













Shopee 送命題:進程切換為什么比線程切換慢
這個問題挺有區分度的,我也是昨天整理面經才看見的這道題。
注意這里問的是為什么進程切換比線程慢,而不是問為什么進程比線程慢。當然這里的線程肯定指的是同一個進程中的線程。
引子
在進入文題之前,我想有必要解釋下虛擬地址(邏輯地址)和物理地址的區別
下面這段 C 代碼摘錄自《操作系統導論 - [美] 雷姆茲·H.阿帕希杜塞爾》,依次打印出 main 函數的地址,由 malloc(類似于 Java 中的 new 操作)返回的堆空間分配的值,以及棧上一個整數的地址:
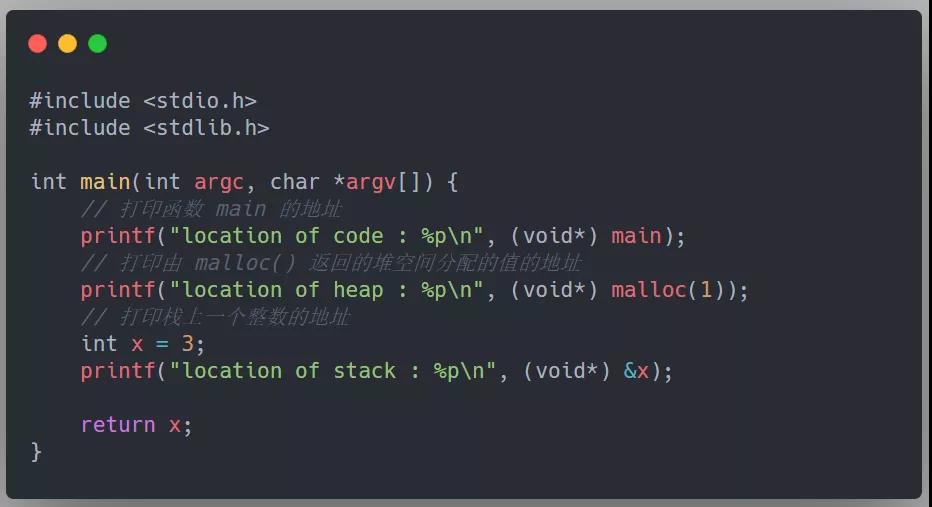
得到以下輸出:
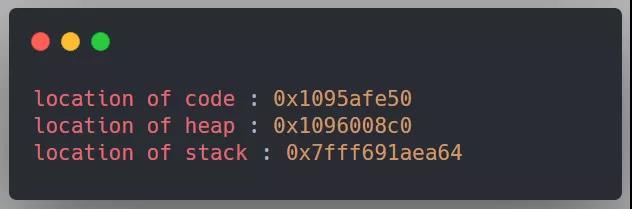
我們需要知道的是,所有這些打印出來的地址都是虛擬的,在物理內存中這些地址并不真實存在,它們最終都將由操作系統和 CPU 硬件翻譯成真正的物理地址,然后才能從真實的物理位置獲取該地址的值。
OK,上述就當作一個引子,讓各位對物理地址和虛擬地址有個直觀的理解,下面正文開始。
物理尋址 Physical Addressing
物理地址的概念很好理解,你可以把它稱為真正的地址。《深入理解計算機系統 - 第 3 版》中給出的物理地址(physical address)的定義如下:
計算機系統的主存被組織成一個由 M 個連續的字節大小的單元組成的數組。每字節都有一個唯一的物理地址。
比如說,第一個字節的物理地址是 0,接下來的字節地址是 1,再下一個是 2,以此類推,給定這種簡單的結構,CPU 訪問內存的最自然的方式就是使用這樣的物理地址。我們把這種方式稱為物理尋址(physical addressing)。
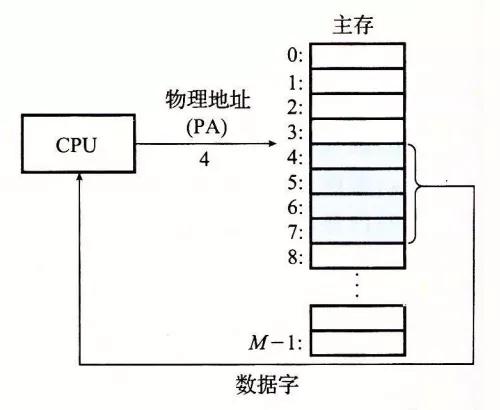
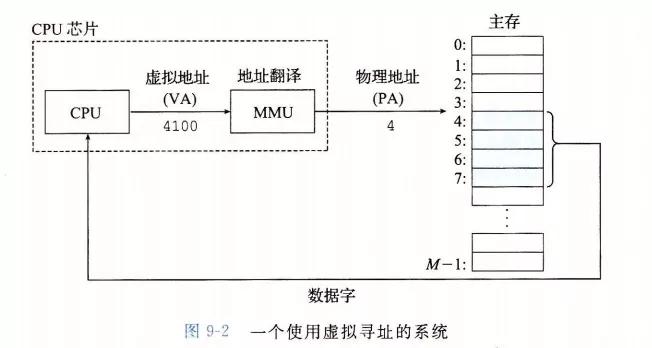
舉個例子,比如說當程序執行了一條加載指令,指令內容是從物理地址 4 中讀取 4 字節字傳送到某個寄存器中。
物理尋址過程如下:當 CPU 執行到這條指令時,會生成物理地址 4,然后通過內存主線,把它傳遞給內存,內存取出從物理地址 4 處開始的 4 字節字,并將它返回給 CPU,CPU 會將它存放到指定的寄存器中。看下圖:
其實不難發現,物理尋址這種方式,每一個程序都直接訪問物理內存,其實是存在重大缺陷的:
1)首先,用戶程序可以尋址內存的任意一個字節,它們就可以很容易地破壞操作系統,從而使系統慢慢地停止運行。
2)再次,這種尋址方式使得操作系統中同時運行兩個或以上的程序幾乎是不可能的。
舉個例子,我們打開了三個相同的程序(計算器),都執行到某一步。比方說,用戶在這三個計算器程序的界面上分別輸入了 10、100、1000,其對應的指令就是把用戶輸入的數字保存在內存中的某個地址中。如果這個位置只能保存一個數,那應該保存哪個呢?這不就沖突了嗎?
簡單來說,第一個計算器程序給物理內存地址賦值 10,第二個計算器程序也同樣給這個地址賦值為 100,那么第二個程序的賦值會覆蓋掉第一個程序所賦的值,這會造成兩個程序同時崩潰。
當然了,我們也說了是幾乎不可能,不是完全不可能,還是有一些方法可以在物理尋址這種方式下實現多個程序并發運行的。
最簡單的方法就是:首先,將空閑的進程存儲在磁盤上,這樣當它們不運行時就不會占用內存,然后,讓一個程序(或者說進程)單獨占用全部內存運行一小段時間,當發生上下文切換的時候,就停止這個進程,并將它所有的狀態信息保存在磁盤上,再加載其他進程的狀態信息,然后運行一段時間...... 只要在某一個時間內存中只有一個程序,那么就不會發生上述所說的地址沖突。這就實現了一種比較粗糙的并發。
為什么說他是粗糙的呢,因為這種方法有一個問題:將全部的內存信息保存到磁盤太慢了!特別是當內存增長的時候。
因此,我們考慮把進程對應的內存一直留在物理內存中,給每個進程分別劃分各自的區域,在發生上下文切換的時候就切換到特定的區域。
如下圖所示,有 3 個進程(A、B、C),每個進程擁有從 512KB 物理內存中切出來給它們的一小部分內存,可以理解為這 3 個進程共享物理內存:

顯然,這種方式是存在一定安全隱患的。畢竟如果各個進程之間可以隨意讀取、寫入內容的話那就亂套了。
那么如何對每個進程使用的地址進行保護(protection)呢?繼續使用物理內存模型肯定是不行了,因此操作系統創造了一個新的內存抽象,引入了一個新的內存模型,那就是虛擬地址空間,很多書中都會直接稱呼為 “地址空間(Address Space)”。
虛擬尋址 Virtual Addressing
上面提到,對于物理內存模型來說,如果各個進程之間可以隨意讀取、寫入內容的話那就亂套了。
所以,每個進程的棧啊、堆啊、代碼段啊等等它們的實際物理內存地址對于這個進程來說應該是不可見的,這樣誰也不能直接訪問這個物理地址。
那問題就來了,物理地址被隱藏起來了,我們該怎么去訪問這個進程呢?
