我們一起分享一次實用的爬蟲經驗
作者:Python進階者
一開始我以為很簡單,我照著他給的網站,然后一頓抓包操作,到頭來竟然沒有找到響應數據,不論是在ALL還是XHR里邊都沒有找到任何符合要求的數據,真是納悶。講到這里,【杯酒】大佬一開始也放大招,嚇得我不敢說話。
大家好,我是Python進階者。
前言
前幾天鉑金群有個叫【艾米】的粉絲在問了一道關于Python網絡爬蟲的問題,如下圖所示。
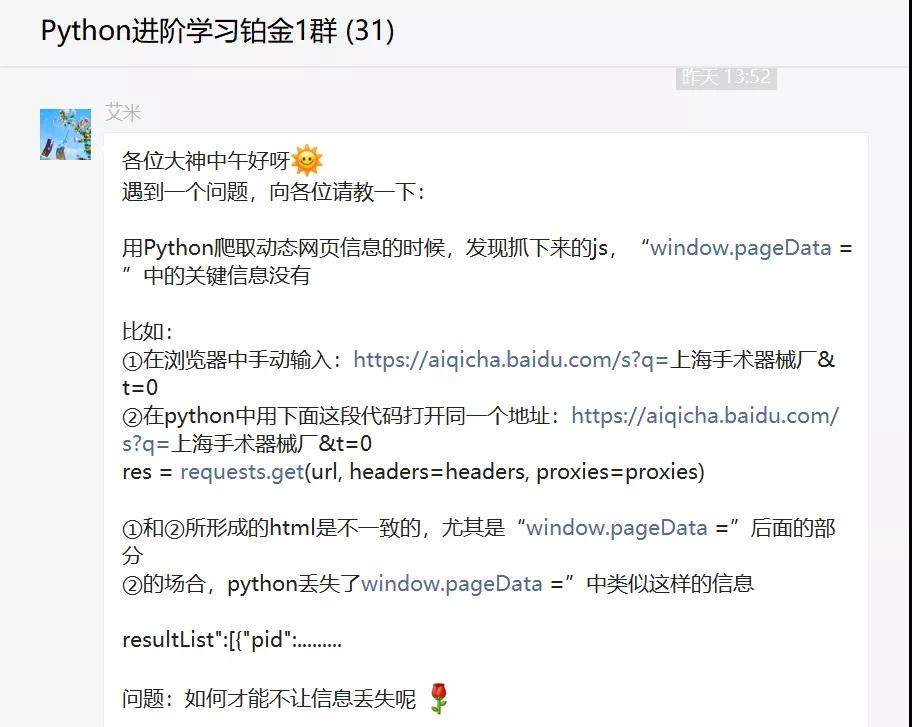
不得不說這個粉絲的提問很詳細,也十分的用心,給他點贊,如果大家日后提問都可以這樣的話,想必可以節約很多溝通時間成本。
其實他抓取的網站是愛企查,類似企查查那種。
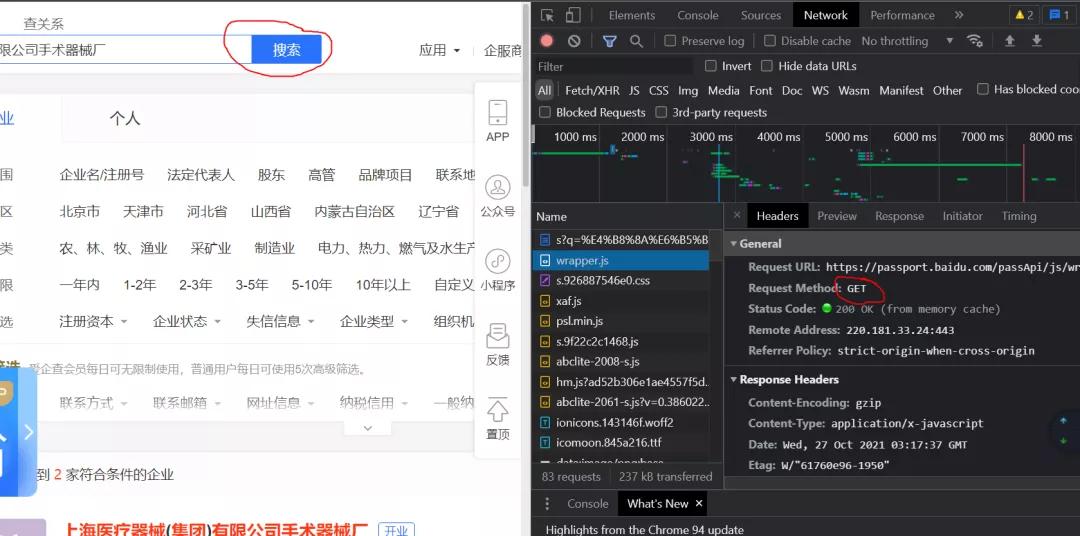
一、思路
一開始我以為很簡單,我照著他給的網站,然后一頓抓包操作,到頭來竟然沒有找到響應數據,不論是在ALL還是XHR里邊都沒有找到任何符合要求的數據,真是納悶。講到這里,【杯酒】大佬一開始也放大招,嚇得我不敢說話。
