













我們一起聊聊如何理解字節序
計算機只能理解 0 和 1 組成的二進制數據, 一個 bit 的值是 0 或 1,八個這樣的 bit 組成了一個字節,通過字節,計算機可以表示一些復雜的數據,比如:音頻、視頻等,有些數據用一個字節就能表示,比如英文字符,而有些數據需要多個字節來表示,比如:漢字, 對于多字節的數據,存儲的時候會有字節順序的問題,也就是字節序
字節序是什么
字節序是計算機存儲多字節數據的方式,目前的方式有:大端字節序和小端字節序,字節序主要是針對多字節的數據類型,比如 short、int 等
- 大端字節序
高位字節存儲在內存的低地址上,低位字節存儲在內存的高位地址上
- 小端字節序
高位字節存儲在內存的高地址上,低位字節存儲在內存的低地址上
如何理解字節序
我們平常書寫和閱讀數字的習慣是從左到右的,所以把最左邊的字節當作最高位字節,最右邊的字節當作做最低位字節,從左到右,表示從高位字節到低位字節
例如:對于 0x01020304,它的大端和小端字節序在內存中的布局如下圖所示
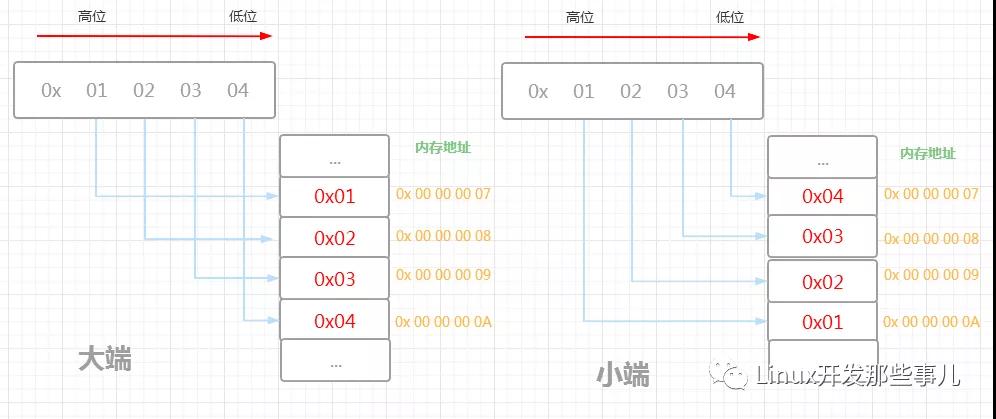
0x 01 02 03 04 總共四個字節大小,以人們習慣的閱讀順序,0x01 處于左邊,屬于高位字節,0x04 處于右邊,屬于低位字節
內存地址從 0x 00 00 00 07 到 0x 00 00 00 0A 4個字節的空間,剛好能存儲得下
根據大端字節序的的規則:高位字節存儲在內存低地址,所以處于高位字節的 0x01 存儲在 0x 00 00 00 07 地址處,緊接著 次高位字節 0x02 存儲在次低地址 0x 00 00 00 08 處,剩下的兩個字節 0x03 和 0x04 分別存儲于 0x 00 00 00 09 和 0x 00 00 00 0A 地址處,最后的結果是 0x 01 02 03 04
小端字節序和大端剛好相反,它指的是 高位字節存儲在內存高地址處,所以處于高位字節的 0x01 存儲在 0x 00 00 00 0A 地址處,次高位字節 0x02 存儲在次高地址 0x 00 00 00 09 處,余下的 0x03 和 0x04 分別存儲于 0x 00 00 00 08 和 0x 00 00 00 07 地址處,最后的結果是 0x 04 03 02 01
從上圖可以看出,對于相同的數據,大端和小端的內存布局是不一樣的,大端字節序的存儲形式更符合人們平常書寫和閱讀的習慣
為什么會有字節序
可能有人會感到疑惑:既然大端字節序更符合人們閱讀的習慣,為什么不全部都采用大端的方式,這樣也就不會有字節序的問題了 ?