操作系統會給每個進程分配一個虛擬地址空間(vitural address),每個進程包含的棧、堆、代碼段這些都會從這個地址空間中被分配一個地址,這個地址就被稱為虛擬地址。底層指令寫入的地址也是虛擬地址。
每個進程都擁有一個自己的虛擬地址空間,并且獨立于其他進程的地址空間。(注意這句話非常重要!!!兄弟姐妹們背起來)
也就是說一個進程中的虛擬地址 28 所對應的物理地址與另一個進程中的虛擬地址 28 所對應的物理地址是不同的,這樣就不會發生沖突了。
可以這么理解,物理地址就是一個倉庫,虛擬地址就是一個門牌,比方說一共有三十個門牌,那么所有的進程都能看見這三十個門牌,但是他們看見的某個相同門牌,指向的并不是同一個倉庫。
有了虛擬地址空間后,CPU 就可以通過生成一個虛擬地址來訪問主存,這個虛擬地址在被送到內存之前會先被轉換成合適的物理地址,這個虛擬地址到物理地址的轉換過程稱為 地址翻譯/地址轉換(address translation)。
地址翻譯需要 CPU 硬件和操作系統的密切合作:CPU 上的內存管理單元(Memory Management Unit,MMU)就是專門用來進行虛擬地址到物理地址的轉換的,不過 MMU 需要借助存放在內存中的頁表,而這張表的內容正是由操作系統進行管理的。
頁表是一個十分重要的數據結構!
操作系統為每個進程建立了一張頁表。一個進程對應一張頁表,進程的每個頁面對應一個頁表項,每個頁表項由頁號和塊號(頁框號)組成,記錄著進程頁面和實際存放的內存塊之間的映射關系。
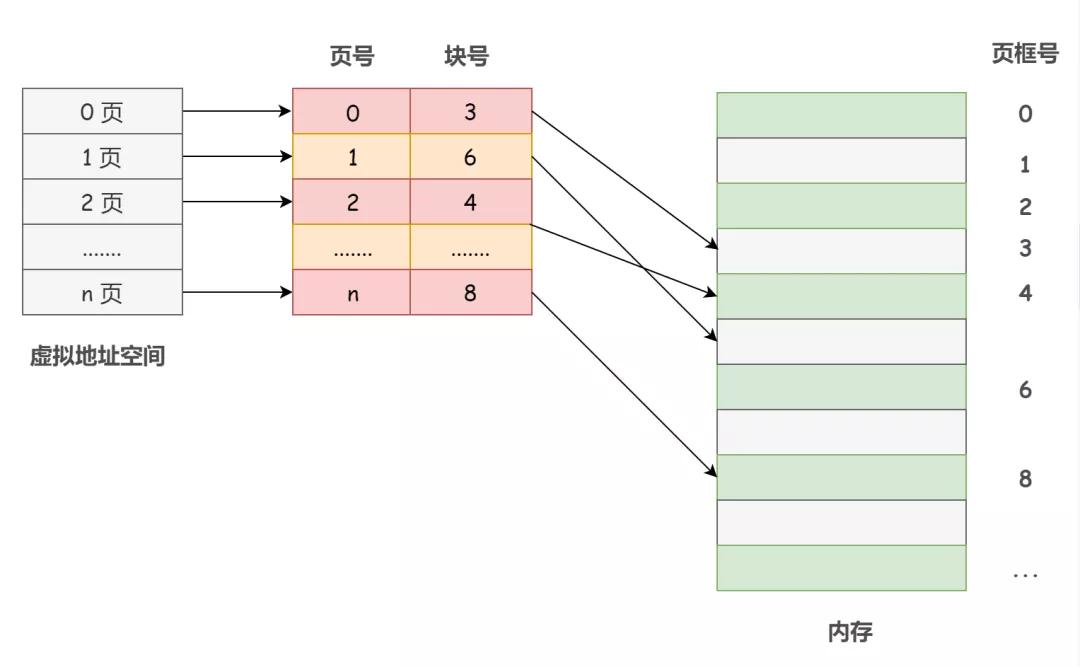
從數學角度來說,頁表是一個函數,它的參數是虛擬頁號,結果是物理頁框號。
至此,上述這一套 CPU 生成虛擬地址并進行地址翻譯的流程就是虛擬尋址(virtual addressing):
進程切換為什么比線程切換慢?
呼,講了一大堆,其實最重要的就是這句話:
每個進程都擁有一個自己的虛擬地址空間,并且獨立于其他進程的地址空間
So,Tell me,進程切換會涉及什么的切換?
是的,進程切換會涉及到虛擬地址空間的切換,而這正是導致進程切換比線程切換慢的原因所在!
