













阿里 BladeDISC 深度學(xué)習(xí)編譯器正式開源
一 導(dǎo)讀
隨著深度學(xué)習(xí)的不斷發(fā)展,AI模型結(jié)構(gòu)在快速演化,底層計(jì)算硬件技術(shù)更是層出不窮,對于廣大開發(fā)者來說不僅要考慮如何在復(fù)雜多變的場景下有效的將算力發(fā)揮出來,還要應(yīng)對計(jì)算框架的持續(xù)迭代。深度編譯器就成了應(yīng)對以上問題廣受關(guān)注的技術(shù)方向,讓用戶僅需專注于上層模型開發(fā),降低手工優(yōu)化性能的人力開發(fā)成本,進(jìn)一步壓榨硬件性能空間。阿里云機(jī)器學(xué)習(xí)PAI開源了業(yè)內(nèi)較早投入實(shí)際業(yè)務(wù)應(yīng)用的動態(tài)shape深度學(xué)習(xí)編譯器 BladeDISC,本文將詳解 BladeDISC的設(shè)計(jì)原理和應(yīng)用。
二 BladeDISC是什么
BladeDISC是阿里最新開源的基于MLIR的動態(tài)shape深度學(xué)習(xí)編譯器。
1 主要特性
- 多款前端框架支持:TensorFlow,PyTorch
- 多后端硬件支持:CUDA,ROCM,x86
- 完備支持動態(tài)shape語義編譯
- 支持推理及訓(xùn)練
- 輕量化API,對用戶通用透明
- 支持插件模式嵌入宿主框架運(yùn)行,以及獨(dú)立部署模式
三 深度學(xué)習(xí)編譯器的背景
近幾年來,深度學(xué)習(xí)編譯器作為一個(gè)較新的技術(shù)方向異常地活躍,包括老牌一些的TensorFlow XLA、TVM、Tensor Comprehension、Glow,到后來呼聲很高的MLIR以及其不同領(lǐng)域的延伸項(xiàng)目IREE、mlir-hlo等等。能夠看到不同的公司、社區(qū)在這個(gè)領(lǐng)域進(jìn)行著大量的探索和推進(jìn)。
1 AI浪潮與芯片浪潮共同催生——從萌芽之初到蓬勃發(fā)展
深度學(xué)習(xí)編譯器近年來之所以能夠受到持續(xù)的關(guān)注,主要來自于幾個(gè)方面的原因:
框架性能優(yōu)化在模型泛化性方面的需求
深度學(xué)習(xí)還在日新月異的發(fā)展之中,創(chuàng)新的應(yīng)用領(lǐng)域不斷涌現(xiàn),復(fù)雜多變的場景下如何有效的將硬件的算力充分發(fā)揮出來成為了整個(gè)AI應(yīng)用鏈路中非常重要的一環(huán)。在早期,神經(jīng)網(wǎng)絡(luò)部署的側(cè)重點(diǎn)在于框架和算子庫,這部分職責(zé)很大程度上由深度學(xué)習(xí)框架、硬件廠商提供的算子庫、以及業(yè)務(wù)團(tuán)隊(duì)的手工優(yōu)化工作來承擔(dān)。

上圖將近年的深度學(xué)習(xí)框架粗略分為三代。一個(gè)趨勢是在上層的用戶API層面,這些框架在變得越來越靈活,靈活性變強(qiáng)的同時(shí)也為底層性能問題提出了更大的挑戰(zhàn)。初代深度學(xué)習(xí)框架類似 Caffe 用 sequence of layer 的方式描述神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),第二代類似 TensorFlow 用更細(xì)粒度的 graph of operators 描述計(jì)算圖,到第三代類似 PyTorch,TensorFlow Eager Mode 的動態(tài)圖。我們可以看到框架越來越靈活,描述能力越來越強(qiáng),帶來的問題是優(yōu)化底層性能變得越來越困難。業(yè)務(wù)團(tuán)隊(duì)也經(jīng)常需要補(bǔ)充完成所需要的手工優(yōu)化,這些工作依賴于特定業(yè)務(wù)和對底層硬件的理解,耗費(fèi)人力且難以泛化。而深度學(xué)習(xí)編譯器則是結(jié)合編譯時(shí)圖層的優(yōu)化以及自動或者半自動的代碼生成,將手工優(yōu)化的原理做泛化性的沉淀,以替代純手工優(yōu)化帶來的各種問題,去解決深度學(xué)習(xí)框架的靈活性和性能之間的矛盾。
AI框架在硬件泛化性方面的需求
