谷歌等揭露「AI任務疑難」:存在局限的ImageNet等基準,就像無法代表「整個世界」的博物館

本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
在日常生活中,我們需要一些「標準」來衡量個人的行為。
而在科研工作中,研究人員也需要一些「基準」來評估模型的性能。
因此,不管是普遍的「標準」還是特定的「基準」,它們都有一定的參考意義。
然而,如果有一天我們發現這些「參照物」與實際生活漸行漸遠時,它們該往何處去?
近日,由加州大學伯克利分校、華盛頓大學和谷歌研究院合著的論文《AI and the Everything in the Whole Wide World Benchmark》指出ImageNet等基準定義的模糊任務在促進智能理解上的局限性,就像用有限的博物館來代表整個世界一樣。

論文地址:https://openreview.net/pdf?id=j6NxpQbREA1
在這篇論文中,研究人員闡述了機器學習(ML)對通用任務框架(CTF)的過度依賴,因為這個框架不恰當地演變成我們今天所理解的這些聲稱評估「通用能力」的基準。值得注意的是,研究團隊并不否認這些基準的實用性,而是希望指出將其作為框架存在的固有缺陷。
1. 展示「整個世界」的博物館 VS ImageNet
這篇論文最能引起共鳴的一點就是用故事書作為引子,且將情節貫穿全文,使得論文的研究內容更為直白易懂。
這本書就是1974年出版的《Grover and the Everything In the Whole Wide World Museum》,書中的主人公Grover參觀了一家聲稱展示「整個世界」的博物館。
該博物館的每個展廳都陳列著不同類別的東西,有些類別是隨意和主觀的,比如「你在墻上看到的東西( Things You Find On a Wall )」和「房間里能讓你撓癢癢的東西( The Things that Can Tickle You Room )」;有些類別則非常具體的,例如「胡蘿卜屋( The Carrot Room )」,而另一些則含糊不清,如「高大的廳堂( The Tall Hall )」。

當Grover認為自己已經參觀完博物館的一切時,他來到寫著「其他東西(Everything Else)」的大門前。打開門后,卻發現自己置身于外面的世界。
作為兒童故事,Grover的經歷是荒誕的。然而,在實際的研究中,例如人工智能尤其是ML領域,也存在類似的固有錯誤邏輯,其中許多流行的基準依賴于固有的錯誤假設。
這篇論文的研究人員認為,在諸如「視覺理解」或「語言理解」之類的模糊任務中,作為衡量一般能力進展的基準,與有限的博物館在代表「整個世界的一切」方面一樣無效,且這兩個謬論的原因是相似的,即本質上是基于特定的、有限的且局限于上下文的環境。
GLUE或ImageNet之類的基準測試常常被提議為驗證任何給定模型性能的基本通用任務的定義。其結果是,通過這些基準數據集證明合理的結論往往遠遠超越了它們最初設計的任務,甚至超出了最初的開發目標。
盡管作為邁向「通用目標」的標志,這些基準存在明顯的局限性。事實上,這些基準的開發、使用和采用表明了一個結構有效性的問題,其中涉及的基準——由于它們在特定數據、度量和實踐中的實例化——不可能捕獲任何具有代表性的關于它們的普遍適用性的結論。
論文的作者們認為測量通用能力的目標(即通用對象識別、通用語言理解或領域獨立推理等目標)不能充分體現在數據定義的基準中。研究人員注意到,當前的趨勢不恰當地擴展了CTF范式,以將其應用于與現實世界目標或背景不同的抽象表現任務。
從歷史上看,CTF的開發正是為了引入實用導向和嚴格范圍的人工智能任務,即自動語音識別(ASR)或機器翻譯(MT),其中所需的驗證是基準是否準確地反映了計算機在現實環境中所要求的實際任務。這一波定義不明確的「通用」目標則完全顛覆了其引入的意圖。
與其把Grover的經歷當成兒童故事來看,倒不如說這是一則深刻的寓言故事。當Grover打開「其他東西」的大門時,卻發現自己置身于博物館外的大千世界。故事的結尾或許已經預示了這個研究的結論,ImageNet之類的基準定義必然不能代表適應所有現實世界模糊任務的「通用目標」。

因此,這篇論文確實有許多值得討論和深思的地方。ImageNet存在不足,那其他基準定義就是完美無缺的嗎?除了ImageNet,目前在通用對象識別上還有更好的參照基準嗎?該如何看待以及解決基準定義越來越「不基準」這個問題?
外行看熱鬧,內行看門道,這么頭疼的問題就應該交給專業人士。
迎面向我們走來的是第一位評委,該評委發出了“反對CV和NLP的“通用”基準中令人信服的觀點!(A compelling argument against "general" monolithic benchmarks in vision and NLP)”的贊嘆,因為他覺得這篇論文史料詳實,觀點明確,分析到位,著實令人信服。

