













Redis 分布式鎖的正確實現原理演化歷程與 Redisson 實戰總結
Redis 分布式鎖使用 SET 指令就可以實現了么?在分布式領域 CAP 理論一直存在。
分布式鎖的門道可沒那么簡單,我們在網上看到的分布式鎖方案可能是有問題的。
「碼哥」一步步帶你深入分布式鎖是如何一步步完善,在高并發生產環境中如何正確使用分布式鎖。
在進入正文之前,我們先帶著問題去思考:
- 什么時候需要分布式鎖?
- 加、解鎖的代碼位置有講究么?
- 如何避免出現鎖再也無法刪除?
- 超時時間設置多少合適呢?
- 如何避免鎖被其他線程釋放
- 如何實現重入鎖?
- 主從架構會帶來什么安全問題?
- 什么是 Redlock
- Redisson 分布式鎖最佳實戰
- 看門狗實現原理
- ……
什么時候用分布式鎖?
碼哥,說個通俗的例子講解下什么時候需要分布式鎖呢?
診所只有一個醫生,很多患者前來就診。
醫生在同一時刻只能給一個患者提供就診服務。
如果不是這樣的話,就會出現醫生在就診腎虧的「肖菜雞」準備開藥時候患者切換成了腳臭的「謝霸哥」,這時候藥就被謝霸哥取走了。
治腎虧的藥被有腳臭的拿去了。
當并發去讀寫一個【共享資源】的時候,我們為了保證數據的正確,需要控制同一時刻只有一個線程訪問。
分布式鎖就是用來控制同一時刻,只有一個 JVM 進程中的一個線程可以訪問被保護的資源。
分布式鎖入門
65 哥:分布式鎖應該滿足哪些特性?
互斥:在任何給定時刻,只有一個客戶端可以持有鎖;
無死鎖:任何時刻都有可能獲得鎖,即使獲取鎖的客戶端崩潰;
容錯:只要大多數 Redis的節點都已經啟動,客戶端就可以獲取和釋放鎖。
碼哥,我可以使用 SETNX key value 命令是實現「互斥」特性。
這個命令來自于SET if Not eXists的縮寫,意思是:如果 key 不存在,則設置 value 給這個key,否則啥都不做。Redis 官方地址說的:
命令的返回值:
- 1:設置成功;
- 0:key 沒有設置成功。
如下場景:
敲代碼一天累了,想去放松按摩下肩頸。
168 號技師最搶手,大家喜歡點,所以并發量大,需要分布式鎖控制。
同一時刻只允許一個「客戶」預約 168 技師。
肖菜雞申請 168 技師成功:
- > SETNX lock:168 1
- (integer) 1 # 獲取 168 技師成功
謝霸哥后面到,申請失敗:
- > SETNX lock 2
- (integer) 0 # 客戶謝霸哥 2 獲取失敗
此刻,申請成功的客戶就可以享受 168 技師的肩頸放松服務「共享資源」。
享受結束后,要及時釋放鎖,給后來者享受 168 技師的服務機會。
肖菜雞,碼哥考考你如何釋放鎖呢?
