我被騙好久了!Count(*) 性能最差?

大家好,我是小林。
當我們對一張數據表中的記錄進行統計的時候,習慣都會使用 count 函數來統計,但是 count 函數傳入的參數有很多種,比如 count(1)、count(*)、count(字段) 等。
到底哪種效率是最好的呢?是不是 count(*) 效率最差?
我曾經以為 count(*) 是效率最差的,因為認知上 selete * from t 會讀取所有表中的字段,所以凡事帶有 * 字符的就覺得會讀取表中所有的字段,當時網上有很多博客也這么說。
但是,當我深入 count 函數的原理后,被啪啪啪的打臉了!
不多說, 發車!
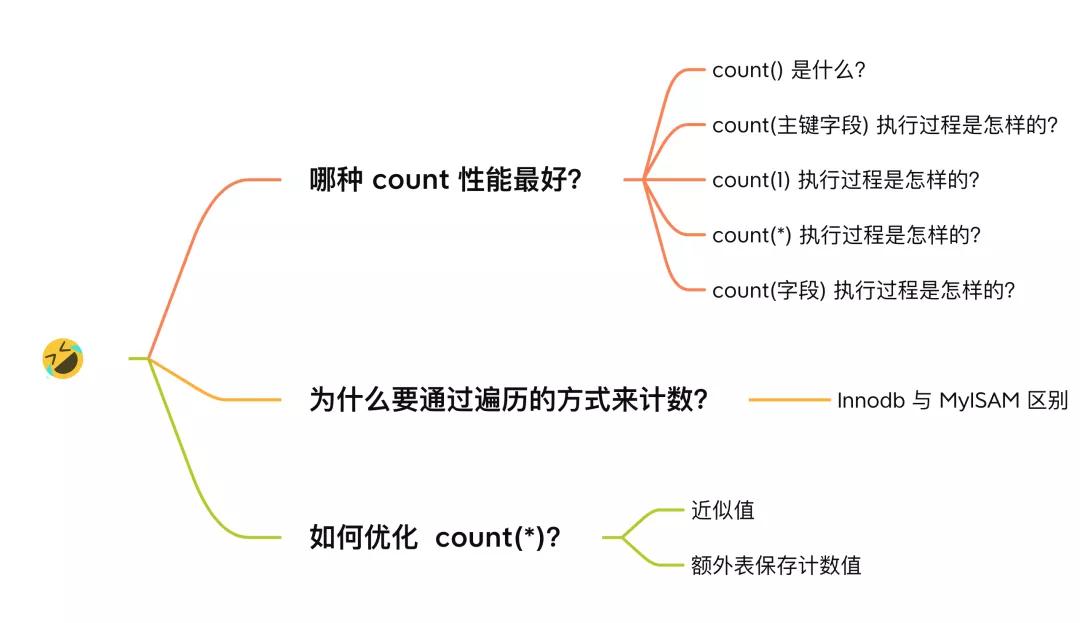
哪種 count 性能最好?
哪種 count 性能最好?
我先直接說結論:

要弄明白這個,我們得要深入 count 的原理,以下內容基于常用的 innodb 存儲引擎來說明。
count() 是什么?
count() 是一個聚合函數,函數的參數不僅可以是字段名,也可以是其他任意表達式,該函數作用是統計符合查詢條件的記錄中,函數指定的參數不為 NULL 的記錄有多少個。
假設 count() 函數的參數是字段名,如下:
- select count(name) from t_order;
這條語句是統計「 t_order 表中,name 字段不為 NULL 的記錄」有多少個。也就是說,如果某一條記錄中的 name 字段的值為 NULL,則就不會被統計進去。
再來假設 count() 函數的參數是數字 1 這個表達式,如下:
- select count(1) from t_order;
這條語句是統計「 t_order 表中,1 這個表達式不為 NULL 的記錄」有多少個。
1 這個表達式就是單純數字,它永遠都不是 NULL,所以上面這條語句,其實是在統計 t_order 表中有多少個記錄。
count(主鍵字段) 執行過程是怎樣的?
