滅霸來了!微軟發布BugLab:無需標注,GAN掉Bug
程序員的死對頭就是各種 bug!最近微軟在 NeurIPS 2021 上帶來了一個好消息,研究人員設計了一個類似 GAN 的網絡,通過選擇器和檢測器來互相寫和改 bug,而且還不需要標注數據!
常言道,「一杯茶,一包煙,一個 bug 改一天」。
寫代碼是軟件工程師們每天的工作,但當你辛辛苦苦寫了一大堆代碼,卻發現無法運行的時候,內心一定是崩潰的。
找 bug 不僅費時費力,最關鍵的是還經常找不著,并且有時候改了一個 bug 又會引入更多 bug,子子孫孫無窮盡也。
簡直就是找 bug 找到吐血。
隨著 AI 技術的發展,各大公司開發的代碼助手如 GitHub Copilot 等也能幫你少寫一些有 bug 的代碼。
但這還遠遠不夠!
深度學習要是能幫我把代碼里的 bug 也給修了,我上班只負責摸魚,豈不是美滋滋!
微軟在 NeurIPS 2021 上還真發了一篇這樣的論文,其中提出了一個新的深度學習模型 BugLab,并通過自監督的學習方法,可以在不借助任何標注數據的情況下檢測和修復代碼中的 bug,堪稱程序員的救世主!

修 bug 難在哪?
所謂的 bug,就是代碼的實際運行和自己的預期不符。
該運行的沒運行,該輸出a,結果卻輸出個b,這種代碼故意找茬的行為都屬于 bug。
所以想要找到并修復代碼中的 bug,不僅需要對代碼的結構進行推理,還需要理解軟件開發者在代碼注釋、變量名稱等方面留下的模糊的自然語言提示。
例如一段程序的意圖是,如果名字的長度超過了 22 個字符,那就只截取前 22 個。但原始代碼中錯誤地把大于號寫成了小于號,導致條件判斷錯誤,程序運行結果和預期不符。
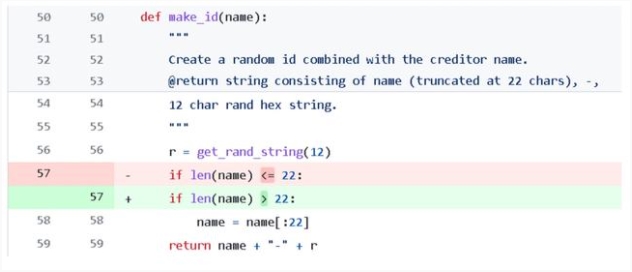
這種小錯誤在寫代碼的過程也是太常見了,稍不注意就會把條件弄反。
還有一種 bug 就是使用了錯誤的變量,例如下面的例子里面 write 和 read 弄錯了,就會導致條件判斷失敗,這種 bug 的修復只有在理解了變量名的意義后才能修復,傳統的修復手段對此是無能為力。
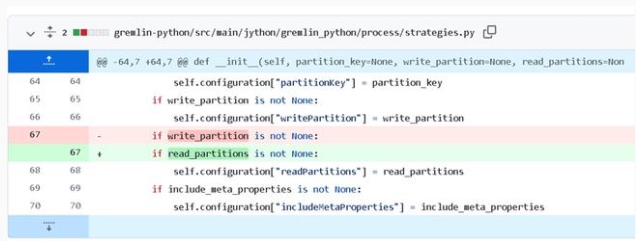
這種錯誤看起來很簡單,但往往盯著看代碼的時候卻很難發現,屬于一改改一天的那種。
并且每個程序員有自己的編程風格,比如不同的命名、縮進、判斷以及重構的方式,想讓代碼來給自己找 bug,一個字,難!
對于微軟來說,好在有 GitHub 代碼庫可以用來訓練模型。但問題來了,GitHub 上帶 bug 的代碼有那么多嗎?有 bug 誰還 commit 啊?就算能找到代碼,也沒人來標注數據啊!