很簡單,使用 DEL 刪除這個 key 就行。
- > DEL lock:168
- (integer) 1
碼哥,你見過「龍」么?我見過,因為我被一條龍服務過。
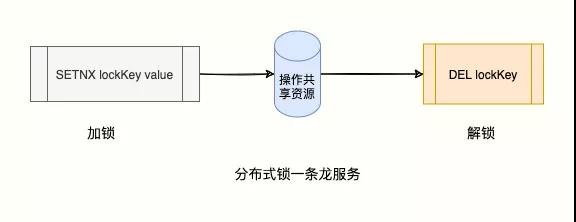
肖菜雞,事情可沒這么簡單。
這個方案存在一個存在造成鎖無法釋放的問題,造成該問題的場景如下:
客戶端所在節點崩潰,無法正確釋放鎖;
業務邏輯異常,無法執行 DEL指令。
這樣,這個鎖就會一直占用,鎖在我手里,我掛了,這樣其他客戶端再也拿不到這個鎖了。
超時設置
碼哥,我可以在獲取鎖成功的時候設置一個「超時時間」
比如設定按摩服務一次 60 分鐘,那么在給這個 key 加鎖的時候設置 60 分鐘過期即可:
- > SETNX lock:168 1 // 獲取鎖
- (integer) 1
- > EXPIRE lock:168 60 // 60s 自動刪除
- (integer) 1
這樣,到點后鎖自動釋放,其他客戶就可以繼續享受 168 技師按摩服務了。
誰要這么寫,就糟透了。
「加鎖」、「設置超時」是兩個命令,他們不是原子操作。
如果出現只執行了第一條,第二條沒機會執行就會出現「超時時間」設置失敗,依然出現鎖無法釋放。
碼哥,那咋辦,我想被一條龍服務,要解決這個問題
Redis 2.6.X 之后,官方拓展了 SET 命令的參數,滿足了當 key 不存在則設置 value,同時設置超時時間的語義,并且滿足原子性。
- SET resource_name random_value NX PX 30000
- NX:表示只有 resource_name 不存在的時候才能 SET 成功,從而保證只有一個客戶端可以獲得鎖;
- PX 30000:表示這個鎖有一個 30 秒自動過期時間。
這樣寫還不夠,我們還要防止不能釋放不是自己加的鎖。我們可以在 value 上做文章。
繼續往下看……
釋放了不是自己加的鎖
這樣我能穩妥的享受一條龍服務了么?
No,還有一種場景會導致釋放別人的鎖:
客戶 1 獲取鎖成功并設置設置 30 秒超時;
客戶 1 因為一些原因導致執行很慢(網絡問題、發生 FullGC……),過了 30 秒依然沒執行完,但是鎖過期「自動釋放了」;
客戶 2 申請加鎖成功;
客戶 1 執行完成,執行 DEL 釋放鎖指令,這個時候就把客戶 2 的鎖給釋放了。
有個關鍵問題需要解決:自己的鎖只能自己來釋放。
我要如何刪除是自己加的鎖呢?
在執行 DEL 指令的時候,我們要想辦法檢查下這個鎖是不是自己加的鎖再執行刪除指令。
解鈴還須系鈴人
碼哥,我在加鎖的時候設置一個「唯一標識」作為 value 代表加鎖的客戶端。SET resource_name random_value NX PX 30000
在釋放鎖的時候,客戶端將自己的「唯一標識」與鎖上的「標識」比較是否相等,匹配上則刪除,否則沒有權利釋放鎖。
偽代碼如下:
- // 比對 value 與 唯一標識
- if (redis.get("lock:168").equals(random_value)){
- redis.del("lock:168"); //比對成功則刪除
- }
有沒有想過,這是 GET + DEL 指令組合而成的,這里又會涉及到原子性問題。
我們可以通過 Lua 腳本來實現,這樣判斷和刪除的過程就是原子操作了。
- // 獲取鎖的 value 與 ARGV[1] 是否匹配,匹配則執行 del
- if redis.call("get",KEYS[1]) == ARGV[1] then
- return redis.call("del",KEYS[1])
- else
- return 0
- end
這樣通過唯一值設置成 value 標識加鎖的客戶端很重要,僅使用 DEL 是不安全的,因為一個客戶端可能會刪除另一個客戶端的鎖。
使用上面的腳本,每個鎖都用一個隨機字符串“簽名”,只有當刪除鎖的客戶端的“簽名”與鎖的 value 匹配的時候,才會刪除它。
官方文檔也是這么說的:https://redis.io/topics/distlock
這個方案已經相對完美,我們用的最多的可能就是這個方案了。
正確設置鎖超時
鎖的超時時間怎么計算合適呢?
這個時間不能瞎寫,一般要根據在測試環境多次測試,然后壓測多輪之后,比如計算出平均執行時間 200 ms。
那么鎖的超時時間就放大為平均執行時間的 3~5 倍。
為啥要放放大呢?
因為如果鎖的操作邏輯中有網絡 IO 操作、JVM FullGC 等,線上的網絡不會總一帆風順,我們要給網絡抖動留有緩沖時間。
那我設置更大一點,比如設置 1 小時不是更安全?
