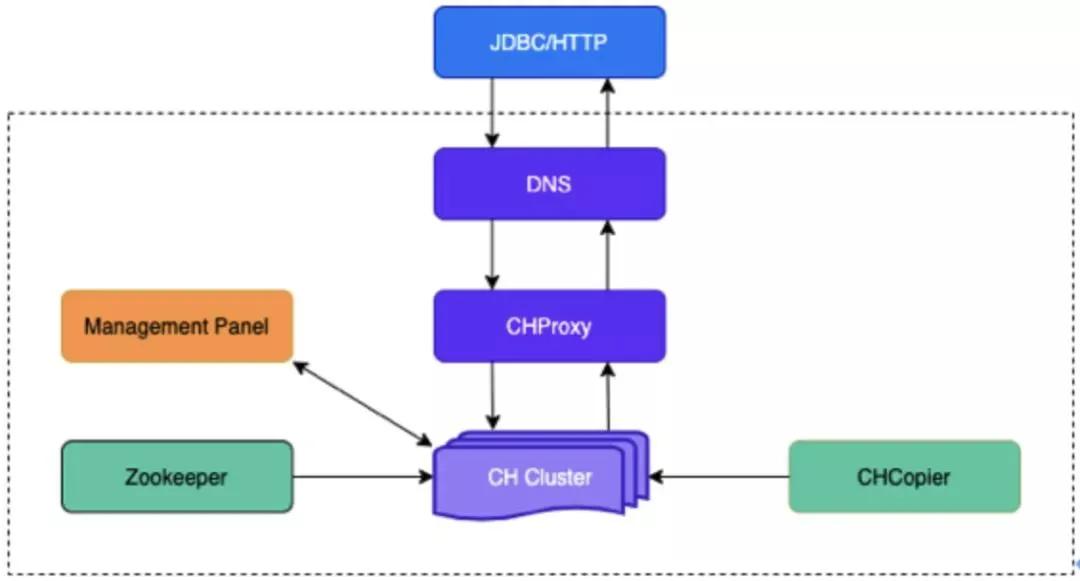
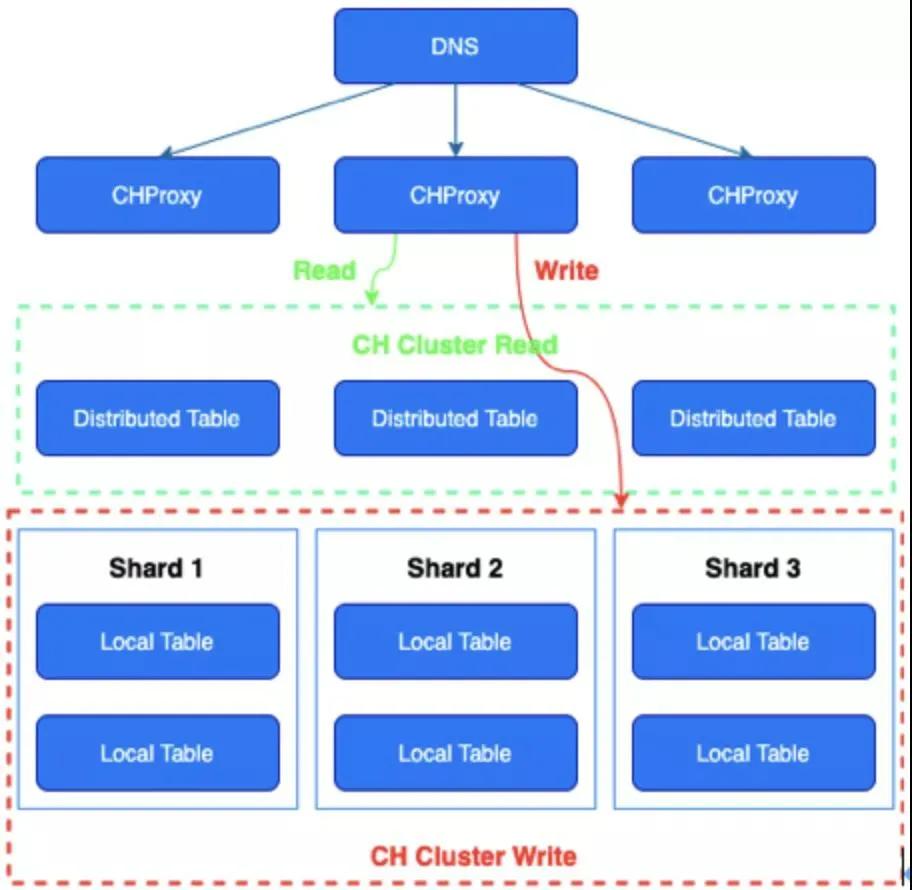
①集群高可用架構(gòu)
EasyOLAP 部署 CH 集群是三層結(jié)構(gòu):域名+CHProxy+CH 節(jié)點(diǎn),域名轉(zhuǎn)發(fā)請求到 CHProxy,再由 CHProxy 根據(jù)集群節(jié)點(diǎn)狀態(tài)來轉(zhuǎn)發(fā)。
CHProxy 的引入是為了讓 Query 均勻分布在每個(gè)節(jié)點(diǎn)上,,并對 CHProxy 做了一定的改進(jìn),自動(dòng)感知集群節(jié)點(diǎn)的狀態(tài)變化。
②本地表寫入
大吞吐量的數(shù)據(jù)寫入分布式表時(shí),分布式表會(huì)將接收的 insert 數(shù)據(jù)拆分成多個(gè) parts,并通過 rand 或者 shard_key 方式轉(zhuǎn)發(fā)到各個(gè)分片。
