如何避免寫出“慢SQL”
所謂慢SQL,就是執行特別慢的SQL語句。什么樣的SQL語句才是慢SQL?多慢才算是慢SQL?對于這類問題,并沒有一個非常明確的標準,或者說是界限。但這并不代表區分正常的SQL和慢SQL很困難,在實際的大多數系統中,慢SQL消耗掉的數據庫資源,往往是正常SQL的幾倍、幾十倍,甚至幾百倍,所以慢SQL還是非常容易區分的。
問題是,我們不能等到系統上線,慢SQL消耗完數據庫的資源之后,再找出慢SQL來改進,那樣將會造成很多不良影響。那么,怎樣才能在開發階段就盡量避免寫出慢SQL呢?
01定量認識MySQL
這說明,慢SQL對數據庫的影響,是一個從量變到質變的過程,對“量”的把握,對于開發人員來說是很重要的。一個合格的程序員,需要對數據庫的能力有一個定量的認識。
影響MySQL處理能力的因素有很多,比如,服務器的配置、數據庫中數據量的大小、MySQL的一些參數配置、數據庫的繁忙程度,等等。但是,通常情況下,這些因素對于MySQL的性能和處理能力的影響,大概在一個數量級的范圍內,也就是上下幾倍的性能差距。所以,我們不需要知道精確的性能數據,只要掌握一個大致的量級,就足夠應對實際的開發工作了。
目前,一臺普通的MySQL數據庫服務器,處理能力的極限大致是,每秒一萬條左右的簡單SQL。這里的“簡單SQL”,指的是類似于主鍵查詢這種不需要遍歷很多條記錄的SQL語句。根據配置的高低,服務器的處理能力也會有所不同,可能低配的服務器只能達到每秒幾千條,高配的服務器則可以達到每秒幾萬條,所以這里給出的每秒一萬條是中位數的經驗值。考慮到正常的系統不可能只有簡單SQL,所以實際的處理能力還要打很大折扣。
我個人的經驗是,一臺MySQL數據庫服務器,平均每秒執行的SQL數量在幾百左右,一般就已經是非常繁忙了。即使看起來CPU利用率和磁盤繁忙程度并不高,我們也需要考慮為數據庫“減負”了。
另外一個重要的定量指標是,多慢的SQL才算是慢SQL?這里的“慢”,衡量的單位本來是執行時長,但是對于時長這個指標,我們在編寫SQL的時候并不好衡量。因此可以用執行SQL查詢時,需要遍歷的數據行數來替代時間作為衡量標準,因為查詢的執行時長與遍歷的數據行數基本上是正相關的。
我們在編寫一條查詢語句的時候,可以依據所要查詢數據表的數據總量估算一下這條查詢大致需要遍歷多少行數據。如果遍歷的行數在百萬以內,只要不是每秒都要執行幾十上百次的查詢,就可以認為該查詢是安全的。遍歷數據行數達到幾百萬量級的,查詢最快也要花費幾秒的時間,這時我們就要仔細考慮有沒有優化的辦法。遍歷行數達到千萬量級或以上的,這種SQL就不應該出現在系統中了。當然,我們這里討論的都是在線交易系統,離線分析類系統另當別論。
遍歷行數達到千萬量級的SQL,是MySQL查詢的一個坎兒。在MySQL中,單個表的數據量,也要盡量控制在一千萬條以下,最多不要超過兩三千萬這個量級。原因很簡單,對一個千萬量級的表執行查詢,加上幾個WHERE條件過濾一下,符合條件的數據最多可能是幾十萬或百萬量級的,還是可以接受的。但如果再與其他的表做一個聯合查詢,遍歷的數據量很可能就會超過千萬量級了。所以,每個表的數據量最好控制在千萬量級以內。
如果數據庫中的數據量本身就很多,而且查詢業務邏輯確實需要遍歷大量數據,應該怎么辦呢?