確實,如果所有平臺都用同一種存儲順序,就沒有字節序這一說法了
在早期, CPU 只有幾千個邏輯門,小端的方式能更有效的使用邏輯電路,所以很多計算機內部計算都采用小端的方式,這種方式也就保留到了現在
另外,字節序是跟 CPU 架構相關,不同的廠家設計的規范可能都不一樣,比如 Intel 的 x86 是小端方式,而 IBM 的 PowerPC 則采用大端方
大端的方式更符合人們的閱讀習慣,因此大部分網絡傳輸以及文件存儲都是大端的方式
總的來說,小端主要是在計算機內部使用,大端則在外部使用
計算機如何處理字節序
計算機讀取數據的時候是不區分字節序的,它總是從內存低地址到高地址的順序,按字節讀取
下面的示例圖展示了數據 0x0102 的 大端和小端的內存布局以及CPU讀取內存的順序
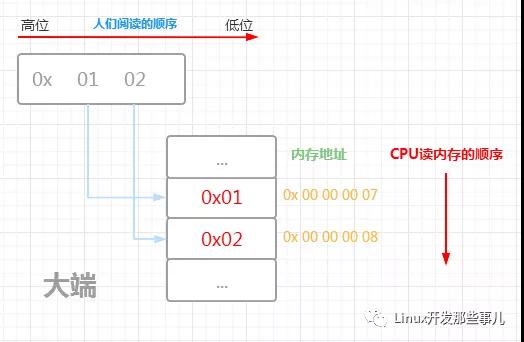
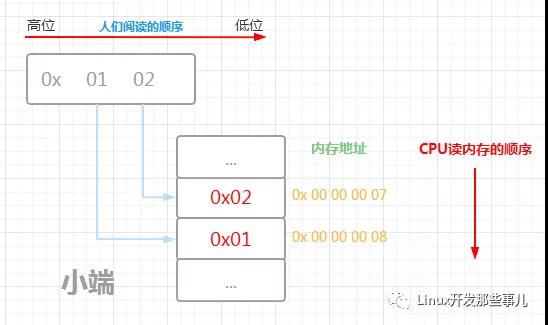
由上圖可知,對于大端字節序來說,內存低地址處存儲的是高位字節,也即計算機讀取內存的第一個字節就是高位字節,小端字節序就正好相反,內存低地址處存儲的是低位字節,讀取內存的第一個字節是低位字節
計算機只有在讀取數據的時候才需要區分字節序
就拿上面展示大端方式的圖 ( 第一張 ) 來說,內存 0x 00 00 00 07 地址處存儲的數據是 0x01 , 0x 00 00 00 08 地址處存儲的數據是 0x02
如果是以大端的方式讀取的話,地址 0x 00 00 00 07 處的數據 0x01 會放到高位字節, 0x 00 00 00 08 處的數據是 0x02 放到低位字節,最終這兩個字節的數據是 0x 01 02
如果是以小端的方式讀取的話,,地址 0x 00 00 00 07 處的數據 0x01 會放到低位字節, 0x 00 00 00 08 處的數據是 0x02 放到高位字節,最終這兩個字節的數據是 0x 02 01
網絡字節序
所有的協議都是人類編制定的,大端對人們閱讀更友好,所以 IEEE 標準協會規定除非有明確說明,否則網絡協議都使用大端字節序, 像 TCP/IP 就是如此
還記得我們在編寫網絡程序的時候,傳入 connect 函數實參中的 端口號嗎, 傳入之前需調用 htons 函數將其轉成網絡字節序,也就是要轉成大端字節序,下面是部分代碼示例
- struct sockaddr_in addr;
- addr.sin_family = AF_INET;
- addr.sin_addr.s_addr = inet_addr("192.168.1.10");
- addr.sin_port = htons( 5000 );
- connect( clientfd, (struct sockaddr *)&addr, sizeof(addr)) )
上面紅色的 htons 函數的作用是將 端口號 由主機字節序轉成網絡字節序,網絡字節序大多時候都是固定為大端序的,但不同的機器,主機序卻不一樣,如果本身就已經是大端了,調用 htons 函數,返回值和實參是一樣的,如果本身是小端,結果會轉成大端的形式,具體的數值也會不一樣
怎么判斷大小端
上面提到了主機字節序,那如何知道當前機器是大端還是小端呢 ?
