













SQL中刪除重復數據問題
作者: 丶平凡世界
我們數據庫中最后要保留的結果就是第二步中查詢出來的數據,我們把其他的數據刪除即可。怎么刪除呢?我們使用ID來排除。
本文轉載自微信公眾號「SQL數據庫開發」,作者丶平凡世界 。轉載本文請聯系SQL數據庫開發公眾號。
需求分析
數據庫中存在重復記錄,刪除保留其中一條(是否重復判斷基準為多個字段)
解決方案
碰到這樣的問題我們先分解步驟來看
- 創建測試數據
- 找到重復的數據
- 刪除重復的數據并且保留一行
創建測試數據
我們創建一個人員信息表并在里面插入一些重復的數據。
- CREATE TABLE [dbo].[Person](
- [ID] [INT] IDENTITY(1,1) NOT NULL,
- [Name] [VARCHAR](20) NULL,
- [Age] [INT] NULL,
- [Address] [VARCHAR](20) NULL,
- [Sex] [CHAR](2) NULL
- );
- SET IDENTITY_INSERT [dbo].[Person] ON;
- INSERT INTO [dbo].[Person] (ID,Name,Age,Address,Sex)
- VALUES
- ( 1, '張三', 18, '北京路18號', '男' ),
- ( 2, '李四', 19, '北京路29號', '男' ),
- ( 3, '王五', 19, '南京路11號', '女' ),
- ( 4, '張三', 18, '北京路18號', '男' ),
- ( 5, '李四', 19, '北京路29號', '男' ),
- ( 6, '張三', 18, '北京路18號', '男' ),
- ( 7, '王五', 19, '南京路11號', '女' ),
- ( 8, '馬六', 18, '南京路19號', '女' );
- SET IDENTITY_INSERT [dbo].[Person] OFF;
(提示:可以左右滑動代碼)
建立好測試數據如下:
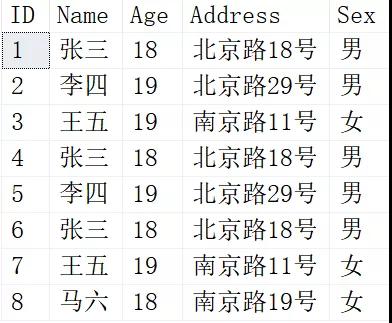
我們發現除了自增長ID不同以為,有幾條其他字段都重復的數據出現,符合我們的需求。
找出重復的數據
- SELECT MAX(ID) ID ,
- Name,Age,Address,Sex
- FROM dbo.Person
- GROUP BY Name,Age,Address,Sex
- HAVING COUNT(1)>1
HAVING將分組后統計出來的數量大于1的數據行,就是我們要找的重復數據:
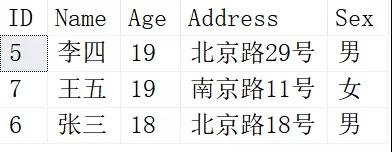
上面用Max函數或者Min函數均可,只是為了保證取出來的數據的唯一性。
刪除重復的數據
其實我們數據庫中最后要保留的結果就是第二步中查詢出來的數據,我們把其他的數據刪除即可。怎么刪除呢?我們使用ID來排除。
- DELETE FROM Person
- WHERE EXISTS
- (
- SELECT * FROM (
- SELECT
- MAX(ID) ID,
- Name,Age,Address,Sex
- FROM dbo.Person
- GROUP BY Name,Age,Address,Sex
- HAVING COUNT(1)>1) T
- WHERE Person.Name=T.Name
- AND Person.Age=T.Age
- AND Person.Address=T.Address
- AND Person.Sex=T.Sex
- AND Person.ID<T.ID--如果上面使用MIN函數,這里就要改成>
- )
執行完后重新查詢Person表結果如下:
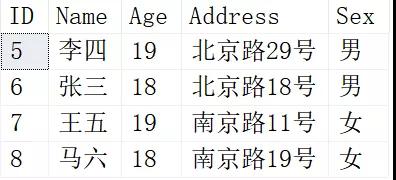
馬六因為只有一條記錄,所以沒有參與去重,直接顯示。
今天的案例分享結束,小伙伴們可以自己動手嘗試一下,興許工作中也會遇到類似問題。如果你在公眾中遇到一些有趣的問題也可以發送給我。
責任編輯:武曉燕
來源:
SQL數據庫開發