這會(huì)引起 ch 節(jié)點(diǎn)網(wǎng)絡(luò)帶寬和 merge 的工作量增加,導(dǎo)致寫入性能下降,并且會(huì)增加 too many parts 的風(fēng)險(xiǎn)和加大 zookeeper 的壓力。
另外數(shù)據(jù)會(huì)在分布式表所在節(jié)點(diǎn)進(jìn)行臨時(shí)落盤,然后異步的發(fā)送到本地表所在的節(jié)點(diǎn)進(jìn)行物理存儲(chǔ),中間沒有一致性校驗(yàn),如果分布式表所在的節(jié)點(diǎn)出現(xiàn)故障,會(huì)存在數(shù)據(jù)丟失的風(fēng)險(xiǎn)。
所以針對以上風(fēng)險(xiǎn),大吞吐量的數(shù)據(jù)可直接寫入本地表,相較于寫入分布式表可以大幅度提升 2-3 倍的寫入性能。
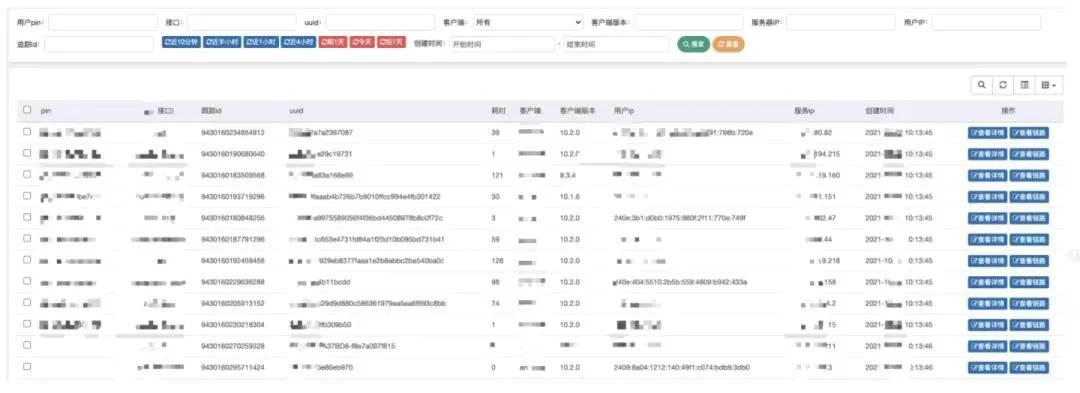
多條件查詢控制臺(tái)
控制臺(tái)比較簡單,主要就是做一些 sql 語句查詢,做好 clickhouse 的高效查詢,這里簡單提一些知識(shí)點(diǎn)。
