













AI打王者、星際爭霸……你還不懂背后技術?這有一份游戲AI綜述
人機游戲有著悠久的歷史,已經(jīng)成為驗證人工智能關鍵技術的主流。圖靈測試可以說是人類首次進行人機對抗測試,這激發(fā)了研究人員設計各類 AI 來挑戰(zhàn)職業(yè)人類玩家。例如,1989 年研究者開發(fā)了國際跳棋程序 Chinook,目標是擊敗世界冠軍,1994 年 Chinook 打敗了美國西洋跳棋棋王 Marion Tinsley。在之后的時間里,IBM 的深藍在 1997 年擊敗國際象棋大師 Garry Kasparov,開創(chuàng)了國際象棋史上的新紀元。
近年來,我們見證了游戲 AI 的快速發(fā)展,從 Atari、AlphaGo、Libratus、OpenAI Five 到 AlphaStar 。這些 AI 通過結合現(xiàn)代技術在某些游戲中擊敗了職業(yè)人類玩家,標志著決策智能領域的快速發(fā)展。
AlphaStar(DeepMind 開發(fā)的計算機程序) 和 OpenAI Five(美國人工智能研究和 OpenAI 開發(fā))分別在星際爭霸和 Dota2 中達到了專業(yè)玩家水平。現(xiàn)在看來,目前的技術可以處理非常復雜的不完美信息游戲,特別是在最近大火的王者榮耀等游戲中的突破,它們都遵循了類似 AlphaStar 和 OpenAI Five 的框架。我們不禁會問:人機游戲 AI 的未來趨勢或挑戰(zhàn)是什么?來自中國科學院自動化研究所以及中國科學院大學的研究者撰文回顧了最近典型的人機游戲 AI,并試圖通過對當前技術的深入分析來回答這些問題。

論文地址:https://arxiv.org/pdf/2111.07631.pdf