不要鉆牛角,多大算大?
設置時間過長,一旦發生宕機重啟,就意味著 1 小時內,分布式鎖的服務全部節點不可用。
你要讓運維手動刪除這個鎖么?
只要運維真的不會打你。
有沒有完美的方案呢?不管時間怎么設置都不大合適。
我們可以讓獲得鎖的線程開啟一個守護線程,用來給快要過期的鎖「續航」。
加鎖的時候設置一個過期時間,同時客戶端開啟一個「守護線程」,定時去檢測這個鎖的失效時間。
如果快要過期,但是業務邏輯還沒執行完成,自動對這個鎖進行續期,重新設置過期時間。
這個道理行得通,可我寫不出。
別慌,已經有一個庫把這些工作都封裝好了他叫 Redisson。
在使用分布式鎖時,它就采用了「自動續期」的方案來避免鎖過期,這個守護線程我們一般也把它叫做「看門狗」線程。
一路優化下來,方案似乎比較「嚴謹」了,抽象出對應的模型如下。
- 通過 SET lock_resource_name random_value NX PX expire_time,同時啟動守護線程為快要過期但還沒執行完的客戶端的鎖續命;
- 客戶端執行業務邏輯操作共享資源;
- 通過 Lua 腳本釋放鎖,先 get 判斷鎖是否是自己加的,再執行 DEL。
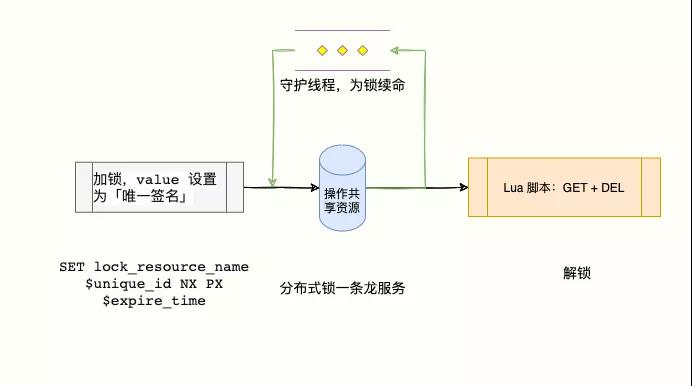
這個方案實際上已經比較完美,能寫到這一步已經打敗 90% 的程序猿了。
但是對于追求極致的程序員來說還遠遠不夠:
- 可重入鎖如何實現?
- 主從架構崩潰恢復導致鎖丟失如何解決?
- 客戶端加鎖的位置有門道么?
加解鎖代碼位置有講究
根據前面的分析,我們已經有了一個「相對嚴謹」的分布式鎖了。
于是「謝霸哥」就寫了如下代碼將分布式鎖運用到項目中,以下是偽代碼邏輯:
- public void doSomething() {
- redisLock.lock(); // 上鎖
- try {
- // 處理業務
- .....
- redisLock.unlock(); // 釋放鎖
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
有沒有想過:一旦執行業務邏輯過程中拋出異常,程序就無法執行釋放鎖的流程。
所以釋放鎖的代碼一定要放在 finally{} 塊中。
加鎖的位置也有問題,放在 try 外面的話,如果執行 redisLock.lock() 加鎖異常,但是實際指令已經發送到服務端并執行,只是客戶端讀取響應超時,就會導致沒有機會執行解鎖的代碼。
所以 redisLock.lock() 應該寫在 try 代碼塊,這樣保證一定會執行解鎖邏輯。
綜上所述,正確代碼位置如下 :
- public void doSomething() {
- try {
- // 上鎖
- redisLock.lock();
- // 處理業務
- ...
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- // 釋放鎖
- redisLock.unlock();
- }
- }
實現可重入鎖
65 哥:可重入鎖要如何實現呢?