很多小伙伴可能都云里霧里,啊,是這樣嗎,怎么回事
想一下,上面是不是說過,虛擬地址轉換為物理地址需要兩個東西:CPU 上的 MMU 和內存中的頁表
每次訪問內存,都需要進行虛擬地址到物理地址的轉換,對吧,因此,每條指令進行一兩次或更多地去訪問頁表是必要的,而頁表又是存在于內存中的。
顯然,訪問頁表(內存)次數太多導致其成為了操作系統地一個性能瓶頸,我們得想個法子解決它
于是,轉換檢測緩沖區(Translation Lookaside Buffer,TLB)應運而生,也稱為快表
為啥說他快呢?因為 TLB 通常內置在 CPU 的 MMU 中,這訪問速度跟內存不是一個檔次的。內存中的頁表一般被稱為慢表。
事實上,TLB 的出現是基于這樣一種現象的:大多數程序總是對少量的頁面進行多次的訪問。因此,只有很少的頁表項會被反復讀取,而其他的頁表項很少被訪問。
TLB 中存放的就是那些會被反復讀取的頁表項。換句話說,TLB 中存放的就是頁表中的一部分副本。
若 TLB 命中,就不需要再訪問內存了;若 TLB 中沒有目標頁表項,則還需要去查詢內存中的頁表(慢表),從頁表中得到物理頁框地址,同時將頁表中的該表項添加到 TLB 中。
簡單理解,TLB 就相當于一個緩存
現在再回到問題,不知道各位小伙伴有沒有一點思路了。
由于進程切換會涉及到虛擬地址空間的切換,這就導致內存中的頁表也需要進行切換,一個進程對應一個頁表是不假,但是 CPU 中的 TLB 只有一個啊,這就尷尬了,頁表切換后這個 TLB 就失效了。這樣,TLB 在一段時間內肯定是無法被命中的,操作系統就必須去訪問內存,那么虛擬地址轉換為物理地址就會變慢,表現出來的就是程序運行會變慢。
而線程切換呢,由于不涉及虛擬地址空間的切換,也就不存在這個問題了。
最后放上這道題的背誦版:
面試官:進程切換為什么比線程切換要慢呢?
小牛肉:額,關于這個問題,需要從虛擬地址和物理地址說起
物理地址就是真實的地址嘛,這種尋址方式很容易破壞操作系統,而且使得操作系統中同時運行兩個或以上的程序幾乎是不可能的(此處可以舉個例子,第一個程序給物理內存地址賦值 10,第二個程序也同樣給這個地址賦值為 100,那么第二個程序的賦值會覆蓋掉第一個程序所賦的值,這會造成兩個程序同時崩潰)。
當然,也不是完全不可能,有一種方式可以實現比較粗糙的并發
就是說,我們將空閑的進程存儲在磁盤上,這樣當它們不運行時就不會占用內存,當進程需要運行的時候再從磁盤上轉到內存上來,不過很顯然這種方式比較浪費時間。
于是,我們考慮,把所有進程對應的內存一直留在物理內存中,給每個進程分別劃分各自的區域,這樣,發生上下文切換的時候就切換到特定的區域
那問題還是很明顯的,就是仍然沒法避免破壞操作系統,因為各個進程之間可以隨意讀取、寫入內容。
所以,我們需要一種機制對每個進程使用的地址進行保護,因此操作系統創造了一個新的內存模型,那就是虛擬地址空間
就是說,每個進程都擁有一個自己的虛擬地址空間,并且獨立于其他進程的地址空間,然后每個進程包含的棧、堆、代碼段這些都會從這個地址空間中被分配一個地址,這個地址就被稱為虛擬地址。底層指令寫入的地址也是虛擬地址。
有了虛擬地址空間后,CPU 就可以通過虛擬地址轉換成物理地址這樣一個過程,來間接訪問物理內存了。
地址轉換需要兩個東西,一個是 CPU 上的內存管理單元 MMU,另一個是內存中的頁表,頁表中存的虛擬地址到物理地址的映射
但是呢,每次訪問內存,都需要進行虛擬地址到物理地址的轉換,對吧,這樣的話,頁表就會被頻繁地訪問,而頁表又是存在于內存中的。所以說,訪問頁表(內存)次數太多導致其成為了操作系統地一個性能瓶頸。
于是,引入了轉換檢測緩沖區 TLB,也就是快表,其實就是一個緩存,把經常訪問到的內存地址映射存在 TLB 中,因為 TLB 是在 CPU 的 MMU 中的嘛,所以訪問起來非常快。
然后,正是因為 TLB 這個東西,導致了進程切換比線程切換慢。
由于進程切換會涉及到虛擬地址空間的切換,這就導致內存中的頁表也需要進行切換,一個進程對應一個頁表是不假,但是 CPU 中的 TLB 只有一個,頁表切換后這個 TLB 就失效了。這樣,TLB 在一段時間內肯定是無法被命中的,操作系統就必須去訪問內存,那么虛擬地址轉換為物理地址就會變慢,表現出來的就是程序運行會變慢。
而線程切換呢,由于不涉及虛擬地址空間的切換,所以也就不存在這個問題了。



