02使用索引避免全表掃描
使用索引,可以有效減少執行查詢時遍歷數據的行數,從而提高查詢的性能。
數據庫索引的原理比較簡單,一個例子就能說明白。比如,有一個無序的數組,數組中的每個元素都是一個用戶對象。如果我們要把所有姓李的用戶都找出來,那么比較笨的辦法是,用一個循環把數組遍歷一遍。
是否還有更好的辦法呢?答案是肯定的。比如,我們可以用一個Map(在某些編程語言中是Dictionary)來為數組做一個索引,Key用于保存姓氏,值是所有這個姓氏的用戶對象在數組中序號的集合,如圖1所示。這樣在查找的時候,就不用遍歷數組了,只需要先在Map中查找,然后再根據序號直接去數組中獲取用戶數據即可,這樣查找速度就快多了。
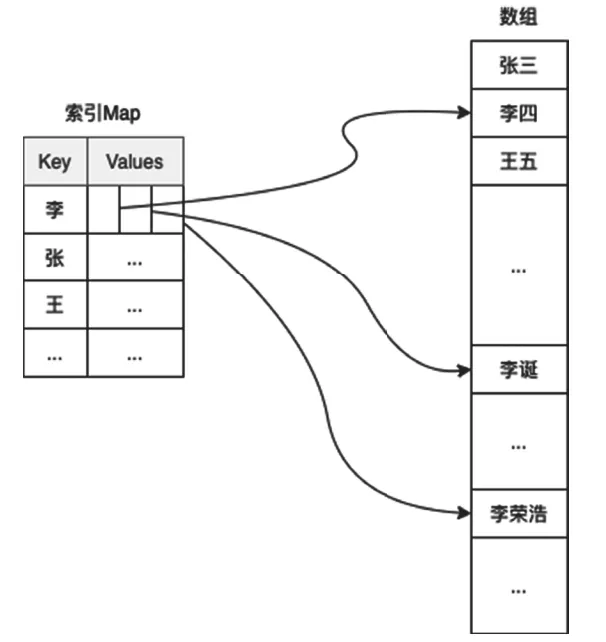
圖1 基于Map構建的內存索引
下面我們把這個例子對應到數據庫中,存放用戶數據的數組就是表,我們構建的Map就是索引。實際上,數據庫索引的數據結構與編程語言中的Map或Dictionary的結構差不多,基本上都是各種B樹和哈希表。
絕大多數情況下,我們編寫的查詢語句,都應該使用索引,以避免遍歷整張表,也就是通常所說的,避免全表掃描。在開發新功能時,每當需要為數據庫增加一個新的查詢時,我們都要事先評估一下,是否可以由索引支撐新的查詢語句,如果有必要,則需要新建索引,以支持新增的查詢。
但是,增加索引需要付出的代價是,會降低數據插入、刪除和更新的性能。這一點也很好理解,增加了索引之后,當數據發生變化的時候,不僅要變更數據表里的數據,還要變更各個索引。所以,對于更新頻繁并且對更新性能要求較高的表,可以盡量少建索引。而對于查詢較多、更新較少的表,可以根據查詢的業務邏輯,適當多建一些索引。
那么,如何寫SQL才能更好地利用索引,使查詢效率更高呢?這是一門技藝,需要有豐富的經驗,不是學習完本文的內容就能練成的(推薦閱讀《電商存儲系統實戰:架構設計與海量數據處理》)。但是,對于SQL的查詢性能,我們還是有方法評估其是否為一個潛在的“慢SQL”的。
對于邏輯不是很復雜的單表查詢,我們可能還可以分析出查詢會使用哪個索引。但如果是比較復雜的多表聯合查詢,單看SQL語句本身,我們將很難分析出查詢到底會使用哪些索引,會遍歷多少行數據。MySQL和大部分數據庫都提供了一個可用于分析查詢的功能,即執行計劃。
03分析SQL執行計劃
在MySQL中使用執行計劃非常簡單,只要在SQL語句前面加上EXPLAIN關鍵字,然后執行這個查詢語句就可以了。
下面就來舉例說明,比如,有這樣一個用戶表,包含用戶ID、姓名、部門編號和狀態這幾個字段,如圖2所示。
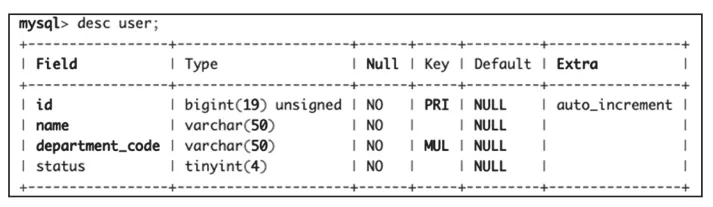
圖2 用戶表示例
我們希望查詢某個二級部門下的所有人,查詢條件是,部門代號以00028開頭的所有人。下面這兩個SQL語句的查詢結果是一樣的,都滿足要求。那么,哪個查詢語句的性能更好呢?
