MySQL的索引,你真的有好好理解過嗎?

哈嘍大家好!我是小三。今天我們來講索引。
索引是什么?
「索引的概念」:索引是一種特殊的文件(InnoDB數據表上的索引是表空間的一個組成部分),它們包含著對數據表里的所有記錄的引用指針。通俗來說就是數據庫索引就好像是一本書的目錄,能夠加快數據庫的查詢速度。
「索引的作用」:索引存在的目的就是在于提高查詢效率,使得原始的隨機全表掃描變成了快速順序鎖定數據
常用的索引分類:
1、普通索引:這是最基本的索引,沒有任何的限制
2、唯一索引:引列的值必須唯一,但允許有空值(注意和主鍵不同)
3、組合索引:多個數據列組成的索引,遵守了最左匹配原則
索引高性能保證:
1、把查詢過程中的隨機事件變成了順序事件
2、數據保存在磁盤上,而為了提高性能,每次又可以把一部分的數據讀入內存來計算,訪問磁盤的成本大概是訪問內存的十萬倍左右。
3、考慮到磁盤IO是非常高昂的操作,計算機操作系統做了一系列的優化,當進行一次IO時,不光把當前磁盤的地址的數據也把相鄰的數據也都讀取到內存的緩沖區之內。因為局部的預讀性原理告訴了我們,當計算機訪問一個地址的數據的時候,與它響鈴的數據也會很快被訪問到。每一次IO讀取的數據我們都稱之為一頁(page)。具體一頁會有多大的數據,這跟操作系統有關,一般為4k或者是8k。
那為什么磁盤讀取數據會很慢呢?
我們知道磁盤讀取時間=尋道時間+旋轉時間+傳輸時間,當需要從磁盤讀取到數據的時候,系統會將數據的邏輯地址傳給磁盤,磁盤的控制電路按照尋址邏輯將邏輯地址翻譯成了物理地址,就確定了要讀的數據 在哪一個磁道,哪個扇區。為了讀取扇區的數據,需要將磁頭放到扇區的上方,為了實現這一點,磁頭需要移動對準相應的磁道,這個過程叫尋道,在這里所耗費的時間叫做尋道時間,然后磁盤旋轉目標扇區旋轉到磁頭下,這個過程耗費的時間叫做旋轉時間。
索引的底層實現方案
我們使用索引的目的,自然是要提高查詢的效率。例如像字典,如果要查詢"mysql"這個單詞,我們首先肯定是要定位到m字母,然后從下往下找到y字母,以此類推。
索引的設計難度
查詢要求:等值查詢,還有范圍查詢(>、<、between、in)、模糊查詢(like)、并集查詢(or)
數據量:超過一千萬數據通過索引查詢,查詢性能保證
常見的檢索方案分析
順序檢索:最基本的查詢算法-復雜度O(n),數據量大的話這個算法的效率是糟糕的
二叉樹查找:O(log2n),單層節點所能存儲數據量較少,需要進行遍歷多層才能拿到數據,總結點數k與高度h的關系為k=(2^h)-1
hash索引:無法滿足范圍查找,但是它的等值檢索快,hash值==》物理地址x018,范圍檢索
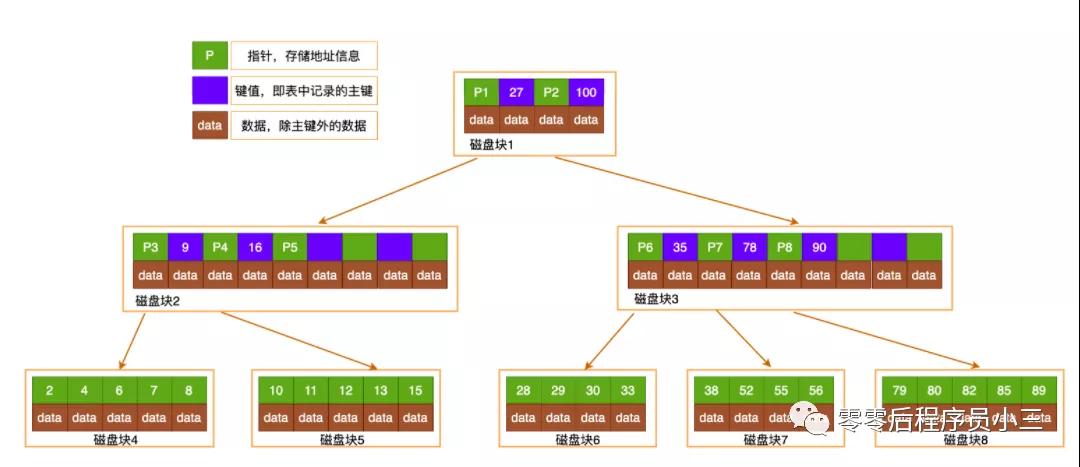