具體而言,該研究總共調(diào)查了四種典型的游戲類型,即圍棋棋盤游戲;紙牌游戲(德州撲克 HUNL、斗地主和麻將);第一人稱射擊類游戲 (FPS)(雷神之錘 III 競技場);實時戰(zhàn)略游戲 (RTS)(星際爭霸、Dota2 和王者榮耀) 。上述游戲對應的 AI 包括 AlphaGo、AlphaGo Zero 、AlphaZero、Libratus、DeepStack、DouZero、Suphx、FTW、AlphaStar、OpenAI Five、JueWu 和 Commander。圖 1 為一個簡短的概要:
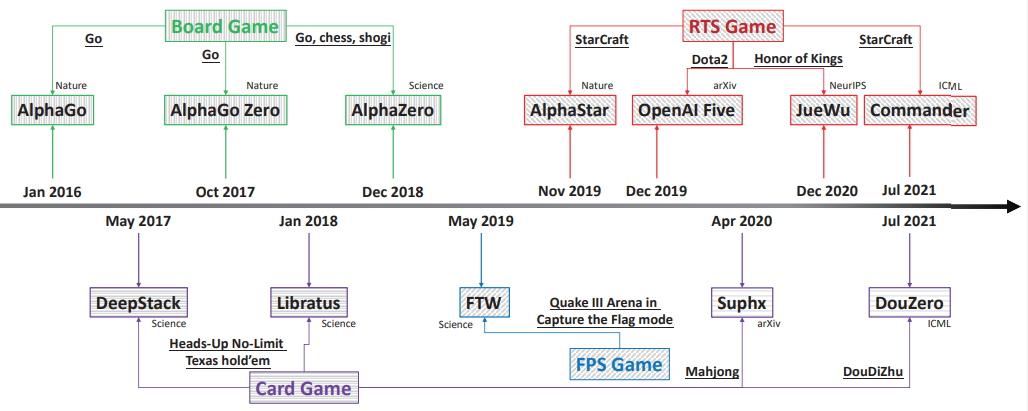
本文調(diào)查的游戲以及 AI
總體而言:在第 2 節(jié)中,該研究描述了本文涵蓋的游戲和使用的AI;第 3-6 節(jié)分別闡述了棋盤游戲、紙牌游戲、FPS 游戲和 RTS 游戲對應的 AI;在第 7 節(jié)總結并比較了各類游戲所使用的不同技術;在第 8 節(jié)展示了當前游戲 AI 面臨的挑戰(zhàn),這些挑戰(zhàn)可能是該領域未來的研究方向。最后,第 9 節(jié)對論文進行了總結。
典型的游戲和 AI
下表提取了不同游戲挑戰(zhàn)智能決策的關鍵因素,如表 1 所示:
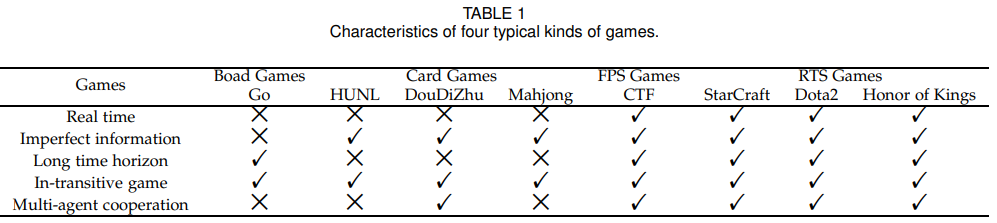
上表列出了不同游戲的優(yōu)缺點,我們需要根據(jù)不同的游戲類型,分配不同的 AI。因為不同的游戲具有不同的特點,其解決方案也各不相同,因此研究者開發(fā)了不同的學習策略來構建 AI 系統(tǒng)。在本文中,AI 被進行不同的分配:AlphaGo、AlphaGo Zero、AlphaZero 用于棋盤游戲;Libratus、DeepStack、DouZero 和 Suphx 分別用于紙牌游戲 HUNL、斗地主和麻將;FTW 用于 FPS 游戲中的雷神之錘 III 競技場;AlphaStar、Commander、OpenAI Five 和 JueWu 分別用于星際爭霸、Dota2 和王者榮耀。
不同游戲對應的 AI
棋盤游戲 AI