在通過 count 函數統計有多少個記錄時,MySQL 的 server 層會維護一個名叫 count 的變量。
server 層會循環向 InnoDB 讀取一條記錄,如果 count 函數指定的參數不為 NULL,那么就會將變量 count 加 1,直到符合查詢的全部記錄被讀完,就退出循環。最后將 count 變量的值發送給客戶端。
InnoDB 是通過 B+ 樹來保持記錄的,根據索引的類型又分為聚簇索引和二級索引,它們區別在于,聚簇索引的葉子節點存放的是實際數據,而二級索引的葉子節點存放的是主鍵值,而不是實際數據。
用下面這條語句作為例子:
- //id 為主鍵值
- select count(id) from t_order;
如果表里只有主鍵索引,沒有二級索引時,那么,InnoDB 循環遍歷聚簇索引,將讀取到的記錄返回給 server 層,然后讀取記錄中的 id 值,就會 id 值判斷是否為 NULL,如果不為 NULL,就將 count 變量加 1。
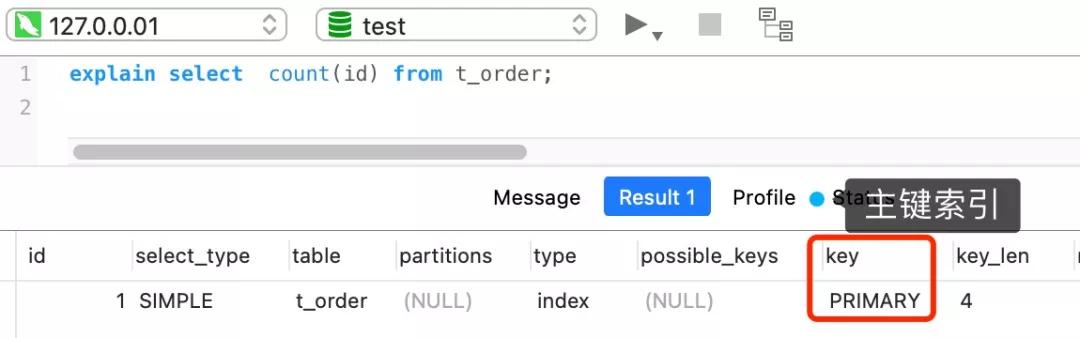
但是,如果表里有二級索引時,InnoDB 循環遍歷的對象就不是聚簇索引,而是二級索引。
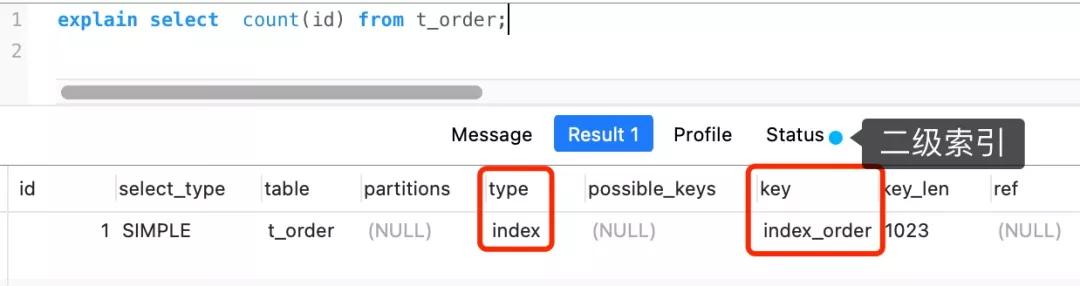
這是因為相同數量的二級索引記錄可以比聚簇索引記錄占用更少的存儲空間,所以二級索引樹比聚簇索引樹小,這樣遍歷二級索引的 I/O 成本比遍歷聚簇索引的 I/O 成本小,因此「優化器」優先選擇的是二級索引。
count(1) 執行過程是怎樣的?
