













只需幾個小操作,就能讓transformer模型推理速度加3.5倍
你在用 PyTorch 寫 transformer 嗎?請關(guān)注下這個項目。
大多數(shù)關(guān)于在生產(chǎn)中部署 Transformer 類模型的教程都是基于 PyTorch 和 FastAPI 構(gòu)建的。兩者都是很好的工具,但在推理方面的性能不是很好。
而如果你花費時間進(jìn)行研究,可以在 ONNX Runtime 和 Triton 推理服務(wù)器上構(gòu)建一些更好的東西。與普通 PyTorch 相比,推理速度通常會快 2 到 4 倍。
如果你想要在 GPU 上獲得一流的性能,那么只有一種可能的組合:Nvidia TensorRT 和 Triton。與普通 PyTorch 相比,最終可以獲得 5 倍的推理速度。有時它甚至能將推理速度提高 10 倍。
然而 TensorRT 并不是以簡單易用著稱的,對于 Transformer 模型更是如此,它需要使用特定的技巧。
然后,如果你花一些時間,你可以在 ONNX Runtime 和 Triton 推理服務(wù)器上構(gòu)建一些東西。與普通 Pytorch 相比,你的推理速度通常會快 2 到 4 倍。
近日,Hugging Face 發(fā)布了一款名為 Infinity 的商業(yè)產(chǎn)品,可以以非常高的性能進(jìn)行推理(與 PyTorch + FastAPI 部署相比,速度非常快)。不幸的是,根據(jù)該公司產(chǎn)品總監(jiān)的說法,即使對于部署在一臺機器上的單個模型,這也是一種付費產(chǎn)品,成本為 2 萬美元(沒有公開的具體規(guī)模信息)。
在 GitHub 上有一個項目 Transformer-deploy,它是一種基于企業(yè)級軟件的開源替代版:
- 推理服務(wù)器:Nvidia Triton(它接受查詢,傳輸給引擎,并添加對推理有用的功能,如動態(tài)批處理或多推理引擎調(diào)度)
- 推理引擎:Microsoft ONNX Runtime(用于 CPU 和 GPU 推理)和 Nvidia TensorRT(僅限 GPU)
我們似乎不費吹灰之力,就可以輕松匹敵極少數(shù) HF Infinity 公共基準(zhǔn)。
但事實上,現(xiàn)在仍然有機會進(jìn)一步加快推理性能,AFAIK 尚未被任何其他 OSS 項目利用:對所有 Transformer 模型的 GPU 量化!
如下是對 Roberta-base、seq len 256、batch 32、MNLI 數(shù)據(jù)集的測試結(jié)果:
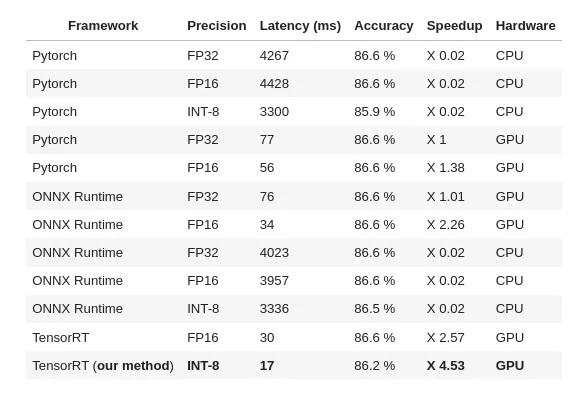
- 源代碼:https://github.com/ELS-RD/transformer-deploy/blob/main/demo/quantization/quantization_end_to_end.ipynb
- 項目 GitHub:https://github.com/ELS-RD/transformer-deploy
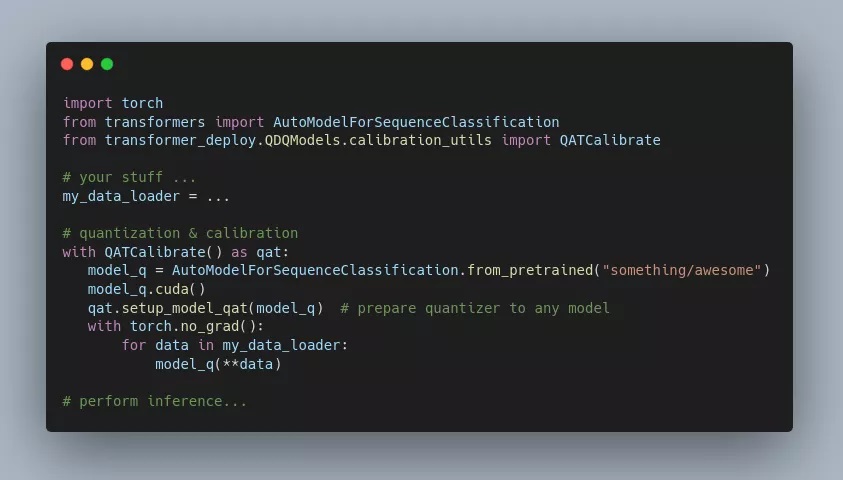
執(zhí)行 GPU 量化需要修改模型源代碼(在矩陣乘法等代價高昂的操作上添加一些稱為 QDQ 的特定節(jié)點),這既容易出錯,又很枯燥,并且是件自己給自己挖坑的事。對此,項目作者已經(jīng)為多個模型手動完成了這項工作。在作者看來,只需修補模型模塊抽象語法樹(也就是源代碼)就可以自動完成這項工作。
從用戶端看,在 GPU 上執(zhí)行模型的基本量化看起來就像這樣:
如基準(zhǔn)測試結(jié)果所示,要獲得比普通 PyTorch 快 4.5 倍的模型,在 MNLI 數(shù)據(jù)集上的準(zhǔn)確率需要犧牲 0.4 個百分點,這在許多情況下是一個合理的權(quán)衡。如果不希望損失準(zhǔn)確度,加速也可以降到 3.2 倍左右。當(dāng)然,實際應(yīng)用時的 trade-off 取決于模型、數(shù)據(jù)集等,但它給出了一個基本概念。與該項目的先前版本相比,這是一個很大的改進(jìn)。
成倍加速的背后,transformer 的源代碼被解析為 AST,像 matmul 或 LayerNorm 這樣的算子被一個量化器包裝,線性層被它們的量化版本替換,一些不支持的 TensorRT 算子被替換等等。然后還有一部分新的源代碼替換。
作者表示,他們目前已經(jīng)成功測試了 ALBERT、BERT(包括 miniLM)、DistilBERT、Roberta(包括 Camembert、XLM-R、DistilRoberta 等)、Electra 的推理。對于任何可以導(dǎo)出為 ONNX 格式的 transformer 模型,它應(yīng)該都是開箱即用的,或者只需很少的努力。
關(guān)于 CPU 的推理、量化非常容易,且也是由 Transformer-deploy 項目支持的。但是在極端情況下,transformer 的性能會變得非常差(如沒有批處理、非常短的序列和蒸餾模型時)。另外如使用基于上代英特爾 CPU 的實例,如 C6 或 M6,與像 Nvidia T4 這樣的廉價 GPU 相比,在 AWS 上的性價比會很低。
綜上所述,在 Transformer 推理上,除非你對慢速推理感到滿意并采用小實例,否則并不推薦使用 CPU 推理。
參考鏈接:https://www.reddit.com/r/MachineLearning/comments/rr17f9/p_45_times_faster_hugging_face_transformer/
【本文是51CTO專欄機構(gòu)“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】


