當一個線程執行一段代碼成功獲取鎖之后,繼續執行時,又遇到加鎖的代碼,可重入性就就保證線程能繼續執行,而不可重入就是需要等待鎖釋放之后,再次獲取鎖成功,才能繼續往下執行。
用一段代碼解釋可重入:
- public synchronized void a() {
- b();
- }
- public synchronized void b() {
- // pass
- }
假設 X 線程在 a 方法獲取鎖之后,繼續執行 b 方法,如果此時不可重入,線程就必須等待鎖釋放,再次爭搶鎖。
鎖明明是被 X 線程擁有,卻還需要等待自己釋放鎖,然后再去搶鎖,這看起來就很奇怪,我釋放我自己~
Redis Hash 可重入鎖
Redisson 類庫就是通過 Redis Hash 來實現可重入鎖
當線程擁有鎖之后,往后再遇到加鎖方法,直接將加鎖次數加 1,然后再執行方法邏輯。
退出加鎖方法之后,加鎖次數再減 1,當加鎖次數為 0 時,鎖才被真正的釋放。
可以看到可重入鎖最大特性就是計數,計算加鎖的次數。
所以當可重入鎖需要在分布式環境實現時,我們也就需要統計加鎖次數。
加鎖邏輯
我們可以使用 Redis hash 結構實現,key 表示被鎖的共享資源, hash 結構的 fieldKey 的 value 則保存加鎖的次數。
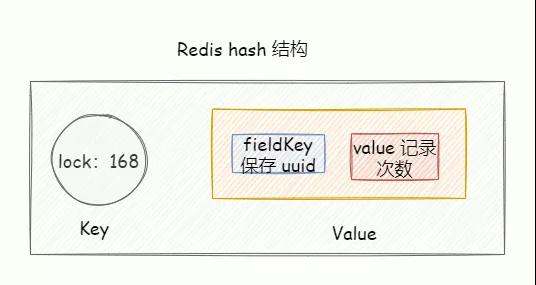
通過 Lua 腳本實現原子性,假設 KEYS1 = 「lock」, ARGV「1000,uuid」:
- ---- 1 代表 true
- ---- 0 代表 false
- if (redis.call('exists', KEYS[1]) == 0) then
- redis.call('hincrby', KEYS[1], ARGV[2], 1);
- redis.call('pexpire', KEYS[1], ARGV[1]);
- return 1;
- end ;
- if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
- redis.call('hincrby', KEYS[1], ARGV[2], 1);
- redis.call('pexpire', KEYS[1], ARGV[1]);
- return 1;
- end ;
- return 0;
加鎖代碼首先使用 Redis exists 命令判斷當前 lock 這個鎖是否存在。
如果鎖不存在的話,直接使用 hincrby創建一個鍵為 lock hash 表,并且為 Hash 表中鍵為 uuid 初始化為 0,然后再次加 1,最后再設置過期時間。
如果當前鎖存在,則使用 hexists判斷當前 lock 對應的 hash 表中是否存在 uuid 這個鍵,如果存在,再次使用 hincrby 加 1,最后再次設置過期時間。
最后如果上述兩個邏輯都不符合,直接返回。
解鎖邏輯
-- 判斷 hash set 可重入 key 的值是否等于 0
-- 如果為 0 代表 該可重入 key 不存在
- -- 判斷 hash set 可重入 key 的值是否等于 0
- -- 如果為 0 代表 該可重入 key 不存在
- if (redis.call('hexists', KEYS[1], ARGV[1]) == 0) then
- return nil;
- end ;
- -- 計算當前可重入次數
- local counter = redis.call('hincrby', KEYS[1], ARGV[1], -1);
- -- 小于等于 0 代表可以解鎖
- if (counter > 0) then
- return 0;
- else
- redis.call('del', KEYS[1]);
- return 1;
- end ;
- return nil;
首先使用 hexists 判斷 Redis Hash 表是否存給定的域。
如果 lock 對應 Hash 表不存在,或者 Hash 表不存在 uuid 這個 key,直接返回 nil。
若存在的情況下,代表當前鎖被其持有,首先使用 hincrby使可重入次數減 1 ,然后判斷計算之后可重入次數,若小于等于 0,則使用 del 刪除這把鎖。
解鎖代碼執行方式與加鎖類似,只不過解鎖的執行結果返回類型使用 Long。這里之所以沒有跟加鎖一樣使用 Boolean ,這是因為解鎖 lua 腳本中,三個返回值含義如下:
- 1 代表解鎖成功,鎖被釋放
- 0 代表可重入次數被減 1
- null 代表其他線程嘗試解鎖,解鎖失敗.