表面上看近些年AI發(fā)展的有目共睹、方興未艾,而后臺的硬件算力數(shù)十年的發(fā)展才是催化AI繁榮的核心動力。隨著晶體管微縮面臨的各種物理挑戰(zhàn)越來越大,芯片算力的增加越來越難,摩爾定律面臨失效,創(chuàng)新體系結(jié)構(gòu)的各種DSA芯片迎來了一波熱潮,傳統(tǒng)的x86、ARM等都在不同的領(lǐng)域強(qiáng)化著自己的競爭力。硬件的百花齊放也為AI框架的發(fā)展帶來了新的挑戰(zhàn)。
而硬件的創(chuàng)新是一個(gè)問題,如何能把硬件的算力在真實(shí)的業(yè)務(wù)場景中發(fā)揮出來則是另外一個(gè)問題。新的AI硬件廠商不得不面臨除了要在硬件上創(chuàng)新,還要在軟件棧上做重度人力投入的問題。向下如何兼容硬件,成為了如今深度學(xué)習(xí)框架的核心難點(diǎn)之一,而兼容硬件這件事,則需要由編譯器來解決。
AI系統(tǒng)平臺對前端AI框架泛化性方面的需求
當(dāng)今主流的深度學(xué)習(xí)框架包括Tensoflow、Pytorch、Keras、JAX等等,幾個(gè)框架都有各自的優(yōu)缺點(diǎn),在上層對用戶的接口方面風(fēng)格各異,卻同樣面臨硬件適配以及充分發(fā)揮硬件算力的問題。不同的團(tuán)隊(duì)常根據(jù)自己的建模場景和使用習(xí)慣來選擇不同的框架,而云廠商或者平臺方的性能優(yōu)化工具和硬件適配方案則需要同時(shí)考慮不同的前端框架,甚至未來框架演進(jìn)的需求。Google利用XLA同時(shí)支持TensorFlow和JAX,同時(shí)其它開源社區(qū)還演進(jìn)出了Torch_XLA,Torch-MLIR這樣的接入方案,這些接入方案目前雖然在易用性和成熟程度等方面還存在一些問題,卻反應(yīng)出AI系統(tǒng)層的工作對前端AI框架泛化性方面的需求和技術(shù)趨勢。
2 什么是深度學(xué)習(xí)編譯器
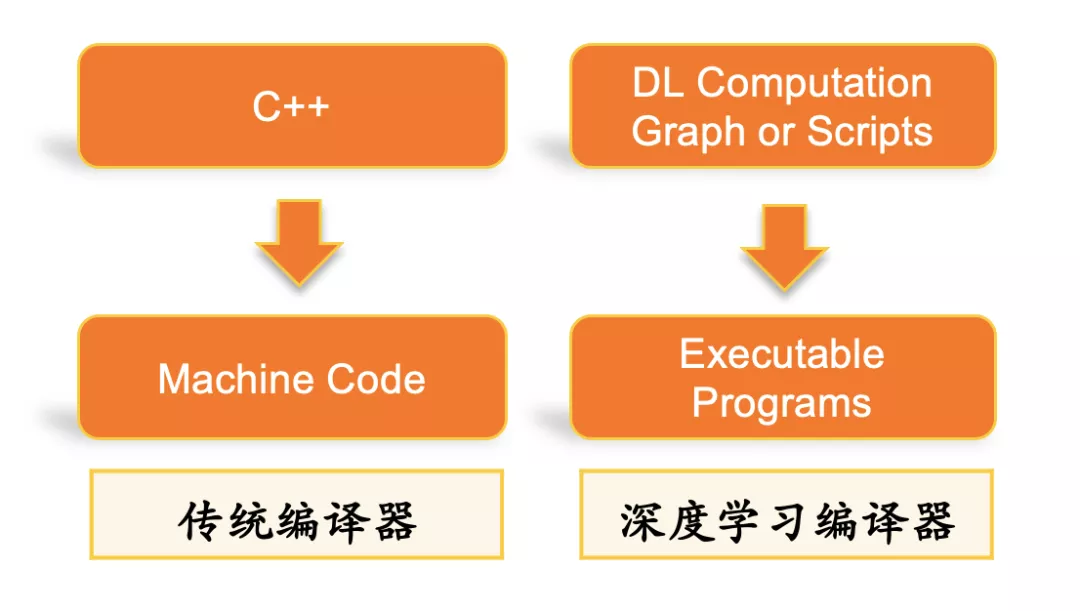
傳統(tǒng)編譯器是以高層語言作為輸入,避免用戶直接去寫機(jī)器碼,而用相對靈活高效的語言來工作,并在編譯的過程中引入優(yōu)化來解決高層語言引入的性能問題,平衡開發(fā)效率與性能之間的矛盾。而深度學(xué)習(xí)編譯器的作用相仿,其輸入是比較靈活的,具備較高抽象度的計(jì)算圖描述,輸出包括CPU、GPU及其他異構(gòu)硬件平臺上的底層機(jī)器碼及執(zhí)行引擎。
傳統(tǒng)編譯器的使命之一是減輕編程者的壓力。作為編譯器的輸入的高級語言往往更多地是描述一個(gè)邏輯,為了便利編程者,高級語言的描述會更加抽象和靈活,至于這個(gè)邏輯在機(jī)器上是否能夠高效的執(zhí)行,往往是考驗(yàn)編譯器的一個(gè)重要指標(biāo)。深度學(xué)習(xí)作為一個(gè)近幾年發(fā)展異常快速的應(yīng)用領(lǐng)域,它的性能優(yōu)化至關(guān)重要,并且同樣存在高層描述的靈活性和抽象性與底層計(jì)算性能之間的矛盾,因此專門針對深度學(xué)習(xí)的編譯器出現(xiàn)了。而傳統(tǒng)編譯器的另外一個(gè)重要使命是,需要保證編程者輸入的高層語言能夠執(zhí)行在不同體系結(jié)構(gòu)和指令集的硬件計(jì)算單元上,這一點(diǎn)也同樣反應(yīng)在深度學(xué)習(xí)編譯器上。面對一個(gè)新的硬件設(shè)備,人工的話不太可能有精力對那么多目標(biāo)硬件重新手寫一個(gè)框架所需要的全部算子實(shí)現(xiàn),深度學(xué)習(xí)編譯器提供中間層的IR,將頂層框架的模型流圖轉(zhuǎn)化成中間層表示IR,在中間層IR上進(jìn)行通用的圖層優(yōu)化,而在后端將優(yōu)化后的IR通用性的生成各個(gè)目標(biāo)平臺的機(jī)器碼。
深度學(xué)習(xí)編譯器的目標(biāo)是針對AI計(jì)算任務(wù),以通用編譯器的方式完成性能優(yōu)化和硬件適配。讓用戶可以專注于上層模型開發(fā),降低用戶手工優(yōu)化性能的人力開發(fā)成本,進(jìn)一步壓榨硬件性能空間。
3 距離大規(guī)模應(yīng)用面臨的瓶頸問題
