













超長字符串字段,前綴索引兩宗罪
本文轉載自微信公眾號「飛天小牛肉」,作者小牛肉。轉載本文請聯系飛天小牛肉公眾號。
前綴索引并不是一個難理解的東西,但是這里面涉及到的一些細節,我相信很多同學都沒有去深入了解過。
老規矩,前綴索引相關面試題的背誦版在文末。點擊閱讀原文可以直達我收錄整理的各大廠面試真題
InnoDB 表中每一列索引的最大長度不能超過 767 字節,所以,對于某些比較長的字段,如果確實有建立索引的必要,使用前綴索引不僅能夠避免索引長度超過限制,而且相對于普通索引來說,占用的空間和查詢成本更小。
至于為什么說前綴索引占用的空間和查詢成本更小,我們來直接上個例子:
假設表中存在一個郵箱 email 字段,我們在這個字段上面分別創建普通索引和前綴索引:
1)普通索引,包含了每行 email 記錄的的整個字符串:alter table user add index index1(email);
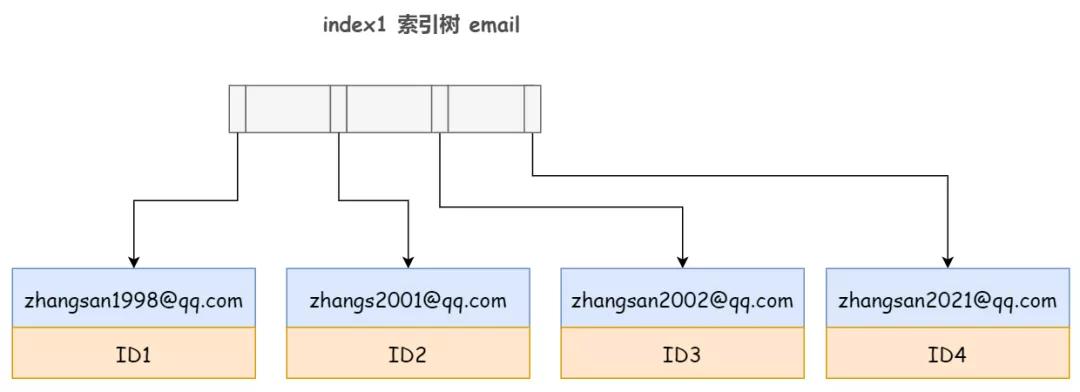
2)前綴索引,取每行 email 記錄的前 6 個字節:alter table user add index index2(email(6));
你可以看到,由于 email(6) 這個索引結構中每個 email 字段都只取前 6 個字節 zhangs,所以占用的空間比普通索引更小,這就是使用前綴索引的優勢。
很好理解,對吧。
前綴索引一宗罪
但是,前綴索引這個占用空間更小的優勢可能會帶來額外的記錄掃描次數。
舉個例子,執行如下 sql 語句:
- select * from user where email = 'zhangs2001';
1)對于普通索引 email 來說,執行順序如下:
- 從 index1 索引樹找到第一個滿足索引值是 'zhangs2001' 的這條記錄,并獲取到主鍵 ID2 的值;
- 根據主鍵值回表查詢,獲取其他相應的記錄,然后將獲取到的結果加入結果集;
- 取 index1 索引樹上剛剛查到的位置的下一條記錄,發現已經不滿足 email='zhangs2001' 的條件了,結束執行
這個過程中,只需要回表一次
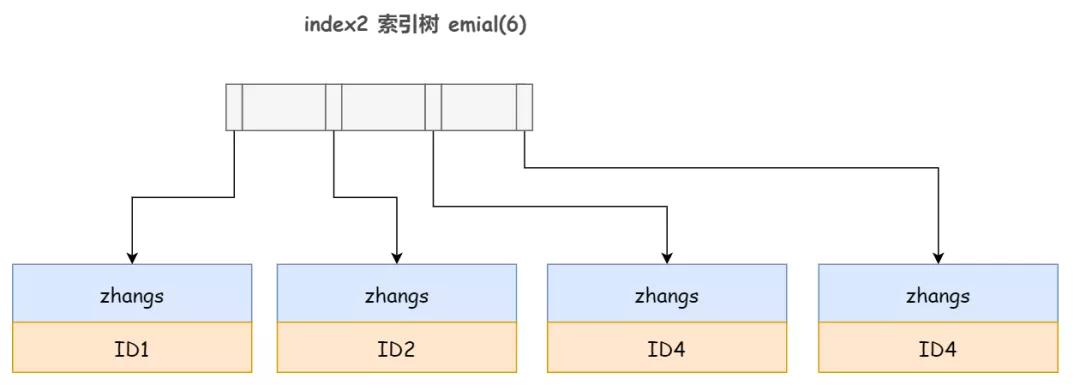
2)對于前綴索引 email(6) 來說,執行順序如下:
- 從 index1 索引樹找到第一個滿足索引值是 'zhangs' 的這條記錄,并獲取到主鍵 ID1 的值;