主從架構帶來的問題
碼哥,到這里分布式鎖「很完美了」吧,沒想到分布式鎖這么多門道。
路還很遠,之前分析的場景都是,鎖在「單個」Redis 實例中可能產生的問題,并沒有涉及到 Redis 主從模式導致的問題。
我們通常使用「Cluster 集群」或者「哨兵集群」的模式部署保證高可用。
這兩個模式都是基于「主從架構數據同步復制」實現的數據同步,而 Redis 的主從復制默認是異步的。
以下內容來自于官方文檔 https://redis.io/topics/distlock
我們試想下如下場景會發生什么問題:
客戶端 A 在 master 節點獲取鎖成功。
還沒有把獲取鎖的信息同步到 slave 的時候,master 宕機。
slave 被選舉為新 master,這時候沒有客戶端 A 獲取鎖的數據。
客戶端 B 就能成功的獲得客戶端 A 持有的鎖,違背了分布式鎖定義的互斥。
雖然這個概率極低,但是我們必須得承認這個風險的存在。
Redis 的作者提出了一種解決方案,叫 Redlock(紅鎖)
Redis 的作者為了統一分布式鎖的標準,搞了一個 Redlock,算是 Redis 官方對于實現分布式鎖的指導規范,https://redis.io/topics/distlock,但是這個 Redlock 也被國外的一些分布式專家給噴了。
因為它也不完美,有“漏洞”。
什么是 Redlock
紅鎖是不是這個?
泡面吃多了你,Redlock 紅鎖是為了解決主從架構中當出現主從切換導致多個客戶端持有同一個鎖而提出的一種算法。
大家可以看官方文檔(https://redis.io/topics/distlock),以下來自官方文檔的翻譯。
想用使用 Redlock,官方建議在不同機器上部署 5 個 Redis 主節點,節點都是完全獨立,也不使用主從復制,使用多個節點是為容錯。
一個客戶端要獲取鎖有 5 個步驟:
客戶端獲取當前時間 T1(毫秒級別);
使用相同的 key和 value順序嘗試從 N個 Redis實例上獲取鎖。
每個請求都設置一個超時時間(毫秒級別),該超時時間要遠小于鎖的有效時間,這樣便于快速嘗試與下一個實例發送請求。
比如鎖的自動釋放時間 10s,則請求的超時時間可以設置 5~50 毫秒內,這樣可以防止客戶端長時間阻塞。
客戶端獲取當前時間 T2 并減去步驟 1 的 T1 來計算出獲取鎖所用的時間(T3 = T2 -T1)。當且僅當客戶端在大多數實例(N/2 + 1)獲取成功,且獲取鎖所用的總時間 T3 小于鎖的有效時間,才認為加鎖成功,否則加鎖失敗。
如果第 3 步加鎖成功,則執行業務邏輯操作共享資源,key 的真正有效時間等于有效時間減去獲取鎖所使用的時間(步驟 3 計算的結果)。
如果因為某些原因,獲取鎖失敗(沒有在至少 N/2+1 個 Redis 實例取到鎖或者取鎖時間已經超過了有效時間),客戶端應該在所有的 Redis 實例上進行解鎖(即便某些 Redis 實例根本就沒有加鎖成功)。
另外部署實例的數量要求是奇數,為了能很好的滿足過半原則,如果是 6 臺則需要 4 臺獲取鎖成功才能認為成功,所以奇數更合理
事情可沒這么簡單,Redis 作者把這個方案提出后,受到了業界著名的分布式系統專家的質疑。
兩人好比神仙打架,兩人一來一回論據充足的對一個問題提出很多論斷……
Martin Kleppmann 提出質疑的博客:https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Redlock 設計者的回復:http://antirez.com/news/101
Redlock 是與非
Martin Kleppmann 認為鎖定的目的是為了保護對共享資源的讀寫,而分布式鎖應該「高效」和「正確」。
高效性:分布式鎖應該要滿足高效的性能,Redlock 算法向 5 個節點執行獲取鎖的邏輯性能不高,成本增加,復雜度也高;
正確性:分布式鎖應該防止并發進程在同一時刻只能有一個線程能對共享數據讀寫。
出于這兩點,我們沒必要承擔 Redlock 的成本和復雜,運行 5 個 Redis 實例并判斷加鎖是否滿足大多數才算成功。
主從架構崩潰恢復極小可能發生,這沒什么大不了的。使用單機版就夠了,Redlock 太重了,沒必要。
Martin 認為 Redlock 根本達不到安全性的要求,也依舊存在鎖失效的問題!