深度學(xué)習(xí)編譯器發(fā)展到今天,雖然在目標(biāo)和技術(shù)架構(gòu)方面與傳統(tǒng)編譯器有頗多相似之處,且在技術(shù)方向上表現(xiàn)出了良好的潛力,然而目前的實(shí)際應(yīng)用范圍卻仍然距離傳統(tǒng)編譯器有一定的差距,主要難點(diǎn)包括:
易用性
深度學(xué)習(xí)編譯器的初衷是希望簡化手工優(yōu)化性能和適配硬件的人力成本。然而在現(xiàn)階段,大規(guī)模部署應(yīng)用深度學(xué)習(xí)編譯器的挑戰(zhàn)仍然較大,能夠?qū)⒕幾g器用好的門檻較高,造成這個(gè)現(xiàn)象的主要原因包括:
與前端框架對接的問題。不同框架對深度學(xué)習(xí)任務(wù)的抽象描述和API接口各有不同,語義和機(jī)制上有各自的特點(diǎn),且作為編譯器輸入的前端框架的算子類型數(shù)量呈開放性狀態(tài)。如何在不保證所有算子被完整支持的情況下透明化的支持用戶的計(jì)算圖描述,是深度學(xué)習(xí)編譯器能夠易于為用戶所廣泛使用的重要因素之一。
動態(tài)shape問題和動態(tài)計(jì)算圖問題。現(xiàn)階段主流的深度學(xué)習(xí)編譯器主要針對特定的靜態(tài)shape輸入完成編譯,此外對包含control flow語義的動態(tài)計(jì)算圖只能提供有限的支持或者完全不能夠支持。而AI的應(yīng)用場景卻恰恰存在大量這一類的任務(wù)需求。這時(shí)只能人工將計(jì)算圖改寫為靜態(tài)或者半靜態(tài)的計(jì)算圖,或者想辦法將適合編譯器的部分子圖提取出來交給編譯器。這無疑加重了應(yīng)用深度學(xué)習(xí)編譯器時(shí)的工程負(fù)擔(dān)。更嚴(yán)重的問題是,很多任務(wù)類型并不能通過人工的改寫來靜態(tài)化,這導(dǎo)致這些情況下編譯器完全無法實(shí)際應(yīng)用。
編譯開銷問題。作為性能優(yōu)化工具的深度學(xué)習(xí)編譯器只有在其編譯開銷對比帶來的性能收益有足夠優(yōu)勢的情況下才真正具有實(shí)用價(jià)值。部分應(yīng)用場景下對于編譯開銷的要求較高,例如普通規(guī)模的需要幾天時(shí)間完成訓(xùn)練任務(wù)有可能無法接受幾個(gè)小時(shí)的編譯開銷。對于應(yīng)用工程師而言,使用編譯器的情況下不能快速的完成模型的調(diào)試,也增加了開發(fā)和部署的難度和負(fù)擔(dān)。
對用戶透明性問題。部分AI編譯器并非完全自動的編譯工具,其性能表現(xiàn)比較依賴于用戶提供的高層抽象的實(shí)現(xiàn)模版。主要是為算子開發(fā)工程師提供效率工具,降低用戶人工調(diào)優(yōu)各種算子實(shí)現(xiàn)的人力成本。但這也對使用者的算子開發(fā)經(jīng)驗(yàn)和對硬件體系結(jié)構(gòu)的熟悉程度提出了比較高的要求。此外,對于新硬件的軟件開發(fā)者來說,現(xiàn)有的抽象卻又常常無法足夠描述創(chuàng)新的硬件體系結(jié)構(gòu)上所需要的算子實(shí)現(xiàn)。需要對編譯器架構(gòu)足夠熟悉的情況下對其進(jìn)行二次開發(fā)甚至架構(gòu)上的重構(gòu),門檻及開發(fā)負(fù)擔(dān)仍然很高。
魯棒性
目前主流的幾個(gè)AI編譯器項(xiàng)目大多數(shù)都還處于偏實(shí)驗(yàn)性質(zhì)的產(chǎn)品,但產(chǎn)品的成熟度距離工業(yè)級應(yīng)用有較大的差距。這里的魯棒性包含是否能夠順利完成輸入計(jì)算圖的編譯,計(jì)算結(jié)果的正確性,以及性能上避免coner case下的極端badcase等。
性能問題
編譯器的優(yōu)化本質(zhì)上是將人工的優(yōu)化方法,或者人力不易探究到的優(yōu)化方法通過泛化性的沉淀和抽象,以有限的編譯開銷來替代手工優(yōu)化的人力成本。然而如何沉淀和抽象的方法學(xué)是整個(gè)鏈路內(nèi)最為本質(zhì)也是最難的問題。深度學(xué)習(xí)編譯器只有在性能上真正能夠代替或者超過人工優(yōu)化,或者真正能夠起到大幅度降低人力成本作用的情況下才能真正發(fā)揮它的價(jià)值。