- 根據主鍵值回表查詢,判斷 email 的值到底是不是 'zhangs2001',發現并不是,這行記錄丟棄
- 取 index1 索引樹上剛剛查到的位置的下一條記錄,發現 email 前綴仍然滿足 'zhangs',則獲取到主鍵 ID2 的值;然后根據主鍵值回表查詢,返現 email 的值確實是 'zhangs2001',則將這行記錄加入結果集
- 如此重復,直到 email 前綴不再是 'zhangs',則執行結束
可以看到,這個過程中,需要回表四次
這就是前綴索引的第一宗罪:使用前綴索引可能會增加記錄掃描次數與回表次數,影響性能
不過呢,我們做一些細微的改變,就能讓這個前綴索引回表次數大大減少。
把 index2-email(6) 這個前綴索引改成 index3-email(7):
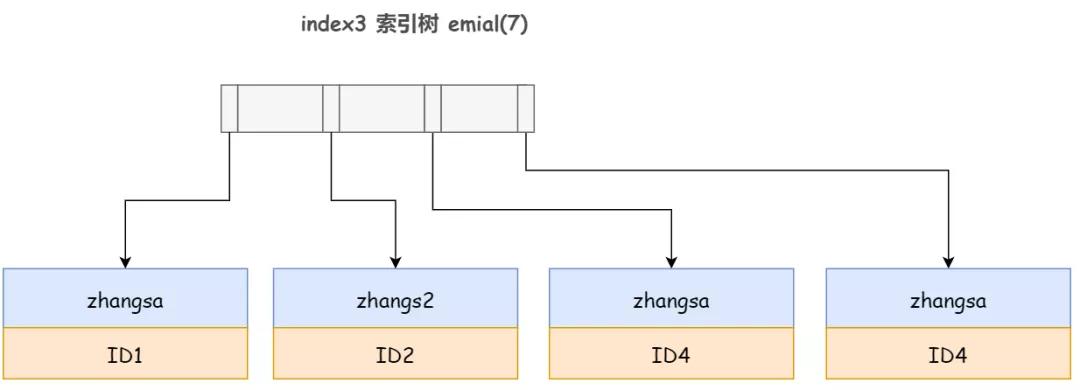
再來看上面這個例子,執行順序如下:
- 從 index1 索引樹找到第一個滿足索引值是 'zhangs2' 的這條記錄,并獲取到主鍵 ID2 的值;
- 根據主鍵值回表查詢,判斷 email 的值到底是不是 'zhangs2001',發現確實是,則將這行記錄加入結果集
- 取 index1 索引樹上剛剛查到的位置的下一條記錄,發現 email 前綴不滿足 'zhangs2',則執行結束
可以看到,相對于普通索引,email(7) 這個前綴索引同樣只需要回表一次,并且占用更少的索引空間。
前綴索引二宗罪
看下面這條 SQL 語句:
- select id,email from user where email = 'zhangs2001';
如果使用 index1 索引(即 email 整個字符串的索引結構)的話,可以利用上覆蓋索引,從 index1 索引樹上查到結果后就可以返回了,不需要進行回表。
而如果使用 index2(即 email(6) 前綴索引結構)的話,就不得不再次根據主鍵值去回表判斷 email 字段的值是否真的是 'zhangs2001'。也就是說,使用前綴索引就用不上覆蓋索引對查詢性能的優化了。
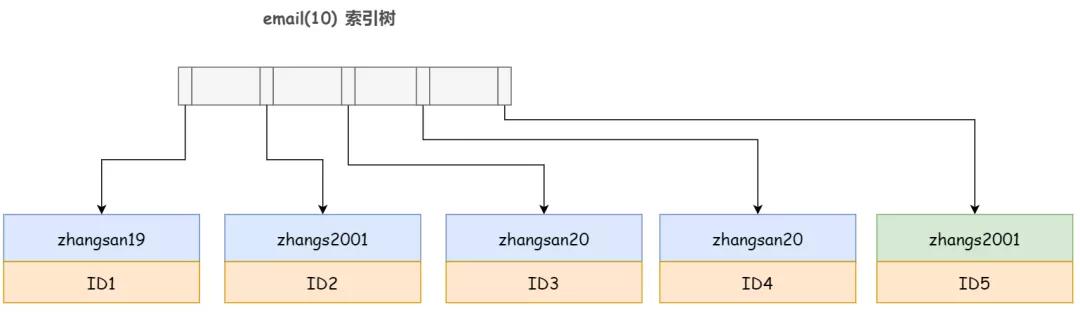
那有同學就要問了,如果是 email(10) 呢,這個前綴索引不就完全包含了 zhangs2001 的所有信息了嘛,還需要回表嗎?