Martin 的結論
Redlock 不倫不類:對于偏好效率來講,Redlock 比較重,沒必要這么做,而對于偏好正確性來說,Redlock 是不夠安全的。
時鐘假設不合理:該算法對系統時鐘做出了危險的假設(假設多個節點機器時鐘都是一致的),如果不滿足這些假設,鎖就會失效。
無法保證正確性:Redlock 不能提供類似 fencing token 的方案,所以解決不了正確性的問題。為了正確性,請使用有「共識系統」的軟件,例如 Zookeeper。
Redis 作者 Antirez 的反駁
在 Redis 作者的反駁文章中,有 3 個重點:
時鐘問題:Redlock 并不需要完全一致的時鐘,只需要大體一致就可以了,允許有「誤差」,只要誤差不要超過鎖的租期即可,這種對于時鐘的精度要求并不是很高,而且這也符合現實環境。
網絡延遲、進程暫停問題:
客戶端在拿到鎖之前,無論經歷什么耗時長問題,Redlock 都能夠在第 3 步檢測出來
客戶端在拿到鎖之后,發生 NPC,那 Redlock、Zookeeper 都無能為力
質疑 fencing token 機制。
關于 Redlock 的爭論我們下期再見,現在進入 Redisson 實現分布式鎖實戰部分。
Redisson 分布式鎖
基于 SpringBoot starter 方式,添加 starter。
- <dependency>
- <groupId>org.redisson</groupId>
- <artifactId>redisson-spring-boot-starter</artifactId>
- <version>3.16.4</version>
- </dependency>
不過這里需要注意 springboot 與 redisson 的版本,因為官方推薦 redisson 版本與 springboot 版本配合使用。
將 Redisson 與 Spring Boot 庫集成,還取決于 Spring Data Redis 模塊。
「碼哥」使用 SpringBoot 2.5.x 版本, 所以需要添加 redisson-spring-data-25。
- <dependency>
- <groupId>org.redisson</groupId>
- <!-- for Spring Data Redis v.2.5.x -->
- <artifactId>redisson-spring-data-25</artifactId>
- <version>3.16.4</version>
- </dependency>
添加配置文件
- spring:
- redis:
- database:
- host:
- port:
- password:
- ssl:
- timeout:
- # 根據實際情況配置 cluster 或者哨兵
- cluster:
- nodes:
- sentinel:
- master:
- nodes:
就這樣在 Spring 容器中我們擁有以下幾個 Bean 可以使用:
- RedissonClient
- RedissonRxClient
- RedissonReactiveClient
- RedisTemplate
- ReactiveRedisTemplate
失敗無限重試
- RLock lock = redisson.getLock("碼哥字節");
- try {
- // 1.最常用的第一種寫法
- lock.lock();
- // 執行業務邏輯
- .....
- } finally {
- lock.unlock();
- }
拿鎖失敗時會不停的重試,具有 Watch Dog 自動延期機制,默認續 30s 每隔 30/3=10 秒續到 30s。
失敗超時重試,自動續命
- // 嘗試拿鎖10s后停止重試,獲取失敗返回false,具有Watch Dog 自動延期機制, 默認續30s
- boolean flag = lock.tryLock(10, TimeUnit.SECONDS);
超時自動釋放鎖
- // 沒有Watch Dog ,10s后自動釋放,不需要調用 unlock 釋放鎖。
- lock.lock(10, TimeUnit.SECONDS);
超時重試,自動解鎖
- // 嘗試加鎖,最多等待100秒,上鎖以后10秒自動解鎖,沒有 Watch dog
- boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
- if (res) {
- try {
- ...