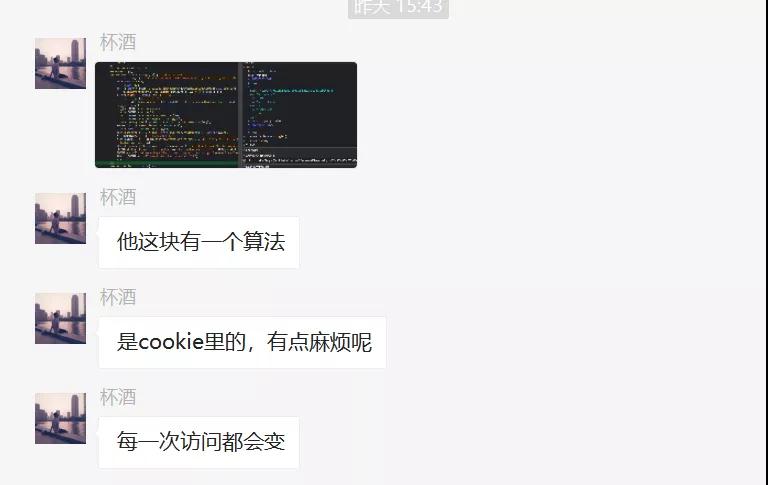
其實是想復雜了,一會兒你就知道了。
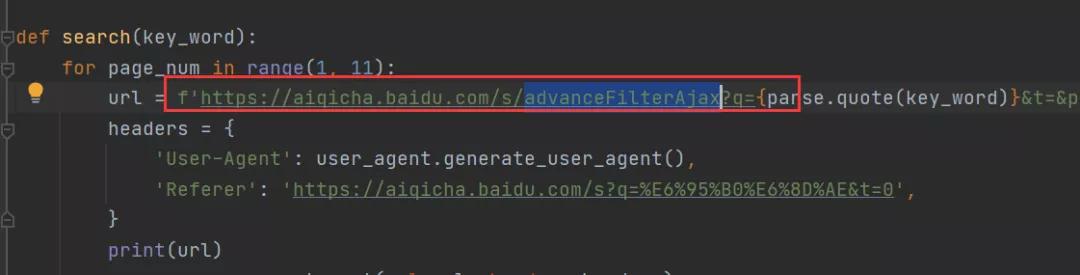
懷著一顆學習的心,我看了杯酒的代碼,發現他構造的URL中有下圖這個:
然后我再去網頁中去找這個URL,可是這個URL在原網頁中根本就找不到???這就離譜了,總不能空穴來風吧,事出必有因!
二、分析
原來這里有個小技巧,有圖有真相。
之后根據抓包情況,就可以看到數據了。
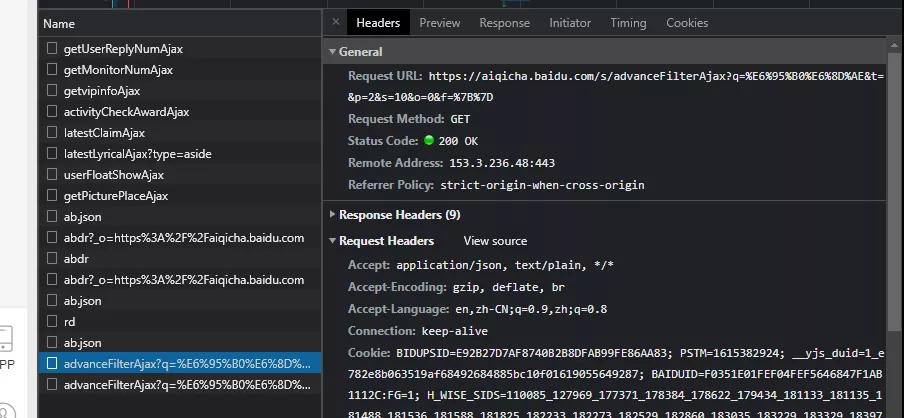
在里邊可以看到數據:
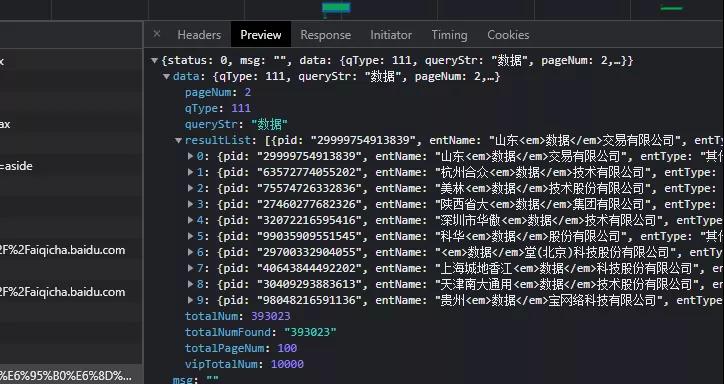
這里【杯酒】大佬查詢的關鍵詞是:數據,所以得到了好幾頁數據,而我和【艾米】都是直接查的:上海手術器械廠,這個只有一頁,不太好觀察規律,所以一直卡住了。
之后將得到的代碼中的URL的關鍵詞,改為:上海手術器械廠,就可以順利的得到數據,是不是很神奇呢?