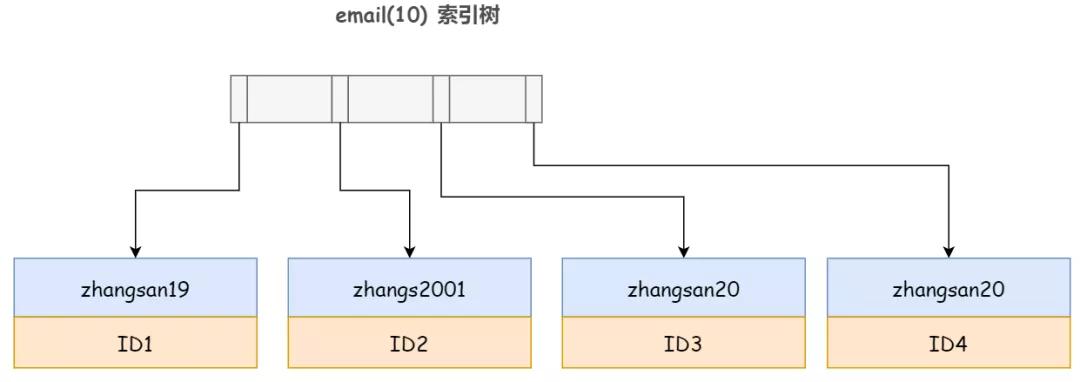
答案是并不能阻止 InnoDB 的回表,因為 InnoDB 并不能確定前綴索引的定義是否截斷了完整信息。誰知道你會不會又增加一個 'zhangs20012' 的記錄呢,對吧。
如何定義前綴索引的長度
索引選取的越長,占用的磁盤空間就越大,相同的數據頁能放下的索引值就越少,搜索的效率也就會越低。
在上面的例子中我們提到,只需要把前綴索引從 email(6) 改成 email(7),就可以大大減少記錄掃描和回表的次數,所以,在定義前綴索引的時候,我們需要在占用空間和搜索效率之間做一個權衡 trade-off。
事實上,我們在建立前綴索引時關注的是區分度,區分度越高,意味著重復的鍵值越少,所以區分度越高越好。
對于索引來說,什么是區分度呢,很簡單,就是這個索引上有多少個不同的值。建立出來的索引上擁有越多不同的值,那么這個索引的區分度就越高。
因此,我們可以通過統計索引上有多少個不同的值來判斷要使用多長的前綴。可以使用下面這個語句,計算出 email 列上有多少個不同的值,記作 email_length:
- select count(distinct email) as email_length from user;
然后,依次選取不同長度的前綴來看區分度,比如我們要看前綴索引的長度是 6~10 時候的區分度,可以用這個語句:
- select count(distinct left(email,6))as email_length_6,
- count(distinct left(email,7))as email_length_7,
- count(distinct left(email,8))as email_length_8,
- count(distinct left(email,9))as email_length_9,
- count(distinct left(email,10))as email_length_10,
- from user;
當然了,既然我們使用了前綴索引,那么就不可避免的會損失區分度,就像我們前面所說的,誰也不知道會不會又新增出一條記錄完全踩中前綴但是又不滿足判斷條件。所以我們需要預先設定一個可以接受的區分度損失比例,比如 5%。然后找出不小于 email_length * (1 - 5%) 的值,假設這里 email_length_8、email_length_9 都滿足,我們就可以選擇前綴長度為 8。
前綴索引的區分度不夠高怎么辦
我當時實習的時候就遇到過這個問題,字段(假設這個字段名是 a)超級超級長,遠大于 InnoDB 的限制 767 字節,普通索引肯定是不可能了,前綴索引就算是長度定義成 767 都還是存在區分度不高的情況,但是又存在根據這個字段進行查詢的挺頻繁的一個需求。
一個很常見的解決手段就是 Hash。
對這個超長字段 a 進行 hash(假設命名為 a_hash) 存入數據庫,然后對這個 hash 值建立索引,由于 hash 值同樣可能存在沖突,也就是說兩個不同的 a 通過 Hash 函數得到的結果可能是相同的,所以我們在查詢語句的 where 部分還需要進行一次精確判斷
- # 假設輸入的字段是 input_a
- select * from user where hash(input_a) = a_hash and input_a = a;
不過使用 Hash 這種方式有個眾所周知的缺點,那就是不支持范圍查詢了,只能等值查詢。
最后放上這道題的背誦版:
面試官:前綴索引了解嗎,為什么要建前綴索引
小牛肉:前綴索引就是選取字段的前幾個字節建立索引。首先,InnoDB 限制了每列索引的最大長度不能超過 767 字節,所以,對于某些比較長的字段,如果確實有建立索引的必要,使用前綴索引不僅能夠避免索引長度超過限制,而且相對于普通索引來說,占用的空間和查詢成本更小。
不過前綴索引可能會導致兩個問題:
第一個,使用前綴索引可能會增加記錄掃描次數與回表次數,影響性能。針對這一點呢,其實前綴索引長度的選取還是很重要的,可能前綴定義的長一點,就能夠大幅減少記錄掃描次數和回表次數,所以,在建立前綴索引的時候,我們需要在占用空間和搜索效率之間做一個權衡
第二個,使用前綴索引其實就沒法用覆蓋索引對查詢性能的優化了,因為 InnoDB 并不能確定前綴索引的定義是否截斷了完整信息,就算是完全踩中了前綴索引,InnoDB 還得回表確認一次到底是不是滿足條件了。