因為操作系統必須適配所有類型的 CPU ,所以對于操作系統來說,大端和小端它都是支持的
為了讓程序易于判斷當前平臺是大端還是小端,Linux 下 glibc 庫提供了下面幾個宏定義
- BIG_ENDIAN # 大端序
- LITTLE_ENDIAN # 小端序
- BYTE_ORDER # 字節序
下面是測試代碼 test.c 文件
- #include <stdio.h>
- int main(int argc, char *argv[])
- {
- if(BYTE_ORDER == BIG_ENDIAN)
- {
- printf("big endian...\n");
- }
- else
- {
- printf("little endian...\n");
- }
- }
執行 gcc -g -o test test.c 命令進行編譯,運行測試程序,結果如下:
- [root@localhost test]# ./test
- little endian...
由此,可以知道當前平臺是小端字節序
除了用上面的方法之外,我們可以根據大端和小端的特點,自己寫代碼獲取,修改 test.c 文件,內容如下
- #include <stdio.h>
- int main(int argc, char *argv[])
- {
- union
- {
- unsigned short i;
- char ch[2];
- }un;
- un.i = 0x0102;
- if(0x01 == un.ch[0])
- {
- printf("big endian...\n");
- }
- else
- {
- printf("little endian...\n");
- }
- }
編譯并運行,結果如下:
- [root@localhost test]# ./test
- little endian...
可以看出,不管是通過系統庫提供的宏來判斷還是自行封裝接口來判斷機器的字節序都是可行的
最后,如果想知道 LITTLE_ENDIAN、 BIG_ENDIAN 、BYTE_ORDER 宏定義的詳細情況,可以查看 glibc 源碼,它們在 glibc-2.17\string\endian.h 以及 glibc-2.17\sysdeps\x86\bits\endian.h 文件中
注意:不同版本的 glibc 源碼,具體的位置可能有差異,我使用的是 glibc-2.17 版本
大端小端的轉換
熟悉了大端和小端特點,它們之間的轉換就簡單了,對于兩字節來說,每個字節值不變,互換字節位置,如果是更多字節的話,最低位字節和最高位字節交換,次低位字節與次高位字節交換,直到所有字節都完成了一遍交換為止
比如:下面是小端轉大端的偽代碼
- #小端轉大端 假設:ch 和 i 是小端序
- char ch[2];
- int i = 0;
- # x 是大端字節序
- x = ch[1] << 8 | ch[0]
- # y 是大端字節序
- y = ( (i & 0xff000000) >> 24 ) | ( (i & 0x00ff0000) >> 8 ) | ( (i & 0x0000ff00) << 8 ) | ( (i & 0x000000ff) << 24 )
變量 i 字節序轉換說明:按照從左到右的順序,把 i 的第一個字節右移 3 個字節( 24 bit ),第二個字節右移 1 字節 ( 8 bit ),第三個字節左移 1 字節 ( 8 bit ),第四個字節左移 3 個字節 ( 24 bit ),最后把移位后的字節組合起來就可以了
在實際的程序處理中,不應該出現字節序的問題,只有 "網絡字節序" 和 "主機字節序" ,需要轉換字節序時,使用 ntohl, ntohs, htonl, htons 等函數即可
- ntohl # uint32 類型 網絡序轉主機序
- htonl # uint32 類型 主機序轉網絡序
- ntohs # uint16 類型 網絡序轉主機序
- htons # uint16 類型 主機序轉網絡序
小結
本文詳述了字節序的一些知識,開發網絡應用的時候會涉及到字節序的相關問題,所以,花點兒時間弄明白還是很有必要的




