用下面這條語句作為例子:
- select count(1) from t_order;
如果表里只有主鍵索引,沒有二級索引時。
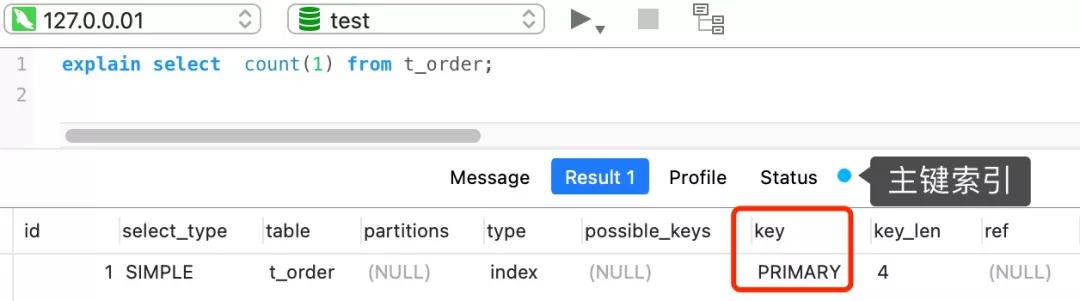
那么,InnoDB 循環遍歷聚簇索引(主鍵索引),將讀取到的記錄返回給 server 層,但是不會讀取記錄中的任何字段的值,因為 count 函數的參數是 1,不是字段,所以不需要讀取記錄中的字段值。參數 1 很明顯并不是 NULL,因此 server 層每從 InnoDB 讀取到一條記錄,就將 count 變量加 1。
可以看到,count(1) 相比 count(主鍵字段) 少一個步驟,就是不需要讀取記錄中的字段值,所以通常會說 count(1) 執行效率會比 count(主鍵字段) 高一點。
但是,如果表里有二級索引時,InnoDB 循環遍歷的對象就二級索引了。
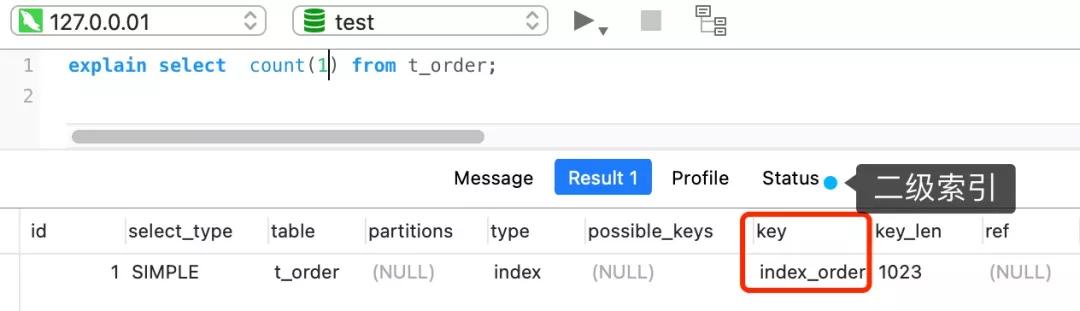
count(*) 執行過程是怎樣的?
看到 * 這個字符的時候,是不是大家覺得是讀取記錄中的所有字段值?
對于 selete * 這條語句來說是這個意思,但是在 count(*) 中并不是這個意思。
count(*) 其實等于 count(0),也就是說,當你使用 count(*) 時,MySQL 會將 * 參數轉化為參數 0 來處理。
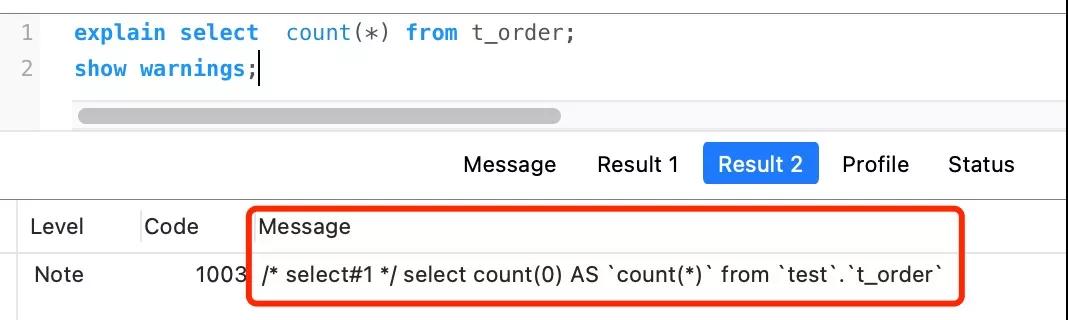
所以,count(*) 執行過程跟 count(1) 執行過程基本一樣的,性能沒有什么差異。
在 MySQL 5.7 的官方手冊中有這么一句話:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
翻譯:InnoDB以相同的方式處理SELECT COUNT(*)和SELECT COUNT(1)操作,沒有性能差異。
而且 MySQL 會對 count(*) 和 count(1) 有個優化,如果有多個二級索引的時候,優化器會使用key_len 最小的二級索引進行掃描。
只有當沒有二級索引的時候,才會采用主鍵索引來進行統計。
count(字段) 執行過程是怎樣的?