B-Tree:每個節點都是一個二元數組:[key,data],所有的節點都可以存儲數據,key為索引key,data為除之外的數據
B+Tree數據結構高性能解析
B-Tree的缺點:插入刪除新的數據記錄會破壞掉B-Tree的性質,因此在插入刪除時,需要對樹進行一個分裂、合并、轉移等操作來保持B-Tree的性質。在區間查找時可能需要返回上層節點重新,IO操作繁瑣。
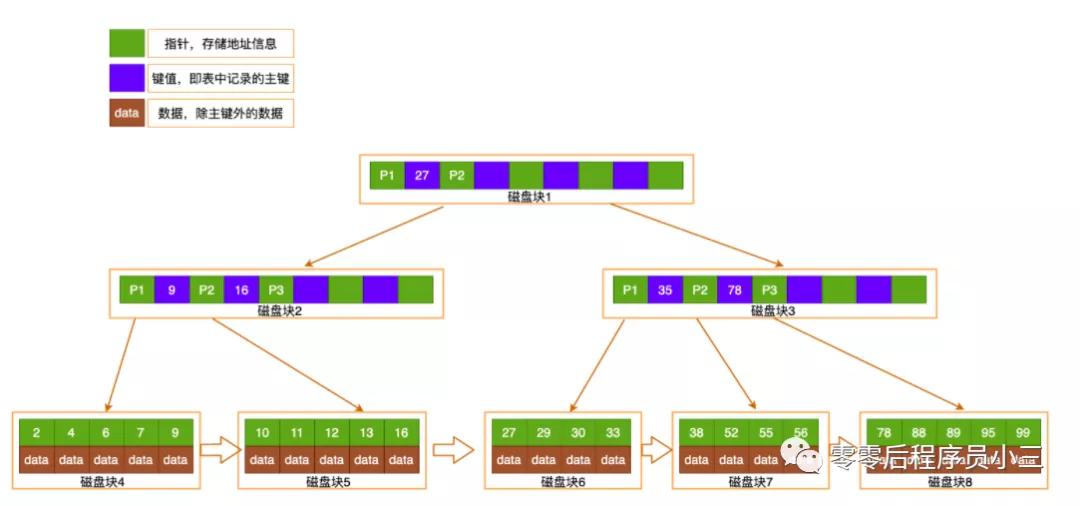
B+Tree的改進:非葉子節點不存儲data,只存儲了索引的key,只有葉子節點才存儲data
「高性能的保證」:
第一、3層的b+樹可以表示上百萬的數據,如果上百萬的數據查找只需要進行三次IO的話,那么對性能的提高無疑是巨大的,如果沒有索引的話,每個數據項都要發生一次IO那么就會有百萬次的IO,這顯然成本非常非常高。
第二、在B+Tree的每個葉子節點增加一個指向相鄰子節點的指針,這樣就形成了帶有順序訪問指針的B+Tree
第三、B+Tree只在葉子節點來存儲數據,所有的葉子節點包含一個鏈指針,其他內存的非葉子節點只存儲索引數據。只利用索引快速的定位數據索引范圍,先定位索引再通過索引高效的定位數據。
mysql為什么會選錯索引
優化器的邏輯
Mysql Server層的優化器負責的是選擇索引,而優化器選擇索引的目的就是要找到一個最優的執行方案,并且用最小代價來執行語句。在數據庫里面,掃描行數是影響執行代價的因素之一。掃描的行數越少,也就意味著訪問的磁盤的數據次數就越小,消耗的CPU就越少。掃描行數并不是唯一的判斷標準,優化器還會結合了是否使用臨時表、是否排序等等因素來綜合判斷。
掃描行數是怎么判斷的
Mysql在真正開始執行語句之前,并不可以精確的知道滿足該查詢條件的記錄究竟有多少條,只能根據統計的信息來估算記錄數。所以這個統計信息就是索引的“區分度”。顯然,一個索引上面的值不同得越多,這個索引的區分度就越好。在一個索引上不同值的個數,稱為基數。
那么,mysql是怎么樣得到索引基數的?在這里mysql采樣統計方法,但是為什么要使用采樣統計這種方法呢?原因就是因為如果把整張表取出來然后進行一行行的統計,雖然這樣能夠得到精確的數據,但是代價也太高了,所以的話只能使用采樣統計。
- #創建表
- CREATE TABLE `test` (
- `id` int(11) NOT NULL,
- `a` int(11) NOT NULL default 0,
- `b` int(11) NOT NULL default 0,
- PRIMARY KEY (`id`),
- KEY `a` (`a`),
- KEY `b` (`b`)
- ) ENGINE=InnoDB;
- #添加數據
- delimiter ;;