- } finally {
- lock.unlock();
- }
- }
Watch Dog 自動延時
如果獲取分布式鎖的節點宕機,且這個鎖還處于鎖定狀態,就會出現死鎖。
為了避免這個情況,我們都會給鎖設置一個超時自動釋放時間。
然而,還是會存在一個問題。
假設線程獲取鎖成功,并設置了 30 s 超時,但是在 30s 內任務還沒執行完,鎖超時釋放了,就會導致其他線程獲取不該獲取的鎖。
所以,Redisson 提供了 watch dog 自動延時機制,提供了一個監控鎖的看門狗,它的作用是在 Redisson 實例被關閉前,不斷的延長鎖的有效期。
也就是說,如果一個拿到鎖的線程一直沒有完成邏輯,那么看門狗會幫助線程不斷的延長鎖超時時間,鎖不會因為超時而被釋放。
默認情況下,看門狗的續期時間是 30s,也可以通過修改 Config.lockWatchdogTimeout 來另行指定。
另外 Redisson 還提供了可以指定 leaseTime 參數的加鎖方法來指定加鎖的時間。
超過這個時間后鎖便自動解開了,不會延長鎖的有效期。
原理如下圖:
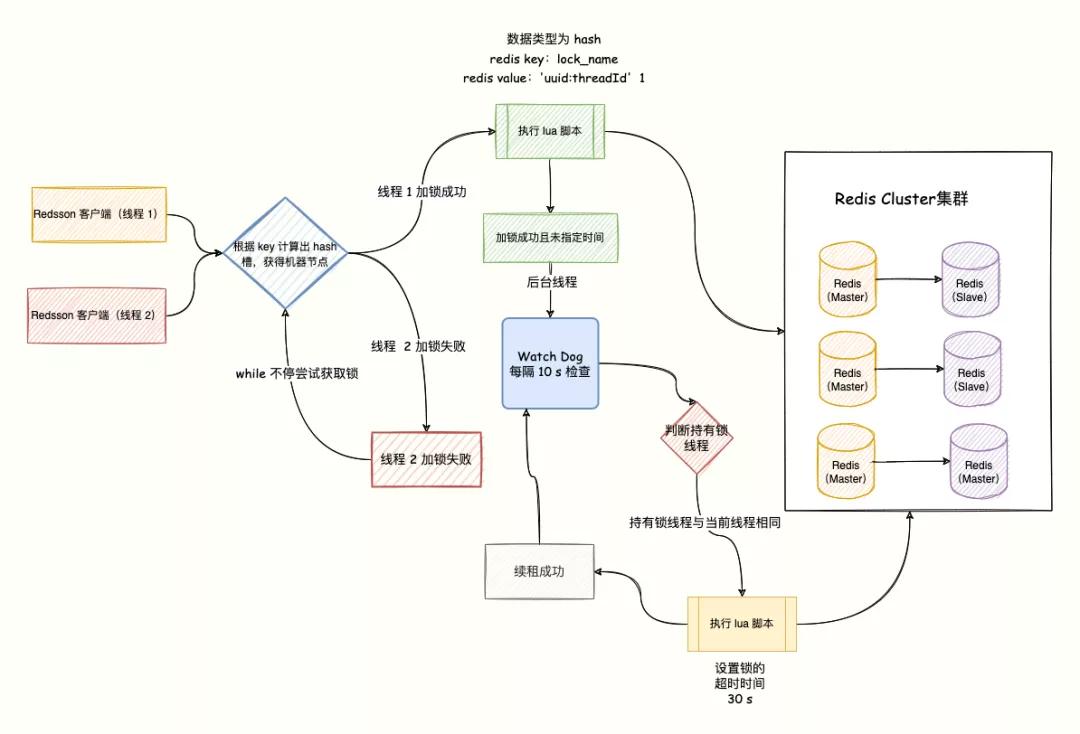
有兩個點需要注意:
- watchDog 只有在未顯示指定加鎖超時時間(leaseTime)時才會生效。
- lockWatchdogTimeout 設定的時間不要太小 ,比如設置的是 100 毫秒,由于網絡直接導致加鎖完后,watchdog 去延期時,這個 key 在 redis 中已經被刪除了。
源碼導讀
在調用 lock 方法時,會最終調用到 tryAcquireAsync。
調用鏈為:lock()->tryAcquire->tryAcquireAsync,詳細解釋如下:
- private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
- RFuture<Long> ttlRemainingFuture;
- //如果指定了加鎖時間,會直接去加鎖
- if (leaseTime != -1) {
- ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
- } else {
- //沒有指定加鎖時間 會先進行加鎖,并且默認時間就是 LockWatchdogTimeout的時間
- //這個是異步操作 返回RFuture 類似netty中的future
- ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
- TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
- }
- //這里也是類似netty Future 的addListener,在future內容執行完成后執行
- ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
- if (e != null) {
- return;
- }
- // lock acquired
- if (ttlRemaining == null) {
- // leaseTime不為-1時,不會自動延期
- if (leaseTime != -1) {
- internalLockLeaseTime = unit.toMillis(leaseTime);
- } else {
- //這里是定時執行 當前鎖自動延期的動作,leaseTime為-1時,才會自動延期
- scheduleExpirationRenewal(threadId);
- }
- }
- });
- return ttlRemainingFuture;
- }
scheduleExpirationRenewal 中會調用 renewExpiration 啟用了一個 timeout 定時,去執行延期動作。