微軟提出的 BugLab 使用了兩個相互競爭的模型,通過玩躲貓貓(hide and seek)游戲來學習,主要的靈感來源就是生成對抗網絡(GAN)。
由于有大量的代碼實際上都是沒有 bug 的,所以需要設計一個 bug selector 來決定是否修改正確的代碼來引入一個 bug,以及以何種方式引入 bug(例如把減號改為加號等)。當選擇器確定了 bug 的類別后,就通過編輯源代碼的方式引入 bug。
另一個用來對抗的是 bug detector,用來判斷一段代碼是否存在 bug,如果存在的話,它需要定位并修復這個 bug。
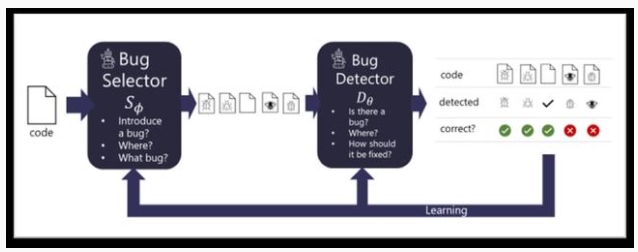
選擇器和檢測器都能夠在沒有標記數據的情況下共同訓練,也就是說整個訓練過程都是以自監督的方式進行,并成功在數百萬個代碼片段上訓練。
selector 負責寫 bug,并把它藏(hide)起來,而 detector 負責找 bug,并修復,整個過程就像躲貓貓一樣。
隨著訓練的進行,selector 寫 bug 越來越熟練,而 detector 也能夠應對更復雜的 bug。
整個過程與 GAN 的訓練大體相似,但目的卻大不相同。GAN 的目的是獲得一個更好的生成器來修改圖片,但 BugLab 的目的是找到一個更好的檢測器(GAN 中的判別器)。
并且整個訓練也可以看作是一個 teacher-student 模型,選擇器教會檢測器如何定位并修復 bug。
為開源社區修 bug!
雖然從理論上來說,使用這種 hide and seek 的方式可以訓練更復雜的 selector 來生成更多樣的 bug,從而 detector 的修 bug 能力也會更強。
但以目前的 AI 發展水平來說,還無法教會 selector 寫更難的 bug。
所以研究人員表示,我們需要集中精力關注那些更經常犯的錯誤,包括不正確的比較符,或者不正確的布爾運算符,錯誤的變量名引用等等其他一些簡單的 bug。并且為了簡單起見,實驗中只針對 python 代碼進行研究訓練。
雖然這些解釋聽起來都像是借口。
為了衡量模型的性能,研究人員從 Python 包索引中手動注釋了一個小型 bug 數據集,和其他替代方案(例如隨機插入 bug 的 selector)相比,使用 hide and seek 方法訓練的模型性能最多可以提高 30%
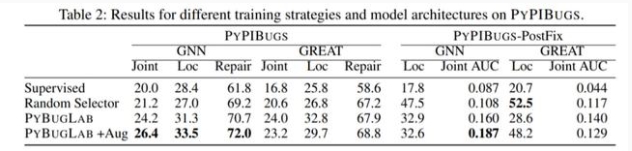
并且實驗表明大約 26% 的 bug 都可以被發現并自動修復。在檢測器發現的 bug 中,有 19 個在現實生活中的開源 GitHub 代碼中都屬于是未知的 bug。
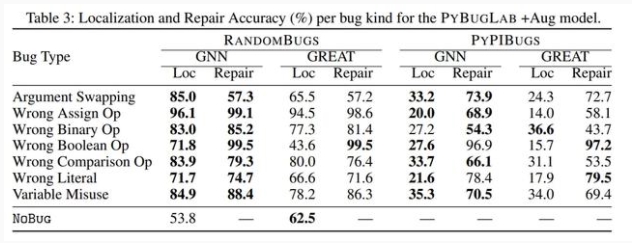
但模型也會對正確的代碼報告存在 bug,所以這個模型在離實際部署上線還有一段距離。
如果更深入地研究 selector 和 detector 模型的話,就會引出那個老生常談的問題:深度學習模型到底有沒有,又怎么樣去「理解」一段代碼的作用?
過去的研究表明,將代碼表示為一個 token 序列就能夠產生次優的(suboptimal)效果。
但如果想要利用代碼中的結構,例如語法、數據、控制流等等,就需要將代碼中的語法節點、表達式、標識符、符號等等都表示為一個圖上的節點,并用邊來表示節點間的關系。
有了圖以后就可以使用神經網絡來訓練 detector 和 selector 了。研究人員使用圖神經網絡(GNN)和 relational transformer 都進行了實驗,結果發現 GNN 總體上優于 relational transformer。
如何讓 AI 幫助人類來寫代碼和改 bug 一直都是人工智能研究中的一項基礎任務,任務過程中 AI 模型需要理解人類對程序代碼、變量名稱和注釋提供的上下文線索來理解代碼的意圖。
雖然 BugLab 離真正解放程序員改 bug 還很遙遠,但距離我們消滅 bug 總算又向前走了一步!