論文的研究人員先在文中鋪墊了大量的背景知識,向讀者展現了通用人工智能和基準測試的相關研究,并分析了ML的基準測試何時開始作為評估范圍狹窄的任務性能的標準化方法。最后,結論就水到渠成了:通用語言理解和通用對象識別的基準本質上是有缺陷的,因為它們應用于狹窄的范圍。

最后,這位評委真誠地希望計算機視覺和NLP社區能認真對待這篇論文,因為他認為該論文對在這兩個領域取得更有意義的進展做出了寶貴的貢獻,而不僅僅是追求最先進的技術。
但美中不足的是,既然發現了ImageNet基準存在局限性,那有什么辦法可以減少對這些通用標準的過度依賴?看來論文的研究人員也還沒找到這個問題的答案。

而第二位評委對這篇論文的評價是:通用人工智能基準的謬論(The Fallacy of Benchmarks for General Artificial Intelligence )。因為這篇論文的受眾主要是AI領域的研究人員,所以作者在前文回顧了通用AI的相關基準,一下拉近了與讀者的距離。此外,引用Grover的故事也使得該論文有趣易懂。
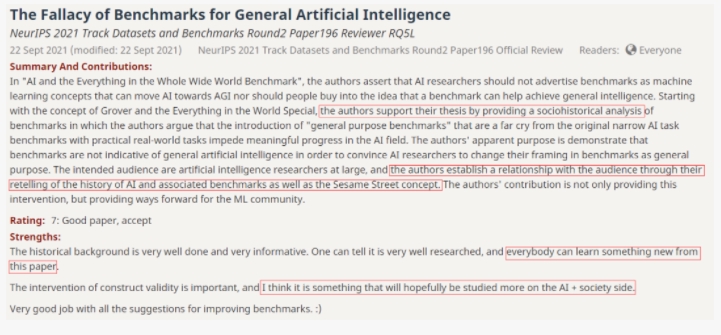
即使這篇論文的開頭存在表述問題,未能無縫銜接主題,但瑕不掩瑜,評委二號高度贊揚了這篇論文為ML領域的研究指明了方向。

接著,評委三號也帶著他的觀點款款走來:好論文!但改一下結構就更好了(Well argued paper, with some reorganization suggested)。這位評委指出,這篇論文最大的亮點是觀點獨特且論據充足。但也發出了和第一位評委相同的疑惑:所以,有什么解決方案可以減少對通用標準的過度依賴?

不同于前三位評委的「慷慨」,第四位評委只給出了5分的評價,認為這篇論文只是:當前基準測試的簡史(History of the benchmarks we use today)。從這個評語不難看出,這位評委覺得這篇論文列舉了很多基準測試且強調了它們的局限性,但作者團隊并沒有采取任何立場。

最后,評委五號不見其人,先聞其聲:很棒!但還有上升空間(Great, but improvements needed)。第五位評委認為這篇論文在梳理和總結相關工作的方面做得非常好,同時有大量的研究支撐文中的論點,希望這篇論文能引起相關領域研究人員的重視。

正因為對這篇論文寄予了極高的期望,因此評委只給出了6分的評價,同時羅列了非常詳細的修改建議,希望論文的作者能加以改進。
看完五大評審的官方評論,總結起來基本就是:論文不錯,觀點新穎,論據充分,要是能提出解決方案就更好了。此外,有三位評委都不約而同地希望這篇論文能引起相關領域的重視。
Reddit上關于這篇文章的討論熱度也不小,我們來看看神通廣大的網友怎么說。

某位網友一針見血地指出,雖然ImageNet等基準測試像「有限的博物館」一樣存在不足,但卻是目前我們訓練模型最有力的工具。

確實,就像上述評委提到的,ImageNet是有局限性,但是否有更好的解決方案?因此,有熱心網友為論文的作者修改了摘要:沒有任何數據集能夠捕捉所有細節的全部復雜性,就像沒有博物館可以包含整個世界中所有的事物一樣。

一些網友則認為論文不錯,尤其是「芝麻街」故事情節的插入加深了他們對該論文的理解。

這些網友覺得,用「無法展示一切的博物館」類比「ImageNet在一些模糊任務上的局限性」非常恰當。

大概論文的作者們也沒想到,寫個文章還能為一本書代言,有網友調侃:宇宙萬物的答案就隱藏在這本「芝麻街」故事書中。

更多網友表示贊同論文作者的觀點,畢竟相比解決問題,發現問題太容易了。(狗頭)

所以,解決方案究竟在哪?

就算博物館「無法展示一切」,也沒有人能否定其價值。同理,ImageNet這類基準定義的存在意義也不容置喙。不斷發現問題并解決問題,歷史的車輪才會滾滾向前(狗頭)。