count(字段) 的執行效率相比前面的 count(1)、 count(*)、 count(主鍵字段) 執行效率是最差的。
用下面這條語句作為例子:
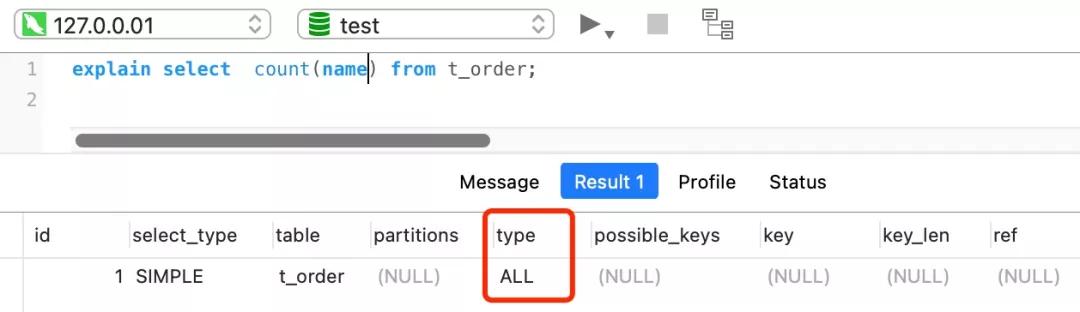
- //name不是索引,普通字段
- select count(name) from t_order;
對于這個查詢來說,會采用全表掃描的方式來計數,所以它的執行效率是比較差的。
小結
count(1)、 count(*)、 count(主鍵字段)在執行的時候,如果表里存在二級索引,優化器就會選擇二級索引進行掃描。
所以,如果要執行 count(1)、 count(*)、 count(主鍵字段) 時,盡量在數據表上建立二級索引,這樣優化器會自動采用 key_len 最小的二級索引進行掃描,相比于掃描主鍵索引效率會高一些。
再來,就是不要使用 count(字段) 來統計記錄個數,因為它的效率是最差的,會采用全表掃描的方式來統計。如果你非要統計表中該字段不為 NULL 的記錄個數,建議給這個字段建立一個二級索引。
為什么要通過遍歷的方式來計數?
你可以會好奇,為什么 count 函數需要通過遍歷的方式來統計記錄個數?
我前面將的案例都是基于 Innodb 存儲引擎來說明的,但是在 MyISAM 存儲引擎里,執行 count 函數的方式是不一樣的,通常在沒有任何查詢條件下的 count(*),MyISAM 的查詢速度要明顯快于 InnoDB。
使用 MyISAM 引擎時,執行 count 函數只需要 O(1 )復雜度,這是因為每張 MyISAM 的數據表都有一個 meta 信息有存儲了row_count值,由表級鎖保證一致性,所以直接讀取 row_count 值就是 count 函數的執行結果。
而 InnoDB 存儲引擎是支持事務的,同一個時刻的多個查詢,由于多版本并發控制(MVCC)的原因,InnoDB 表“應該返回多少行”也是不確定的,所以無法像 MyISAM一樣,只維護一個 row_count 變量。
舉個例子,假設表 t_order 有 100 條記錄,現在有兩個會話并行以下語句:

在會話 A 和會話 B的最后一個時刻,同時查表 t_order 的記錄總個數,可以發現,顯示的結果是不一樣的。所以,在使用 InnoDB 存儲引擎時,就需要掃描表來統計具體的記錄。
而當帶上 where 條件語句之后,MyISAM 跟 InnoDB 就沒有區別了,它們都需要掃描表來進行記錄個數的統計。
如何優化 count(*)?
如果對一張大表經常用 count(*) 來做統計,其實是很不好的。
比如下面我這個案例,表 t_order 共有 1200+ 萬條記錄,我也創建了二級索引,但是執行一次 select count(*) from t_order 要花費差不多 5 秒!