三、代碼
下面就奉上本次爬蟲的代碼,歡迎大家積極嘗試。
- # -*- coding: utf-8 -*-
- import requests
- import user_agent
- from urllib import parse
- def search(key_word):
- for page_num in range(1, 2):
- url = f'https://aiqicha.baidu.com/s/advanceFilterAjax?q={parse.quote(key_word)}&t=&p={str(page_num)}&s=10&o=0&f=%7B%7D'
- headers = {
- 'User-Agent': user_agent.generate_user_agent(),
- 'Referer': 'https://aiqicha.baidu.com/s?q=%E6%95%B0%E6%8D%AE&t=0',
- }
- print(url)
- response = requests.get(url=url, headers=headers)
- print(requests)
- print(response.json())
- # break
- if __name__ == '__main__':
- search('上海手術器械廠')
只需要將關鍵詞換成你自己想要搜索的就可以了。
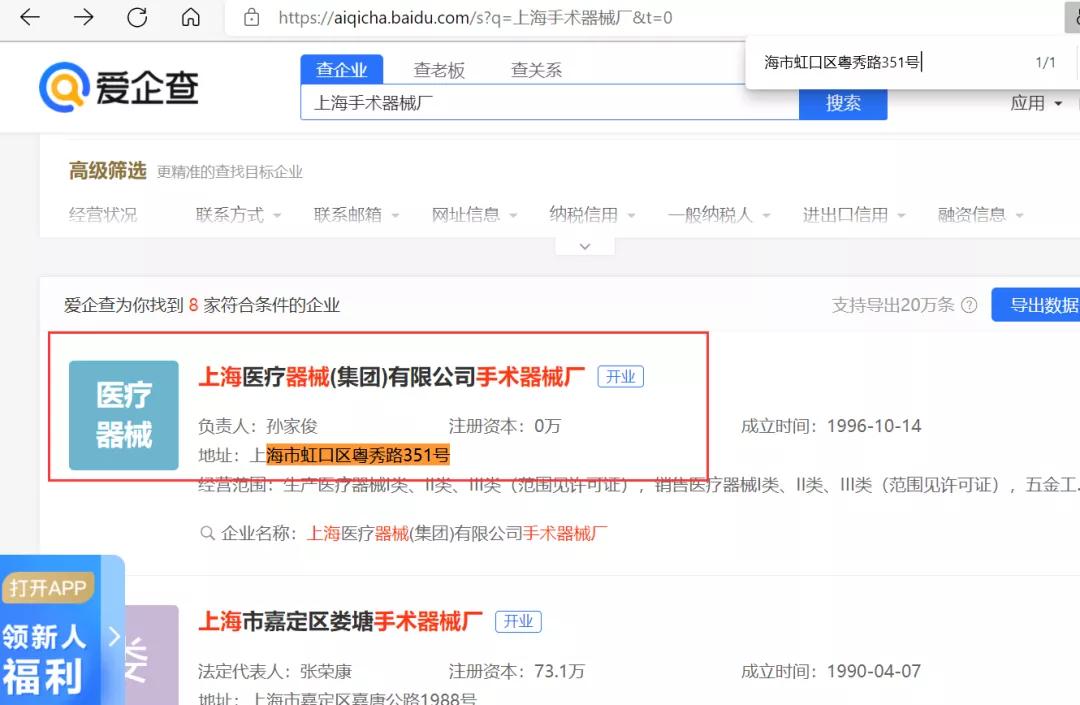
下圖是運行的結果:

下圖是原網頁的截圖,可以看到數據可以對的上:
四、總結
我是Python進階者。本文基于粉絲提問,針對一次有趣的爬蟲經歷,分享一個實用的爬蟲經驗給大家。下次再遇到類似這種首頁無法抓取的網頁,或者看不到包的網頁,不妨試試看文中的“以退為進,投機取巧”方法,說不定有妙用噢!
責任編輯:武曉燕
來源:
Python爬蟲與數據挖掘