做好數(shù)據(jù)的分片,如按天分片。用好 prewhere 查詢功能,可以帶來性能的提升。做好索引字段的設(shè)計(jì),譬如檢索常用的時(shí)間、pin。
細(xì)節(jié)難以盡述,要從百億千億數(shù)據(jù)中,做好極速的查詢,還需要對 clickhouse 的一些查詢特性有所了解。
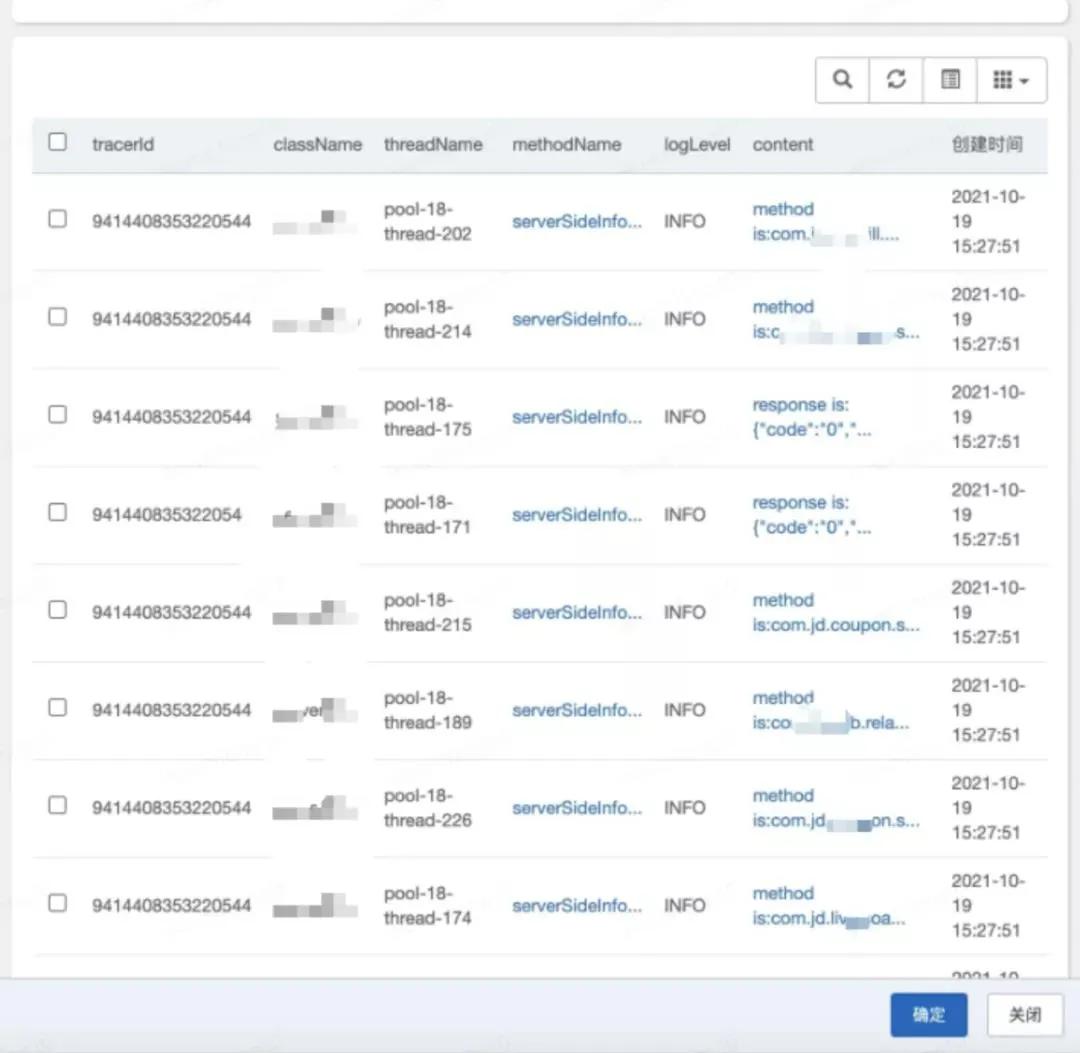
下圖界面展示的即為一些索引項(xiàng),點(diǎn)擊查看詳情,則從數(shù)據(jù)庫撈出壓縮過的數(shù)據(jù),此時(shí)才解壓并展示給前端。查看鏈路,則是該次請求中,整個(gè)鏈路用戶打印的 log(包括線程池內(nèi)的)。
總結(jié)與對比
我們可以簡單的做一些對比,主要在于硬件成本和軟件性能的對比。
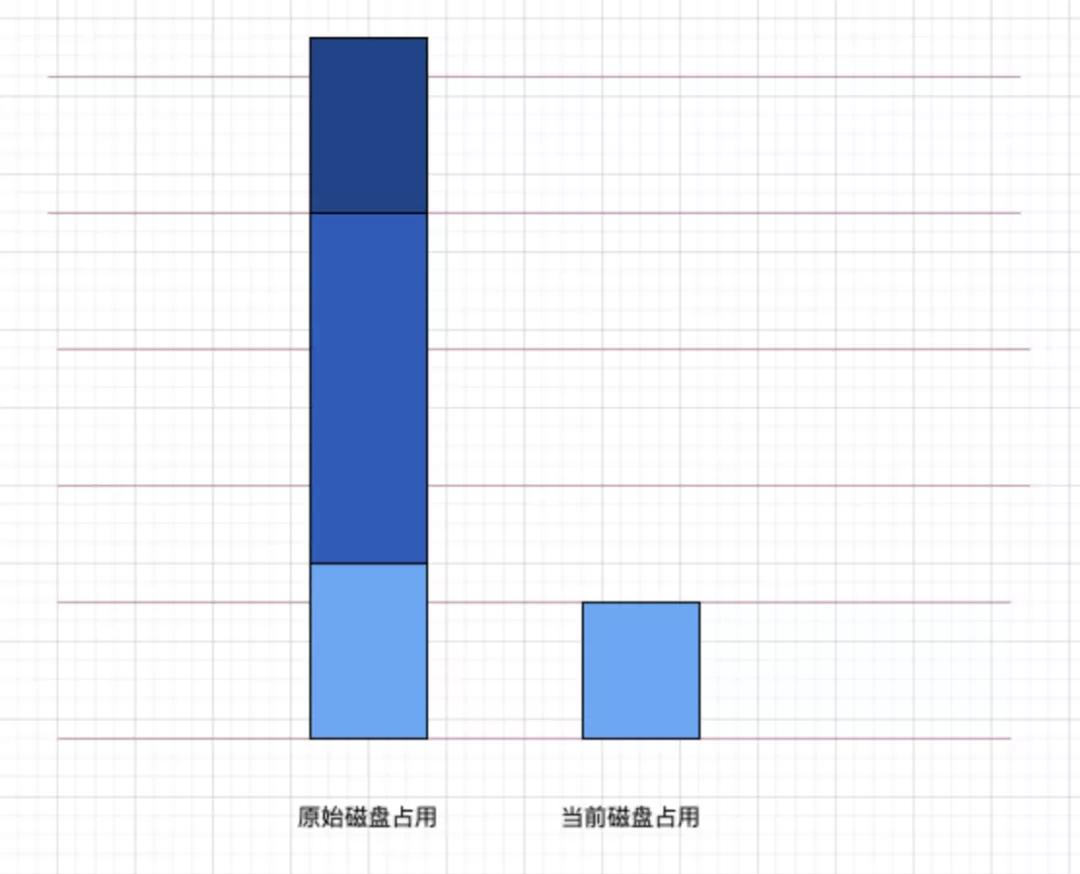
從上文可知,磁盤的占用原始方案占用了磁盤(1 份),MQ(2 份),數(shù)據(jù)庫(1 份)。