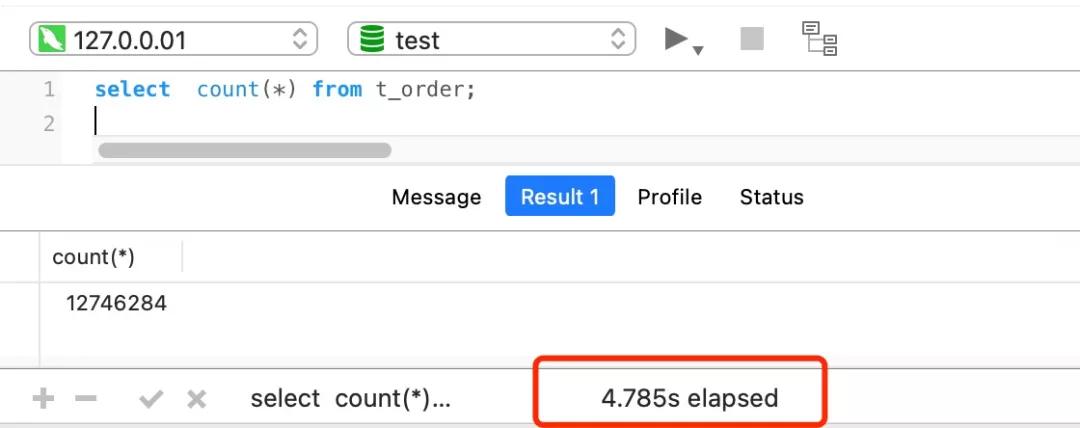
面對大表的記錄統計,我們有沒有什么其他更好的辦法呢?
第一種,近似值
如果你的業務對于統計個數不需要很精確,比如搜索引擎在搜索關鍵詞的時候,給出的搜索結果條數是一個大概值。
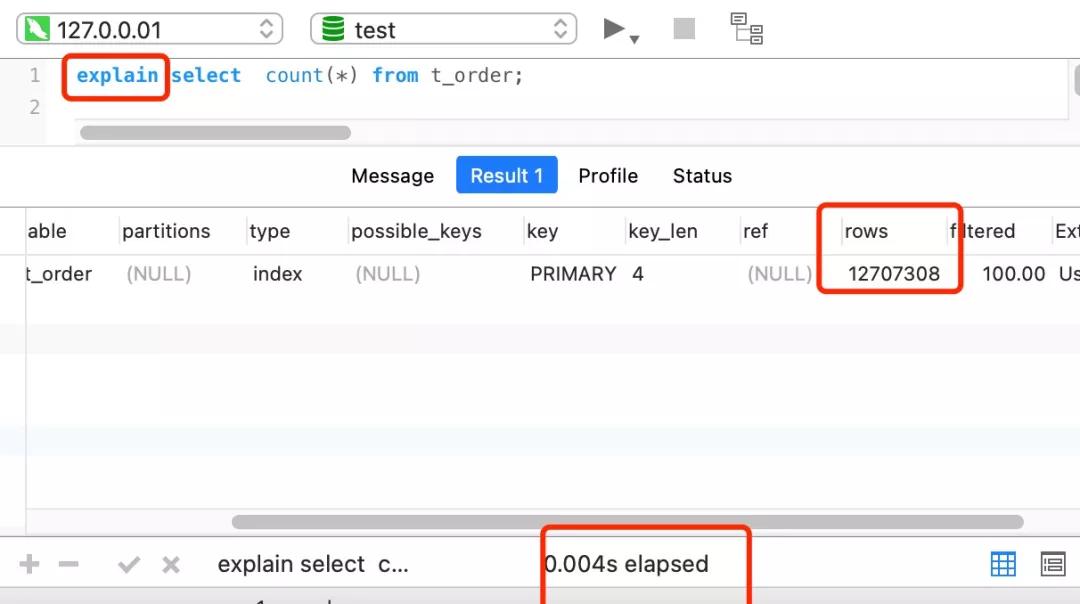
這時,我們就可以使用 show table status 或者 explain 命令來表進行估算。
執行 explain 命令效率是很高的,因為它并不會真正的去查詢,下圖中的 rows 字段值就是 explain 命令對表 t_order 記錄的估算值。
第二種,額外表保存計數值
如果是想精確的獲取表的記錄總數,我們可以將這個計數值保存到單獨的一張計數表中。
當我們在數據表插入一條記錄的同時,將計數表中的計數字段 + 1。也就是說,在新增和刪除操作時,我們需要額外維護這個計數表。