前端性能優化之從URL輸入到頁面加載過程分析

本文轉載自微信公眾號「前端萬有引力」,作者一川 。轉載本文請聯系前端萬有引力公眾號。
1寫在前面
在頁面加載到最終渲染顯示大致是這樣的:用戶在瀏覽器輸入URL回車后,瀏覽器為了將URL解析成IP地址,會向DNS服務器發起DNS查詢,獲取IP地址。在建立連接后,瀏覽器就可以發起HTTP請求,而服務器接受請求后進行響應,瀏覽器從響應結果中拿到數據,并進行解析和渲染,最后在用戶面前就出現了一個網頁。簡而言之就是三個階段:
- 客戶端發起請求階段
- 服務端數據處理請求階段
- 客戶端頁面渲染階段
2客戶端請求階段的優化點
客戶端發起請求階段是指用戶在瀏覽器輸入URL,經過本地緩存確認是否已經存在這個網站。如果沒有,接著會由DNS查詢從域名服務器獲取這個IP地址,接下來就是客戶端通過TCP三次握手和TLS協商向服務器發起HTTP請求建立連接的過程。
本地緩存
本地緩存可以讓靜態資源加載更快,當客戶端發起一個請求時,靜態資源可以直接從客戶端獲取,不需要再想服務器請求。
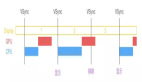
但是在實際開發中,很多前端程序員會忽略本地緩存的優化,這就會導致:在客戶端請求階段,假設一個項目的列表頁DNS產生時間是835ms,TCP三次握手和TLS協商是436ms,數據返回是412ms,這樣在強網條件下一個請求的響應時間大概是1233ms。如果在弱網條件,一個請求連接的時間都需要2s,但是使用緩存處理的話,幾乎可以說是幾ms內完成請求。
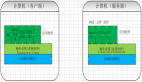
強緩存:指的是瀏覽器在加載資源時,根據請求頭的expires和cache-control判斷是否命中客戶端緩存。
協商緩存:指的是瀏覽器會先發送一個請求到服務器,通過last-modified和etag驗證資源是否命中客戶端緩存。
DNS查詢
DNS之所以能夠成為前端性能的優化點,這是因為每進行一次DNS查詢,都要經歷從客戶端到信號接收站,再到認證DNS服務器的過程。
但是這樣每次查詢都要走這個流程就會耗費很多的時間,優化方法就是讓DNS查詢先緩存,而瀏覽器提供了DNS預獲取的接口,我們可以在打開瀏覽器或者Webview的同時就進行配置。
HTTP請求
對于HTTP請求而言最大的優化點在于請求阻塞,就是瀏覽器為了保證訪問速度,會默認對同一域下的資源保持一定的連接數,請求過多會進行阻塞。對此我們提前做好域名規劃是很重要的,可以先看看當前頁面需要用到哪些域名,最關鍵的是首屏中需要用到哪些域名。
域名散列:就是通過不同的域名,增加請求并行連接數。將靜態服務器地址pic.yichuan.com,做成支持pic0-5的6個域名,每次請求時隨機選取一個域名地址進行請求,因為有6個域名同時可用,最多可以進行并行36個連接。
一次完整的HTTP請求需要經歷DNS查找,建立TCP握手,瀏覽器發起HTTP請求,服務器接受請求并處理返回響應結果,瀏覽器再接收響應等過程。但是每一次HTTP請求都需要加載很多文件,建立連接并耗費很多時間。如果有很多文件就需要發起很多次請求,而如果把若干個小文件合并成一個大文件就可以減少HTTP請求,減少訪問的時間、提升效率和速度。
3服務端數據處理階段的優化點
服務端數據處理階段指的是WevServer接受到請求后,從數據存儲層取到數據,再返回給前端的過程。服務端程序接受到HTTP請求后,會做一些請求參數處理以及權限校驗。此過程的優化點:在于是否做了數據緩存處理、是否做了gzip壓縮以及是否具有重定向。gzip壓縮是一種壓縮技術,通過gzip壓縮資源的下載速度會快很多,能夠大大提升頁面的展示速度。
數據緩存
在進行數據緩存的幾種方法:
- 借助Service Worker的數據接口緩存
- 借助本地存儲的接口緩存
- CDN
Service Worker:是瀏覽器的一個高級屬性,本質上是一個請求代理層,它存在的目的就是攔截和處理網絡數據請求。
借助本地存儲的接口緩存:指的是在一些對數據時效性要求不高的頁面,第一次請求到數據后,程序將數據存儲到本地存儲。下一次請求的時候,先去緩存里面取出數據,如果沒有的話再想服務器發起請求。
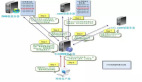
CDN:基本思路是通過在網絡各處放置節點服務器,構造一個智能虛擬網絡,將用戶的請求導向離用戶最近的服務節點上。