然而達(dá)到這一目標(biāo)卻并非易事,深度學(xué)習(xí)任務(wù)大都是tensor級別的計(jì)算,對于并行任務(wù)的拆分方式有很高的要求,但如何將手工的優(yōu)化泛化性的沉淀在編譯器技術(shù)內(nèi),避免編譯開銷爆炸以及分層之后不同層級之間優(yōu)化的聯(lián)動,仍然有更多的未知需要去探索和挖掘。這也成為以MLIR框架為代表的下一代深度學(xué)習(xí)編譯器需要著重思考和解決的問題。
四 BladeDISC的主要技術(shù)特點(diǎn)
項(xiàng)目最早啟動的初衷是為了解決XLA和TVM當(dāng)前版本的靜態(tài)shape限制,內(nèi)部命名為 DISC (DynamIc Shape Compiler),希望打造一款能夠在實(shí)際業(yè)務(wù)中使用的完備支持動態(tài)shape語義的深度學(xué)習(xí)編譯器。
從團(tuán)隊(duì)四年前啟動深度學(xué)習(xí)編譯器方向的工作以來,動態(tài)shape問題一直是阻礙實(shí)際業(yè)務(wù)落地的嚴(yán)重問題之一。彼時(shí),包括XLA在內(nèi)的主流深度學(xué)習(xí)框架,都是基于靜態(tài)shape語義的編譯器框架。典型的方案是需要用戶指定輸入的shape,或是由編譯器在運(yùn)行時(shí)捕捉待編譯子圖的實(shí)際輸入shape組合,并且為每一個(gè)輸入shape組合生成一份編譯結(jié)果。
靜態(tài)shape編譯器的優(yōu)勢顯而易見,編譯期完全已知靜態(tài)shape信息的情況下,Compiler可以作出更好的優(yōu)化決策并得到更好的CodeGen性能,同時(shí)也能夠得到更好的顯存/內(nèi)存優(yōu)化plan和調(diào)度執(zhí)行plan。然而,其缺點(diǎn)也十分明顯,具體包括:
- 大幅增加編譯開銷。引入離線編譯預(yù)熱過程,大幅增加推理任務(wù)部署過程復(fù)雜性;訓(xùn)練迭代速度不穩(wěn)定甚至整體訓(xùn)練時(shí)間負(fù)優(yōu)化。
- 部分業(yè)務(wù)場景shape變化范圍趨于無窮的,導(dǎo)致編譯緩存永遠(yuǎn)無法收斂,方案不可用。
- 內(nèi)存顯存占用的增加。編譯緩存額外占用的內(nèi)存顯存,經(jīng)常導(dǎo)致實(shí)際部署環(huán)境下的內(nèi)存/顯存OOM,直接阻礙業(yè)務(wù)的實(shí)際落地。
- 人工padding為靜態(tài)shape等緩解性方案對用戶不友好,大幅降低應(yīng)用的通用性和透明性,影響迭代效率。
在2020年夏天,DISC完成了僅支持TensorFlow前端以及Nvidia GPU后端的初版,并且正式在阿里內(nèi)部上線投入實(shí)際應(yīng)用。最早在幾個(gè)受困于動態(tài)shape問題已久的業(yè)務(wù)場景上投入使用,并且得到了預(yù)期中的效果。即在一次編譯且不需要用戶對計(jì)算圖做特殊處理的情況下,完備支持動態(tài)shape語義,且性能幾乎與靜態(tài)shape編譯器持平。對比TensorRT等基于手工算子庫為主的優(yōu)化框架,DISC基于編譯器自動codegen的技術(shù)架構(gòu)在經(jīng)常為非標(biāo)準(zhǔn)開源模型的實(shí)際業(yè)務(wù)上獲得了明顯的性能和易用性優(yōu)勢。
從2020年第二季度開始至今,DISC持續(xù)投入研發(fā)力量,針對前文提到的從云端平臺方視角看到的深度學(xué)習(xí)編譯器距離大規(guī)模部署和應(yīng)用的幾個(gè)瓶頸問題,在性能、算子覆蓋率和魯棒性、CPU及新硬件支持、前端框架支持等方面逐漸完善。目前在場景覆蓋能力和性能等方面,已經(jīng)逐漸替換掉團(tuán)隊(duì)過往基于XLA和TVM等靜態(tài)shape框架上的工作,成為PAI-Blade支持阿里內(nèi)部及阿里云外部業(yè)務(wù)的主要優(yōu)化手段。2021年后,DISC在CPU及GPGPU體系結(jié)構(gòu)的后端硬件上的性能有了顯著的提升,同時(shí)在新硬件的支持上面投入了更多的技術(shù)力量。2021年底,為了吸引更多的技術(shù)交流和合作共建需要,以及更大范圍的用戶反饋,正式更名為BladeDISC并完成了初版開源。
五 關(guān)鍵技術(shù)
BladeDISC的整體架構(gòu),及其在阿里云相關(guān)產(chǎn)品中的上下文關(guān)系如下圖所示:
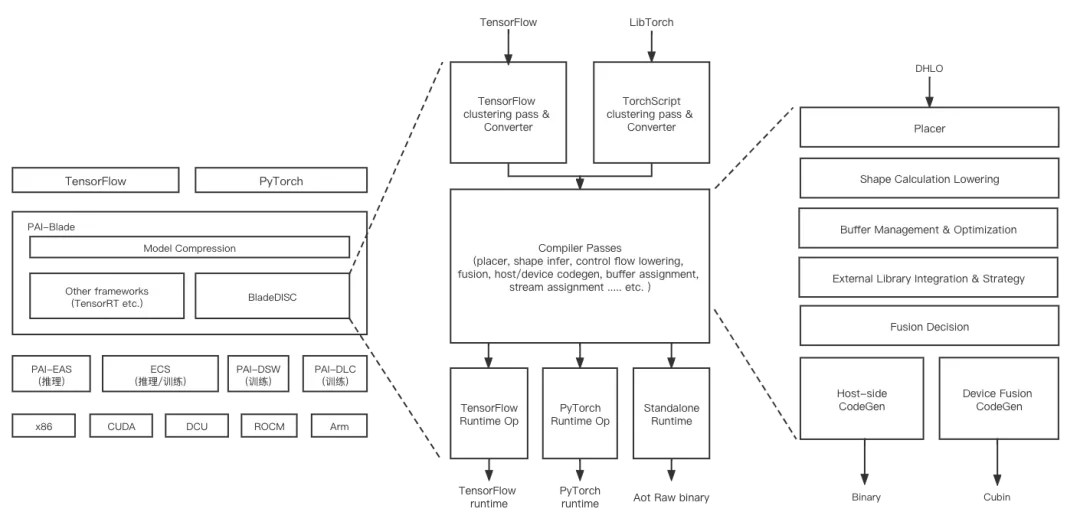
1 MLIR基礎(chǔ)架構(gòu)
MLIR是由Google在2019年發(fā)起的項(xiàng)目,MLIR 的核心是一套靈活的多層IR基礎(chǔ)設(shè)施和編譯器實(shí)用工具庫,深受 LLVM 的影響,并重用其許多優(yōu)秀理念。這里我們選擇基于MLIR的主要原因包括其比較豐富的基礎(chǔ)設(shè)施支持,方便擴(kuò)展的模塊化設(shè)計(jì)架構(gòu)以及MLIR較強(qiáng)的膠水能力。
2 動態(tài)shape編譯

上圖為BladeDISC的主體Pass Pipeline設(shè)計(jì)。對比目前主流的深度學(xué)習(xí)編譯器項(xiàng)目,主要技術(shù)特點(diǎn)如下:
圖層IR設(shè)計(jì)
BladeDISC選擇基于HLO作為核心圖層IR來接入不同的前端框架,但是HLO是原本為XLA設(shè)計(jì)的純靜態(tài)shape語義的IR。靜態(tài)場景下,HLO IR中的shape表達(dá)會被靜態(tài)化,所有的shape計(jì)算會被固化為編譯時(shí)常量保留在編譯結(jié)果中;而在動態(tài)shape場景下,IR本身需要有足夠的能力表達(dá)shape計(jì)算和動態(tài)shape信息的傳遞。BladeDISC從項(xiàng)目建立開始一直與MHLO社區(qū)保持緊密的合作,在XLA的HLO IR基礎(chǔ)上,擴(kuò)展了一套具有完備動態(tài)shape表達(dá)能力的IR,并增加了相應(yīng)的基礎(chǔ)設(shè)施以及前端框架的算子轉(zhuǎn)換邏輯。這部分實(shí)現(xiàn)目前已經(jīng)完整upstream至MHLO社區(qū),確保后續(xù)其它MHLO相關(guān)項(xiàng)目中IR的一致性。
運(yùn)行時(shí)Shape計(jì)算、存儲管理和Kernel調(diào)度
動態(tài)shape編譯的主要挑戰(zhàn)來自于需要在靜態(tài)的編譯過程中能夠處理動態(tài)的計(jì)算圖語義。為完備支持動態(tài)shape,編譯結(jié)果需要能夠在運(yùn)行時(shí)做實(shí)時(shí)的shape推導(dǎo)計(jì)算,不僅要為數(shù)據(jù)計(jì)算,同時(shí)也需要為shape計(jì)算做代碼生成。計(jì)算后的shape信息用于做內(nèi)存/顯存管理,以及kernel調(diào)度時(shí)的參數(shù)選擇等等。BladeDISC的pass pipeline的設(shè)計(jì)充分考慮了上述動態(tài)shape語義支持的需求,采用了host-device聯(lián)合codegen的方案。以GPU Backend為例,包括shape計(jì)算、內(nèi)存/顯存申請釋放、硬件管理、kernel launch運(yùn)行時(shí)流程全部為自動代碼生成,以期得到完備的動態(tài)shape端到端支持方案和更為極致的整體性能。
動態(tài)shape下的性能問題
在shape未知或者部分未知的情況下,深度學(xué)習(xí)編譯器在性能上面臨的挑戰(zhàn)被進(jìn)一步放大。在大多數(shù)主流硬件backend上,BladeDISC采用區(qū)分計(jì)算密集型部分和訪存密集型部分的策略,以期在性能與復(fù)雜性和編譯開銷之間獲取更好的平衡。
對于計(jì)算密集型部分,不同的shape要求更加精細(xì)的schedule實(shí)現(xiàn)來獲得更好的性能,pass pipeline在設(shè)計(jì)上的主要考慮是需要支持在運(yùn)行時(shí)根據(jù)不同的具體shape選擇合適的算子庫實(shí)現(xiàn),以及處理動態(tài)shape語義下的layout問題。