AlphaGo 系列由 AlphaGo、AlphaGo Zero 和 AlphaZeo 組成。2015 年問世的 AlphaGo 以 5:0 擊敗歐洲圍棋冠軍樊麾,這是軟件首次在全尺寸棋盤對職業(yè)棋手的比賽中取得這樣的成績。之后,DeepMind 為 AlphaGo Zero 開發(fā)了新的訓練框架,事先無需專業(yè)的人類對抗數(shù)據(jù),取得了卓越的表現(xiàn)。AlphaZero,是一種通用強化學習算法。AlphaGo 系列總結如圖 2 所示:
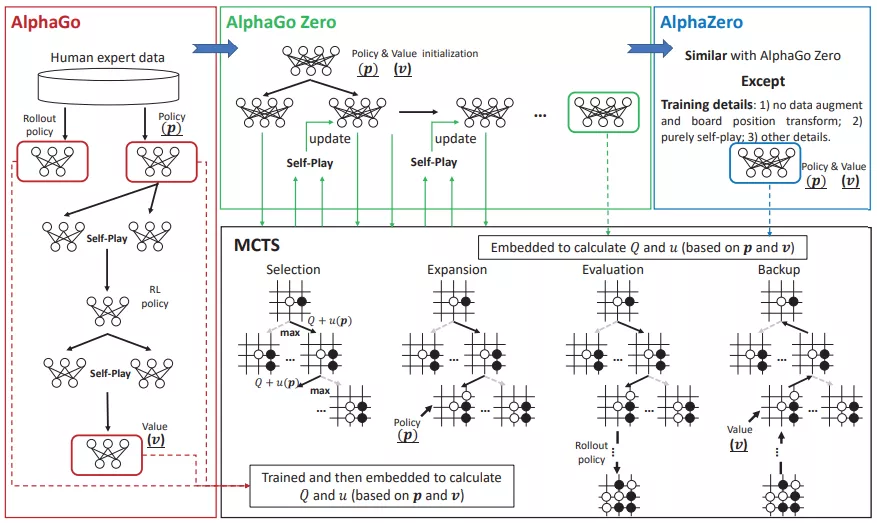
AlphaGo 系列框架圖
紙牌游戲 AI
紙牌游戲作為典型的不完美信息游戲,長期以來一直是人工智能的挑戰(zhàn)。DeepStack 和 Libratus 是在 HUNL 中擊敗職業(yè)撲克玩家的兩個典型 AI 系統(tǒng)。它們共享基礎技術,即這兩者在 CFR 理論上相似。之后,研究人員專注于麻將和斗地主這一新的挑戰(zhàn)。由微軟亞洲研究院開發(fā)的 Suphx 是第一個在麻將中勝過多數(shù)頂級人類玩家的人工智能系統(tǒng)。DouZero 專為斗地主設計,這是一個有效的 AI 系統(tǒng),在 Botzone 排行榜 344 個 AI 智能體中排名第一。紙牌游戲 AI 的簡要框架如下圖所示:
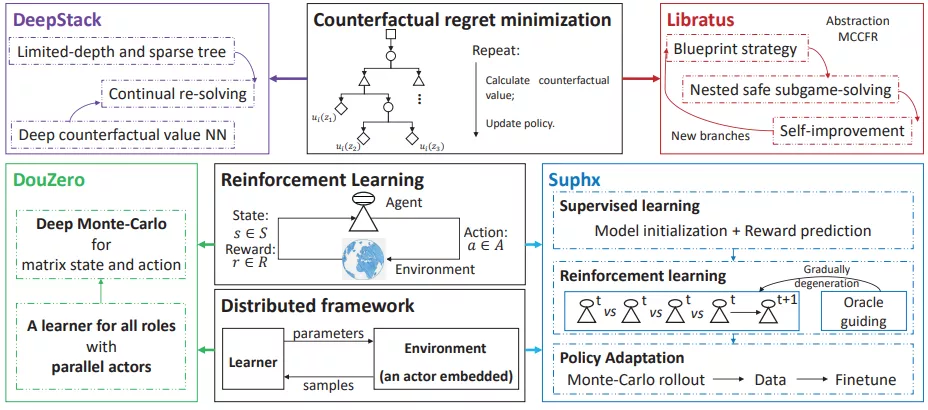
紙牌游戲 AI 的簡要框架
第一人稱射擊(FPS)游戲 AI
雷神之錘 III 競技場是一款典型的 3D 多人第一人稱視角電子游戲,其中兩個對立的團隊在室內(nèi)或室外地圖中相互對抗。CTF 設置與當下多人電子游戲有很大不同。更具體地說,CTF 中的智能體無法訪問其他玩家的狀態(tài),此外,團隊中的智能體無法相互通信,這樣的環(huán)境是學習智能體進行通信和適應零樣本生成最優(yōu)測試平臺。零樣本意味著智能體進行協(xié)作或對抗不是經(jīng)過訓練而來的,可以是人類玩家和任意的 AI 智能體訓練而來,僅基于像素和人類等游戲點作為智能體的輸入,學習智能體 FTW 框架可以達到人類級性能。游戲 CTF 的 FTW 框架如下圖所示:
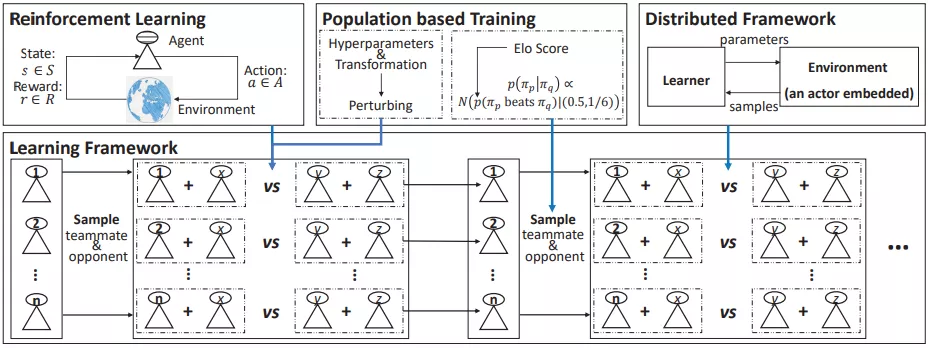
游戲 CTF 的 FTW 框架
RTS 游戲 AI
RTS(即時戰(zhàn)略)游戲作為一種典型的電子游戲,多達數(shù)萬人相互對戰(zhàn),RTS 通常被作為人機游戲的試驗臺。此外,RTS 游戲通常環(huán)境復雜,比以往游戲更能捕捉現(xiàn)實世界的本質(zhì),這種特性使得此類游戲更具適用性。DeepMind 開發(fā)的 AlphaStar 使用通用學習算法,在星際爭霸的所有三個種族中都達到了大師級別,其性能超過 99.8% 的人類玩家(總數(shù)約 90000 名玩家)。Commander 作為輕量級的計算版本,遵循 AlphaStar 相同的訓練架構,使用更少的計算量級,并在現(xiàn)場賽事中擊敗兩名特級高手。OpenAI Five 旨在解決 Dota2 游戲,這是第一個在電子競技游戲中擊敗世界冠軍的 AI 系統(tǒng)。作為與 Dota2 比較相似的電競游戲,《王者榮耀》面臨的挑戰(zhàn)最為相似,覺悟成為第一個可以玩完整 RTS 游戲而不限制英雄池的 AI 系統(tǒng)。典型 RTS 游戲的簡單 AI 框架如下圖所示:
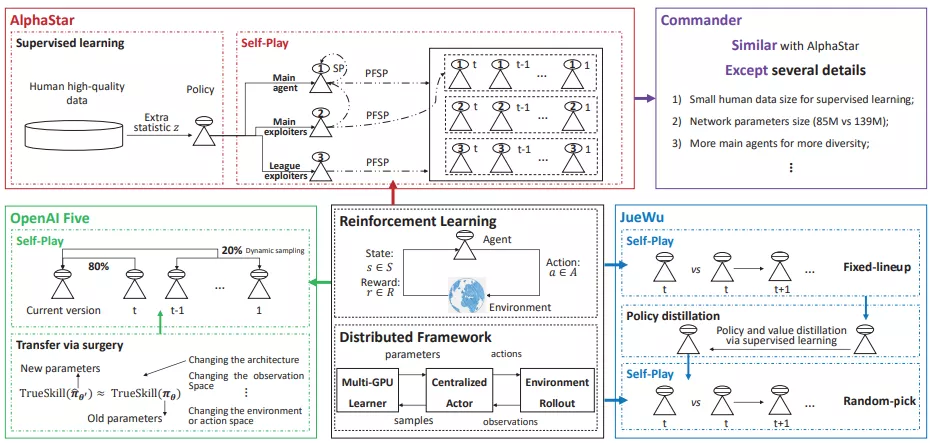
一個典型 RTS 游戲的簡單 AI 框架
挑戰(zhàn)和未來趨勢
盡管計算機游戲已經(jīng)取得了很大的進步,但當前技術仍然面臨著諸多挑戰(zhàn),例如大量依賴計算資源等,這將激發(fā)未來的研究。
大模型
如今,大模型,尤其是預訓練大模型,正在從自然語言處理發(fā)展到計算機圖像處理,從單模態(tài)到多模態(tài)。即使在零樣本設置中,這些模型也證明了其在下游任務的巨大潛力,這是探索通用人工智能的一大步。
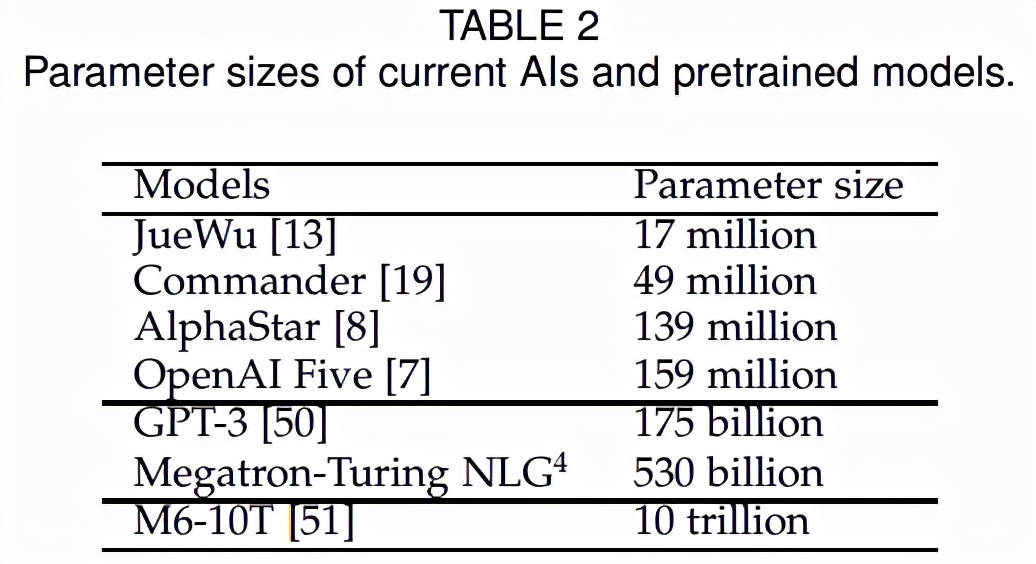