而在新的方案中,磁盤的占用僅剩下 clickhouse 的(0.8 份),clickhouse 自身又對數(shù)據(jù)做了壓縮,實(shí)際占用空間不到入庫容量的 80%。那么僅磁盤即可節(jié)省 75% 以上的存儲(chǔ)成本。
大家都知道,秒級(jí)的吞吐量,是伴隨著服務(wù)器 CPU 的耗費(fèi)的,并不是說只給個(gè)大硬盤,即可一臺(tái)服務(wù)器每秒吞吐 1 個(gè) G 的。
每臺(tái)服務(wù)器秒級(jí)的吞吐量是有上限的,秒級(jí)占用磁盤的上升,即對應(yīng) CPU 數(shù)量的上升,要支撐一秒 1G 的磁盤寫入,需要 5 臺(tái)或以上的服務(wù)器。
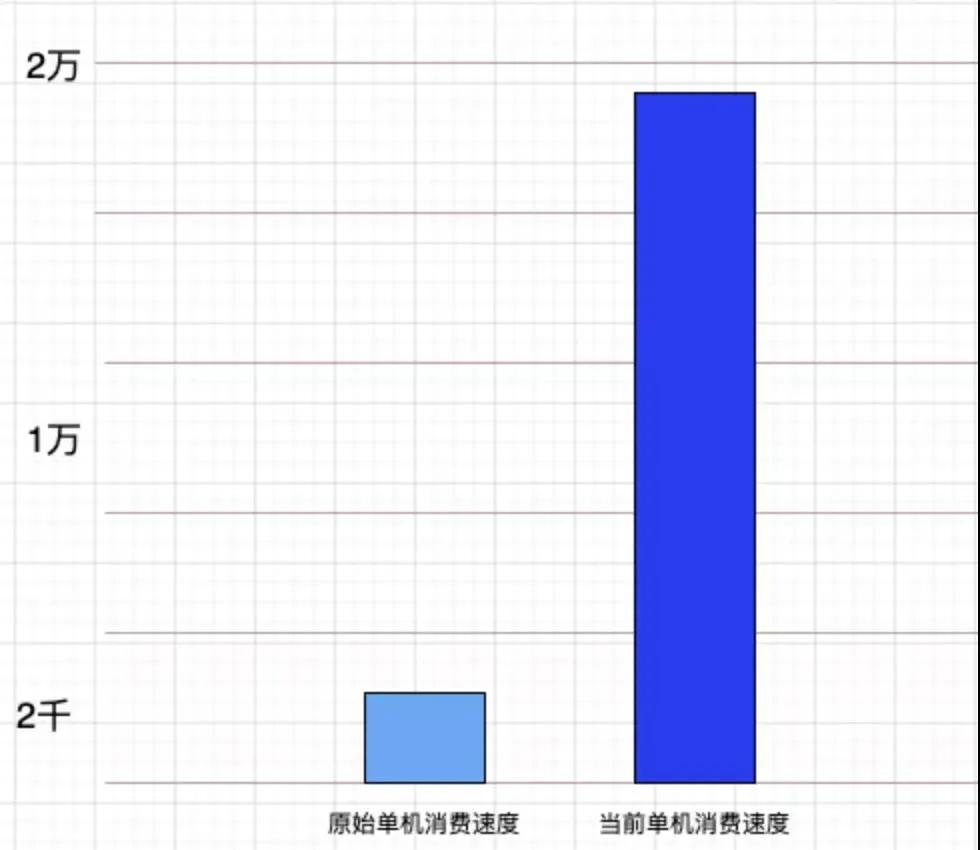
那么在磁盤的大幅節(jié)約下,線性地節(jié)省了大量的中間過程 CPU 服務(wù)器。實(shí)際粗略統(tǒng)計(jì)效果,流程中服務(wù)器可節(jié)約 70% 以上。
在軟件性能上,過程很好理解。對 Client 端的消耗主要就是序列化、寫磁盤、讀磁盤、反序列化這幾步的消耗,Udp 則僅有一步序列化。
我們假設(shè) MQ 集群是有無限的寫入能力,可以吞下所有的發(fā)過去的日志,那么就是 worker 端的消費(fèi)性能對比。
從 MQ 拉取并消費(fèi),這個(gè)過程如果 MQ 沒有積壓,則有零拷貝在支撐高速的拉取,如果積壓了,則可能產(chǎn)生大量的 MQ 磁盤 IO,拉取速度會(huì)大幅下降。
這個(gè)過程效率會(huì)明顯低于 Udp 發(fā)送到 worker 的處理效率,而且占用雙份的網(wǎng)絡(luò)帶寬。
實(shí)際表現(xiàn)上,worker 表現(xiàn)出的強(qiáng)勁性能,較之前單條拉取 MQ 集群時(shí),消費(fèi)性能提升在 10 倍以上。
本文到此就結(jié)束了,主要簡略介紹了一個(gè)新的日志搜集系統(tǒng)的設(shè)計(jì)方案,以及該方案能帶來的巨大的成本節(jié)省。
作者:武偉峰、李陽
編輯:陶家龍
來源:轉(zhuǎn)載自公眾號(hào)京東零售技術(shù)(ID:jd-sys)