為什么數據緩存會成為性能的優化點呢?這是因為每次請求數據接口,需要從客戶端到后端服務器再到更后端的數據存儲層,一層一層返回數據,最后再返回客戶端,這樣請求響應的耗時很長。
重定向
重定向是指網站資源遷移到其他位置后,用戶訪問站點時,程序會自助將用戶請求從一個頁面轉移到另外一個頁面的過程。重定向的三種方式:
- 服務端發揮的302重定向
- META標簽實現的重定向
- 前端Javascript通過window.location實現的重定向
它們都會引發新的DNS查詢,會導致新的TCP三次握手和TLS協商以及產生新的HTTP請求,而這些都會導致請求過程中更多地時間,進而影響前端性能。
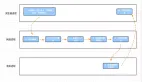
當前服務端對數據加工聚合處理后,客戶端拿到數據,接下來會進入解析和渲染階段。解析階段就是HTML解析器將頁面內容轉換成DOM樹和CSSDOM樹的過程。所謂DOM樹,就是文檔對象模型(Document Object Model),它描述了標簽之間的層次和結構。CSSDOM樹,即CSS對象模型,主要描述了樣式集的層次和結構。
CSS解析器遍歷其中每個規則,將CSS規則解析瀏覽器可解析和處理的樣式集合,最終結合瀏覽器里面的默認樣式,匯總形成具有父子關系的CSSDOM樹。
4頁面解析和渲染階段的優化點
主線程會計算DOM節點的最終樣式,生成布局樹,布局樹會記錄參與頁面布局的節點和樣式。
DOM樹解析中的優化點
解析和渲染階段的流程環節比較多,邏輯復雜,優化點也比較多,比如:DOM樹構建過程,CSSDOM樹生成階段,重排和重繪過程等。
- 當HTML標簽不滿足web語義化時,瀏覽器就需要更多時間去解析DOM標簽的含義。
- DOM節點的數量越多,構建DOM樹的時間就越長,進而延長解析時間,拖延頁面展示速度。
- 文檔中包含<script>標簽時,無論是DOM或者是CSSDOM都可以被Javscript所訪問和修改,所以一旦在頁面解析時遇到<script>標簽,DOM的構造過程就會暫停。因此外部<script>標簽常被稱為”解析“階段的攔路虎,有時就因為解析過程中多了一個<script>標簽造成頁面解析階段從200ms到1s。對此,外部腳本的加載時機一定要明確好,能夠延遲加載就選用延遲加載,通過使用defer和async告知瀏覽器在等待腳本下載期間不阻止解析過程。
CSS執行會阻塞渲染,阻止JS執行,而JS加載和執行會阻塞HTML解析,阻止CSSDOM構建。如果這些CSS、JS標簽放在<head>標簽中,并且需要加載和解析很久的話,那么頁面就出顯現白屏情況。因此,JS文件要放在底部(不會阻止DOM解析,但是會阻塞渲染),等HTML解析后再加載JS文件,盡早向用戶呈現頁面的內容。
之所以要講CSS文件放在頭部,這是因為加載HTML后再加載CSS,會讓用戶第一時間看到沒有樣式的頁面,為了避免出現這種情況需要將CSS文件放在頭部。當然JS文件也可以放在頭部,但是需要在<script>標簽加上defer屬性就可以了,異步進行下載、延遲執行。
布局中的優化點
瀏覽器會根據樣式解析器給出的樣式規則,來計算某個元素需要占據的空間大小和屏幕中的位置,借助計算結果來進行布局。而主線程布局是采用的流布局,就是從上到下、從左到右進行遍歷進行布局。
假設我們在頁面渲染過程運行時修改了一個元素的屬性,這時布局階段受到了影響,瀏覽器必須檢查所有其他區域的元素,然后自動重排頁面,相當于進行了一遍整個渲染流程。
此外,因為瀏覽器每次布局計算都要作用于真個DOM,如果元素量大,計算出所有的元素位置和尺寸會花費很長的時間,所以布局階段很容易成為性能瓶頸點,需要我們進行優化。
比如說:當你做列表頁性能優化時,開始布局時并沒有確定列表頁圖片的初始尺寸,只設定了一個基礎的占位尺寸。那么當圖片加載完畢后,主線程才知道圖片的大小,不得不重新進行布局計算,然后再次進行頁面渲染。
5參考文章
《前端性能優化方法與實踐》
6寫在最后
頁面加載全過程很復雜,內容也比較多,能夠進行優化點也是眾多,而本篇文章只是簡單介紹了前端領域的可優化點。對于偏硬件領域能夠做的優化點有GPU繪圖、操作系統GUI和LCD顯示等;對于計算機網絡中的網絡層和服務層,比如擁塞預防、負載均衡和慢啟動;還有一些頁面的解析和渲染算法,比如解析算法、標記算法和樹構建算法等。