OpenAI 開發(fā)了 GPT-3,它擁有超過 1750 億個參數(shù),并在各種語言相關任務中表現(xiàn)出良好的性能。然而,游戲中的大模型基本沒有,當前復雜游戲的模型比那些參數(shù)多的大模型要小得多。如表 2 所示,AlphaStar 和 OpenAI Five 分別只有 1.39 億和 1.59 億的參數(shù):
考慮到大模型是對通用人工智能的一個比較好的探索,如何在游戲中為人工智能設計和訓練大模型,可能會為那些時序決策領域提供新的解決方案。為了進行這樣的嘗試,該研究認為至少應該仔細考慮兩個問題:
- 首先,游戲任務與自然語言處理任務非常不同,因此如何明確訓練目標是大模型的關鍵步驟;
- 其次,由于游戲難易程度不同,如何設計合適的訓練機制比較困難。訓練方法應該能夠處理各種游戲并確保學習不會退化。
低資源 AI
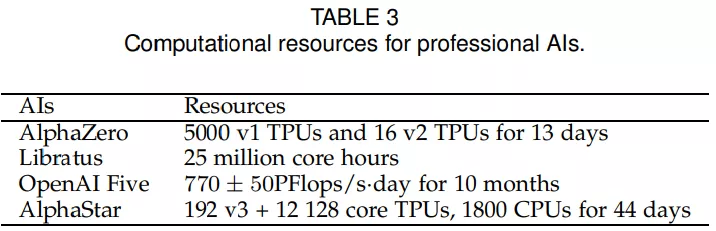
為了在復雜環(huán)境中訓練專業(yè)級 AI,通常需要大量的計算資源。從表 3 得出我們需要大量的資源投入來訓練 AI。
我們不禁會問,是否可以在資源有限的情況下訓練出專業(yè)級的人工智能。一個直觀的想法是引入更多的人類知識來輔助學習,強化學習可以說是未來的一個發(fā)展方向。另一方面,開發(fā)出理論和易于計算的進化策略,將是低資源人工智能系統(tǒng)的關鍵一步。
評估
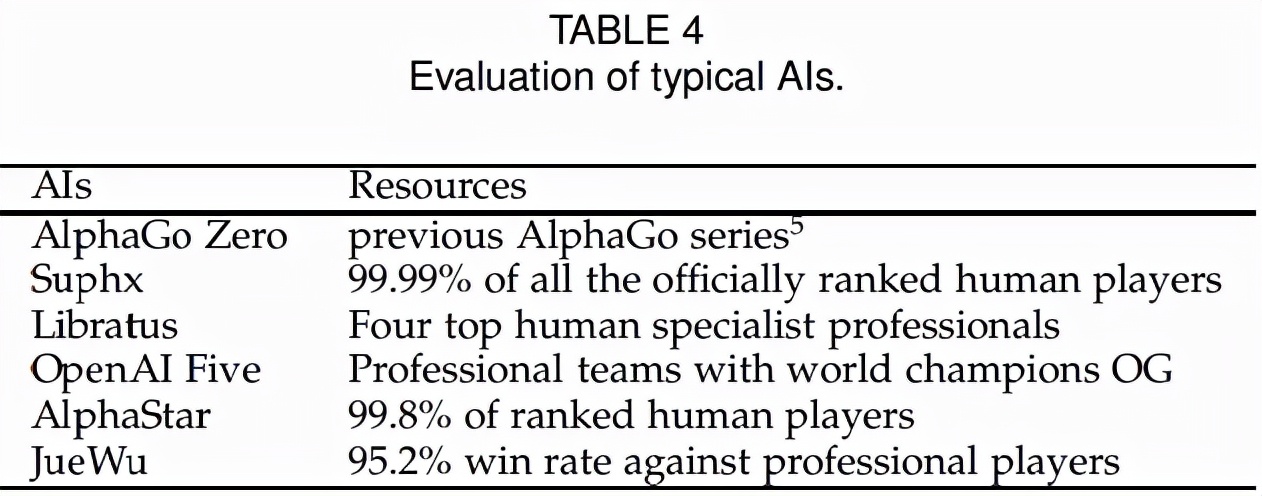
目前,對智能體的精確評估成為一個難題。人機游戲通常采用基于獲勝概率(對職業(yè)人類玩家)的評價標準,如表 4 所示。但是,這種評價比較粗糙,尤其是在有限的非遷移游戲測試下。如何為大多數(shù)游戲制定一個系統(tǒng)的評價標準是一個重要而開放的問題。
通過這篇文章,研究者希望初學者能夠快速熟悉游戲 AI 這個領域的技術、挑戰(zhàn)和機遇,并能啟發(fā)在路上的研究人員進行更深入的研究。

