- create procedure xddata()
- begin
- declare i int;
- set i=1;
- while(i<=100000)do
- insert into test values(i, i, i);
- set i=i+1;
- end while;
- end;;
- delimiter ;
- call xddata();
- 數據查詢
- explain select * from test where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1;
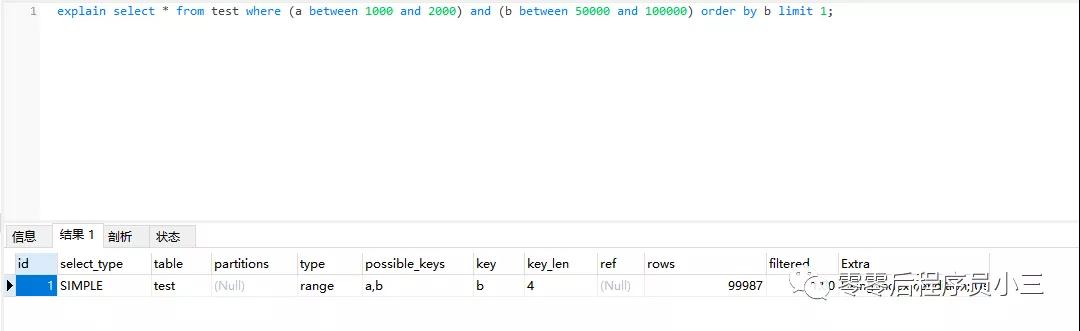
「為什么會出現這種結果呢?」
在多個的索引情況下,優化器一般會通過比較了掃描行數、是否需要臨時表以及是否需要排序等因素來作為索引的半段依據。
選擇了索引b,則就需要在b索引上掃描9W條記錄,然后回到主鍵索引上過濾掉不滿足a條件的記錄,因為索引有序,所以使用b索引不需要額外排序。
「解決方案」
使用force index a讓mysql直接選擇a索引來處理此處的查詢
- select * from test where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1;
- select * from test force index(a) where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1;
在其他的場景:
數據表有頻繁的刪除或者是更新操作導致的數據空洞造成的,造成的原因可能是分析器explain的結果預估的rows值跟實際的情況差距比較大,分析器分析掃描行數用的是抽樣調查。統計分析不對話可以使用analyze table test命令,用來重新統計索引信息。
【面試題】唯一索引和普通索引的區別在哪?
「1.查詢上的區別」
對唯一索引,由于索引定義了唯一性,查到第一個滿足條件的記錄之后,就會停止檢索。
對普通索引,查找到滿足條件的第一個記錄'ab'后,需要找下個記錄,直到碰到第一個不滿足k='ab'條件的記錄
「2.修改上的區別」
對于唯一索引,所有更新操作要先判斷該操作是否會違反唯一性約束,唯一索引不會用change buff,若所修改的數據在內存當中,找到索引所對應的存儲位置、判斷到沒有沖突,然后再插入值,語句執行結束。若所修改的數據不在內存當中,則需要將數據頁也讀入內存,判斷到沒有沖突,再插入值,語句執行結束。
「3.性能上的區別」
普通索引查找數據的時候會將符合條件的都給查找出來
唯一索引主要是第一條符合條件的就會立即返回,不會在繼續查找了,因為唯一的為數已經確保了只有一條符合條件