- private void renewExpiration() {
- ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
- if (ee == null) {
- return;
- }
- Timeout task = commandExecutor.getConnectionManager()
- .newTimeout(new TimerTask() {
- @Override
- public void run(Timeout timeout) throws Exception {
- // 省略部分代碼
- ....
- RFuture<Boolean> future = renewExpirationAsync(threadId);
- future.onComplete((res, e) -> {
- ....
- if (res) {
- //如果 沒有報錯,就再次定時延期
- // reschedule itself
- renewExpiration();
- } else {
- cancelExpirationRenewal(null);
- }
- });
- }
- // 這里我們可以看到定時任務 是 lockWatchdogTimeout 的1/3時間去執行 renewExpirationAsync
- }, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
- ee.setTimeout(task);
- }
scheduleExpirationRenewal 會調用到 renewExpirationAsync,執行下面這段 lua 腳本。
他主要判斷就是 這個鎖是否在 redis 中存在,如果存在就進行 pexpire 延期。
- protected RFuture<Boolean> renewExpirationAsync(long threadId) {
- return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
- "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
- "redis.call('pexpire', KEYS[1], ARGV[1]); " +
- "return 1; " +
- "end; " +
- "return 0;",
- Collections.singletonList(getRawName()),
- internalLockLeaseTime, getLockName(threadId));
- }
- watch dog 在當前節點還存活且任務未完成則每 10 s 給鎖續期 30s。
- 程序釋放鎖操作時因為異常沒有被執行,那么鎖無法被釋放,所以釋放鎖操作一定要放到 finally {} 中;
- 要使 watchLog 機制生效 ,lock 時 不要設置 過期時間。
- watchlog 的延時時間 可以由 lockWatchdogTimeout 指定默認延時時間,但是不要設置太小。
- watchdog 會每 lockWatchdogTimeout/3 時間,去延時。
- 通過 lua 腳本實現延遲。
總結
完工,我建議你合上屏幕,自己在腦子里重新過一遍,每一步都在做什么,為什么要做,解決什么問題。
我們一起從頭到尾梳理了一遍 Redis 分布式鎖中的各種門道,其實很多點是不管用什么做分布式鎖都會存在的問題,重要的是思考的過程。
對于系統的設計,每個人的出發點都不一樣,沒有完美的架構,沒有普適的架構,但是在完美和普適能平衡的很好的架構,就是好的架構。
本文轉載自微信公眾號「碼哥字節」,可以通過以下二維碼關注。轉載本文請聯系碼哥字節公眾號。


