1SELECT * FROM user WHERE left(department_code, 5) = '00028';
2
3SELECT * FROM user WHERE department_code LIKE '00028%';
我們分別查看一下這兩個SQL語句的執行計劃,如圖3所示。

圖3 兩個SQL語句的執行計劃
下面就來分析一下這兩個SQL語句的執行計劃。首先來看rows這一列,rows列的含義是,MySQL預估執行這個SQL可能會遍歷的數據行數。第一個SQL遍歷了4534行,即整個User表的數據條數;第二個SQL只有8行,這8行其實就是符合條件的8條記錄。顯然,第二個SQL的查詢性能要遠高于第一個SQL。
為什么第一個SQL需要全表掃描,而第二個SQL只需要遍歷很少的行數呢?注意看type這一列,type列表示這個查詢的訪問類型。ALL代表全表掃描,這是性能最差的情況。range代表使用了索引,表示只在索引中進行范圍查找,這是因為SQL語句的WHERE條件中有一個LIKE的查詢限制。如果直接使用了索引,則type列顯示的是index,并且可以在key列中看到實際上使用的是哪個索引。
通過對比這兩個SQL的執行計劃,我們可以看到,第二個SQL雖然使用了公認為低效的LIKE查詢條件,但是由于用到了索引的范圍查找,因此遍歷數據的行數遠遠少于第一個SQL,查詢性能更好。
04小結
在開發階段,衡量一個SQL語句查詢性能的手段是,預估執行SQL時需要遍歷的數據行數。如果遍歷行數在百萬量級以內,則可以認為是安全的SQL;百萬到千萬這個量級,則需要仔細評估和優化;千萬量級以上則是非常危險的。為了降低寫出慢SQL的可能性,每個數據表的行數最好控制在千萬量級以內。
索引可以顯著減少查詢遍歷數據的數量,所以提升SQL查詢性能最有效的方式是,讓查詢盡可能多地使用索引。但是,索引也是一把雙刃劍,其在提升查詢性能的同時,也會降低數據更新的性能。
對于復雜的查詢,最好使用SQL執行計劃,事先對查詢做一個分析。從SQL執行計劃的結果中,我們可以看到查詢預估的遍歷行數,以及其會使用哪些索引。執行計劃也可以很好地幫助大家對查詢語句進行優化。
關于作者:李玥,美團基礎技術部高級技術專家,極客時間《后端存儲實戰課》《消息隊列高手課》等專欄作者。曾在當當網、京東零售等公司任職。從事互聯網電商行業基礎架構領域的架構設計和研發工作多年,曾多次參與雙十一和618電商大促。專注于分布式存儲、云原生架構下的服務治理、分布式消息和實時計算等技術領域,致力于推進基礎架構技術的創新與開源。
本文摘編自《電商存儲系統實戰:架構設計與海量數據處理》,經出版方授權發布。(ISBN:9787111697411)轉載請保留文章出處。