而訪存密集型部分的自動算子融合作為深度學(xué)習(xí)編譯器主要的性能收益來源之一,同樣面臨shape未知情況下在性能上的挑戰(zhàn)。許多靜態(tài)shape語義下比較確定性的問題,例如指令層的向量化,codegen模版選擇,是否需要implicit broadcast等等在動態(tài)shape場景下都會面臨更大的復(fù)雜性。針對這些方面的問題,BladeDISC選擇將部分的優(yōu)化決策從編譯時(shí)下沉到運(yùn)行時(shí)。即在編譯期根據(jù)一定的規(guī)則生成多個(gè)版本的kernel實(shí)現(xiàn),在運(yùn)行時(shí)根據(jù)實(shí)際shape自動選擇最優(yōu)的實(shí)現(xiàn)。這一機(jī)制被稱作speculation,在BladeDISC內(nèi)基于host-device的聯(lián)合代碼生成來實(shí)現(xiàn)。此外,在編譯期沒有具體shape數(shù)值的情況下,會很容易在各個(gè)層級丟失掉大量的優(yōu)化機(jī)會,從圖層的線性代數(shù)簡化、fusion決策到指令層級的CSE、常數(shù)折疊等。BladeDISC在IR及pass pipeline的設(shè)計(jì)過程中著重設(shè)計(jì)了shape constraint在IR中的抽象和在pass pipeline中的使用,例如編譯期未知的不同dimension size之間的約束關(guān)系等。在優(yōu)化整體性能方面起到了比較明顯的作用,保證能夠足夠接近甚至超過靜態(tài)shape編譯器的性能結(jié)果。
大顆粒度算子融合
團(tuán)隊(duì)在開啟BladeDISC項(xiàng)目之前,曾經(jīng)基于靜態(tài)shape編譯器在大顆粒度算子融合及自動代碼生成方面有過若干探索[3][4],其基本思想可以概括為借助于GPU硬件中低訪存開銷的shared memory或CPU中低訪存開銷的Memory Cache,將不同schedule的計(jì)算子圖縫合進(jìn)同一個(gè)kernel內(nèi),實(shí)現(xiàn)多個(gè)parallel loop復(fù)合,這種codegen方法稱之為fusion-stitching。這種訪存密集型子圖的自動代碼生成打破了常規(guī)的loop fusion,input/output fusion對fusion顆粒度的限制。在保證代碼生成質(zhì)量的同時(shí),大幅增加fusion顆粒度,同時(shí)避免復(fù)雜性及編譯開銷爆炸。且整個(gè)過程完全對用戶透明,無需人工指定schedule描述。
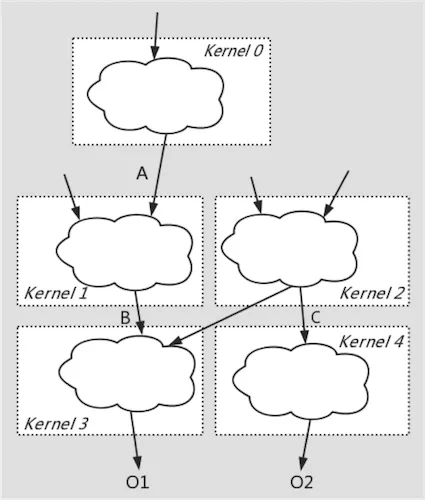
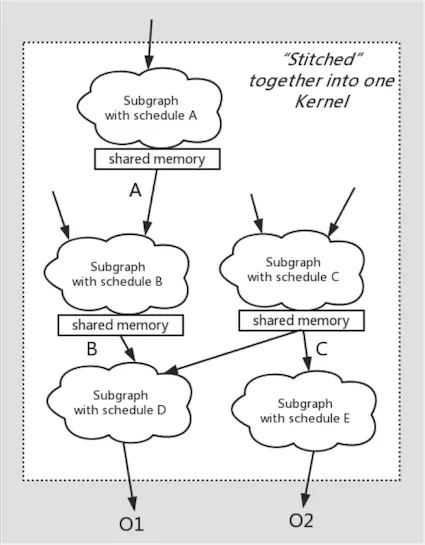
在動態(tài)shape語義下實(shí)現(xiàn)fusion-stitching對比靜態(tài)shape語義下同樣需要處理更大的復(fù)雜性,動態(tài)shape語義下的shape constraint抽象一定程度上簡化了這一復(fù)雜性,使整體性能進(jìn)一步接近甚至超過手工算子實(shí)現(xiàn)。
3 多前端框架支持
AICompiler框架在設(shè)計(jì)時(shí)也包含了擴(kuò)展支持不同前端框架的考慮。PyTorch側(cè)通過實(shí)現(xiàn)一個(gè)輕量的Converter將TorchScript轉(zhuǎn)換為DHLO IR實(shí)現(xiàn)了對PyTorch推理作業(yè)的覆蓋。MLIR相對完備的IR基礎(chǔ)設(shè)施也為Converter的實(shí)現(xiàn)提供了便利。BladeDISC包含Compiler以及適配不同前端框架的Bridge側(cè)兩部分。其中Bridge進(jìn)一步分為宿主框架內(nèi)的圖層pass以及運(yùn)行時(shí)Op兩部分,以插件的方式接入宿主框架。這種工作方式使BladeDISC可以透明化的支持前端計(jì)算圖,可以適配用戶各種版本的宿主框架。
4 運(yùn)行時(shí)環(huán)境適配
為將編譯的結(jié)果能夠配合TensorFlow/PyTorch等宿主在各自的運(yùn)行環(huán)境中執(zhí)行起來,以及管理運(yùn)行時(shí)IR層不易表達(dá)的狀態(tài)信息等等,我們?yōu)椴煌倪\(yùn)行時(shí)環(huán)境實(shí)現(xiàn)了一套統(tǒng)一的Compiler架構(gòu),并引入了運(yùn)行時(shí)抽象層,即RAL(Runtime Abstraction Layer)層。
RAL實(shí)現(xiàn)了多種運(yùn)行環(huán)境的適配支持,用戶可以根據(jù)需要進(jìn)行選擇,具體包括:
- 全圖編譯,獨(dú)立運(yùn)行。當(dāng)整個(gè)計(jì)算圖都支持編譯時(shí),RAL提供了一套簡易的runtime以及在此之上RAL Driver的實(shí)現(xiàn),使得compiler編譯出來結(jié)果可以脫離框架直接運(yùn)行,減少框架overhead。
- TF中子圖編譯運(yùn)行。
- Pytorch中子圖編譯運(yùn)行。
以上環(huán)境中在諸如資源管理,API語義等上存在差異,RAL通過抽象出一套最小集合的API ,并清晰的定義出它們的語義,將編譯器與運(yùn)行時(shí)隔離開來,來達(dá)到在不同的環(huán)境中都能夠執(zhí)行編譯出來的結(jié)果的目的。此外RAL層實(shí)現(xiàn)了無狀態(tài)編譯,解決了計(jì)算圖的編譯之后,編譯的結(jié)果可能被多次執(zhí)行時(shí)的狀態(tài)信息處理問題。一方面簡化了代碼生成的復(fù)雜度,另一方面也更容易支持多線程并發(fā)執(zhí)行(比如推理)的場景,同時(shí)在錯(cuò)誤處理,回滾方面也更加容易支持。
六 應(yīng)用場景
BladeDISC的典型應(yīng)用場景可以不太嚴(yán)格的分為兩類:其一是在主流的硬件平臺上(包括Nvidia GPU,x86 CPU等)上作為通用、透明的性能優(yōu)化工具,降低用戶部署AI作業(yè)的人力負(fù)擔(dān),提高模型迭代效率;另一個(gè)重要的應(yīng)用場景是幫助新硬件做AI場景的適配和接入支持。
目前BladeDISC已經(jīng)廣泛應(yīng)用在阿里內(nèi)部和阿里云上外部用戶的多個(gè)不同應(yīng)用場景下,覆蓋模型類型涉及NLP、機(jī)器翻譯、語音類ASR、語音TTS、圖像檢測、識別、AI for science等等多種典型AI應(yīng)用;覆蓋行業(yè)包括互聯(lián)網(wǎng)、電商、自動駕駛、安全行業(yè)、在線娛樂、醫(yī)療和生物等等。
在推理場景下,BladeDISC與TensorRT等廠商提供的推理優(yōu)化工具形成良好的技術(shù)互補(bǔ),其主要差異性優(yōu)勢包括:
- 應(yīng)對動態(tài)shape業(yè)務(wù)完備的動態(tài)shape語義支持
- 基于compiler based的技術(shù)路徑的模型泛化性在非標(biāo)準(zhǔn)模型上的性能優(yōu)勢
- 更為靈活的部署模式選擇,以插件形式支持前端框架的透明性優(yōu)勢
下圖為Nvidia T4硬件上幾個(gè)真實(shí)的業(yè)務(wù)例子的性能收益數(shù)字:
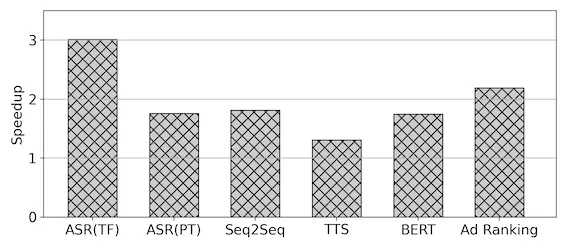
在新硬件支持方面,目前普遍的情況是除了積累比較深厚的Nvidia等頭部廠商之外,包括ROCM等其它GPGPU硬件普遍存在的情況是硬件的指標(biāo)已經(jīng)具備相當(dāng)?shù)母偁幜Γ珡S商受制于AI軟件棧上的積累相對較少,普遍存在硬件算力無法發(fā)揮出來導(dǎo)致硬件落地應(yīng)用困難的問題。如前文所述,基于編譯器的技術(shù)路徑下天然對于硬件的后端具備一定的泛化能力,且與硬件廠商的技術(shù)儲備形成比較強(qiáng)的互補(bǔ)。BladeDISC目前在GPGPU和通用CPU體系結(jié)構(gòu)上的儲備相對比較成熟。以GPGPU為例,在Nvidia GPU上的絕大部分技術(shù)棧可以遷移至海光DCU和AMD GPU等體系結(jié)構(gòu)相近的硬件上。BladeDISC較強(qiáng)的硬件泛化能力配合硬件本身較強(qiáng)的通用性,很好的解決了新硬件適配的性能和可用性問題。
下圖為海光DCU上幾個(gè)真實(shí)業(yè)務(wù)例子上的性能數(shù)字:
某識別類模型 | 推理 | 不同batchsize下 2.21X ~ 2.31X |
某檢測類模型A | 推理 | 不同batchsize下 1.73X ~ 2.1X |
某檢測類模型B | 推理 | 不同batchsize下 1.04X ~ 1.59X |
某分子動力學(xué)模型 | 訓(xùn)練 | 2.0X |
七 開源生態(tài)——構(gòu)想和未來
我們決定建設(shè)開源生態(tài)主要有如下的考慮:
- BladeDISC發(fā)源于阿里云計(jì)算平臺團(tuán)隊(duì)的業(yè)務(wù)需求,在開發(fā)過程中與MLIR/MHLO/IREE等社區(qū)同行之間的討論和交流給了我們很好的輸入和借鑒。在我們自身隨著業(yè)務(wù)需求的迭代逐漸完善的同時(shí),也希望能夠開源給社區(qū),在目前整個(gè)AI編譯器領(lǐng)域?qū)嶒?yàn)性項(xiàng)目居多,偏實(shí)用性強(qiáng)的產(chǎn)品偏少,且不同技術(shù)棧之間的工作相對碎片化的情況下,希望能夠?qū)⒆陨淼慕?jīng)驗(yàn)和理解也同樣回饋給社區(qū),希望和深度學(xué)習(xí)編譯器的開發(fā)者和AI System的從業(yè)者之間有更多更好的交流和共建,為這個(gè)行業(yè)貢獻(xiàn)我們的技術(shù)力量。
- 我們希望能夠借助開源的工作,收到更多真實(shí)業(yè)務(wù)場景下的用戶反饋,以幫助我們持續(xù)完善和迭代,并為后續(xù)的工作投入方向提供輸入。
后續(xù)我們計(jì)劃以兩個(gè)月為單位定期發(fā)布Release版本。BladeDISC近期的Roadmap如下:
- 持續(xù)的魯棒性及性能改進(jìn)
- x86后端補(bǔ)齊計(jì)算密集型算子的支持,端到端完整開源x86后端的支持
- GPGPU上基于Stitching的大顆粒度自動代碼生成
- AMD rocm GPU后端的支持
- PyTorch訓(xùn)練場景的支持
此外,在中長期,我們在下面幾個(gè)探索性的方向上會持續(xù)投入精力,也歡迎各種維度的反饋和改進(jìn)建議以及技術(shù)討論,同時(shí)我們十分歡迎和期待對開源社區(qū)建設(shè)感興趣的同行一起參與共建。
- 更多新硬件體系結(jié)構(gòu)的支持和適配,以及新硬件體系結(jié)構(gòu)下軟硬件協(xié)同方法學(xué)的沉淀
- 計(jì)算密集型算子自動代碼生成和動態(tài)shape語義下全局layout優(yōu)化的探索
- 稀疏子圖的優(yōu)化探索
- 動態(tài)shape語義下運(yùn)行時(shí)調(diào)度策略、內(nèi)存/顯存優(yōu)化等方面的探索
- 模型壓縮與編譯優(yōu)化聯(lián)合的技術(shù)探索
- 圖神經(jīng)網(wǎng)絡(luò)等更多AI作業(yè)類型的支持和優(yōu)化等
開源地址:
https://github.com/alibaba/BladeDISC
參考文獻(xiàn)
- "DISC: A Dynamic Shape Compiler for Machine Learning Workloads", Kai Zhu, Wenyi Zhao, Zhen Zheng, Tianyou Guo, Pengzhan Zhao, Feiwen Zhu, Junjie Bai, Jun Yang, Xiaoyong Liu, Lansong Diao, Wei Lin
- Presentations on MLIR Developers' Weekly Conference: 1, 2
- "AStitch: Enabling A New Multi-Dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures", Zhen Zheng, Xuanda Yang, Pengzhan Zhao, Guoping Long, Kai Zhu, Feiwen Zhu, Wenyi Zhao, Xiaoyong Liu, Jun Yang, Jidong Zhai, Shuaiwen Leon Song, and Wei Lin. The 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2022. [to appear]
- "FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads", Zhen Zheng, Pengzhan Zhao, Guoping Long, Feiwen Zhu, Kai Zhu, Wenyi Zhao, Lansong Diao, Jun Yang, and Wei Lin. arXiv preprint















