













2022年的五個大數據趨勢
2021年,我們看到圍繞現代數據棧的興起出現了相當大的加速效應。我們現在有一個海嘯般的通訊、影響者、投資者、專門的網站、會議和活動來宣揚它。圍繞現代數據棧的概念(盡管仍處于早期階段)與云中數據工具的爆炸性增長緊密相連。云計算帶來了一種新的基礎設施模式,它將幫助我們快速地、程序化地、按需地建立這些數據棧,使用像Kubernetes這樣的云原生技術、像Terraform這樣的基礎設施即代碼以及DevOps的云計算最佳實踐。因此,基礎設施成為構建和實施現代數據棧的一個關鍵因素。
當我們已經進入2022年,我們可以清楚地看到軟件工程的最佳實踐已經開始注入數據:數據質量監控和可觀察性、不同ETL層的專業化、數據探索和數據安全都在2021年蓬勃發展,并將繼續下去,因為從早期創業公司到價值數十億美元的財富500強企業的數據驅動型公司繼續將數據存儲和處理到數據庫、云數據倉庫、數據湖和數據湖倉。
下面你會發現我們預測的5個數據趨勢將在2022年確立或加速。
1.分析工程師的崛起將加速
如果說2020年和2021年是關于數據工程師的崛起(根據Dice的科技工作報告,這是最重要的)。 fastest-growing job in tech in 2020),那么在2022年,分析工程師將明確進入人們的視線。
云數據平臺的崛起已經改變了一切。傳統的技術結構,如立方體和單體數據倉庫,正在讓位于更靈活和可擴展的數據模型。此外,轉換可以在云平臺內對所有數據進行。ETL在很大程度上已經被ELT所取代。控制這種轉換邏輯的是誰?分析工程師。
這個角色的興起可以直接歸功于云數據平臺和數據構建工具(dbt)的興起。Dbt labs是dbt背后的公司,實際上創造了這個角色。dbt社區在2018年開始有五個用戶。截至2021年11月,有7300名用戶。
分析工程師是自然演化的一個例子,因為數據工程很可能最終成為多個T型工程角色,由開發自助式數據平臺而不是開發管道或報告的工程師驅動。
分析工程師首先出現在云端原生者和初創公司,如Spotify和Deliveroo,但最近開始在企業公司如捷藍航空中獲得地位。你可以閱讀 here an articleDeliveroo工程團隊關于分析工程在其組織中的出現和演變的文章。
我們看到越來越多的現代數據團隊將分析工程師加入他們的團隊,因為他們正變得越來越以數據為導向,并建立自我服務的數據管道。根據LinkedIn招聘信息的數據,典型的 must-have skills for an analytics engineer包括SQL、dbt、Python和與現代數據棧相關的工具(如Snowflake、Fivetran、Prefect、Astronomer等)。

截至2021年12月1日的LinkedIn職位發布數據
根據LinkedIn的數據,對數據科學家的需求大約是分析工程師的2.6到2.7,而且這個差距還在繼續縮小。
在2022年,我們預計這一差距將進一步縮小,因為對分析工程師的需求繼續增長,接近于對數據科學家(曾被稱為 the sexiest job in tech).
2.數據倉庫與數據湖庫的戰爭愈演愈烈(界限越來越模糊)。
數據界很少有人錯過了2021年底Databricks和Snowflake之間非常公開的對決。這一切開始于Databricks聲稱其數據湖庫技術的TPC-DS基準記錄,并說一項研究表明它比Snowflake快2.5倍。Snowflake表示,Databricks缺乏誠信,并表示該研究有缺陷,并有一個 "不確定 "的說法。
我們不必回到那么多年前,當時Snowflake和Databricks是新興的云計算軟件創業公司,他們是如此友好,他們的銷售團隊經常互相傳遞客戶線索。現在這一切都改變了,因為Snowflake指控Databricks采用不正當的營銷手段來贏得關注。這關系到未來幾百億美元的潛在收入。Databricks的首席執行官兼聯合創始人Ali Ghodsi在一份聲明中指出 ,Snowflake和Databricks如何在許多客戶的數據堆中共存。
"我們所看到的是,越來越多的人現在覺得他們可以真正使用他們在數據湖中的數據,與我們一起進行數據倉庫工作負載。而這些可能是工作負載,否則會去Snowflake的。"
數據倉庫供應商正在逐步從現有的模式轉向數據倉庫和數據湖模式的融合。同樣地,那些在數據湖邊開始他們的旅程的供應商現在也在向數據倉庫領域擴展。我們可以看到兩方面的融合都在發生。
因此,正如Databricks使其數據湖看起來更像數據倉庫一樣,Snowflake一直在使其數據倉庫看起來更像數據湖。簡而言之,數據湖倉是一個平臺,旨在結合數據倉庫和數據湖的優點。根據營銷術語,數據湖室結合了數據倉庫和數據湖的優點,為數據科學和分析用例提供融合的工作負載。Databricks在其營銷資料中利用了這個術語,而Snowflake則更喜歡數據云這個術語。
但是,數據湖倉是否意味著數據倉庫的終結?數據湖倉是一個新的、開放的數據管理架構,它將數據湖的靈活性、成本效益和規模與數據倉庫的數據管理和ACID交易結合起來,使所有數據的商業智能和ML成為可能。
那是在2012年,專家們在 Strata-Hadoop World聲稱數據湖將殺死數據倉庫(創業公司當時拒絕了SQL并使用了Hadoop--SQL在當時有點遜色,其原因在今天看來是荒謬的)。這種死亡從未發生過。
在2022年,較新的概念與云計算和融合工作負載的技術創新相搭配,是否會廢止數據倉庫?
時間會證明一切,但這個領域正在升溫,我們預計2022年將有更多的公開對決。該領域的其他初創企業,如Firebolt、Dremio和Clickhouse最近都進行了大量融資,將估值推至10億美元以上。
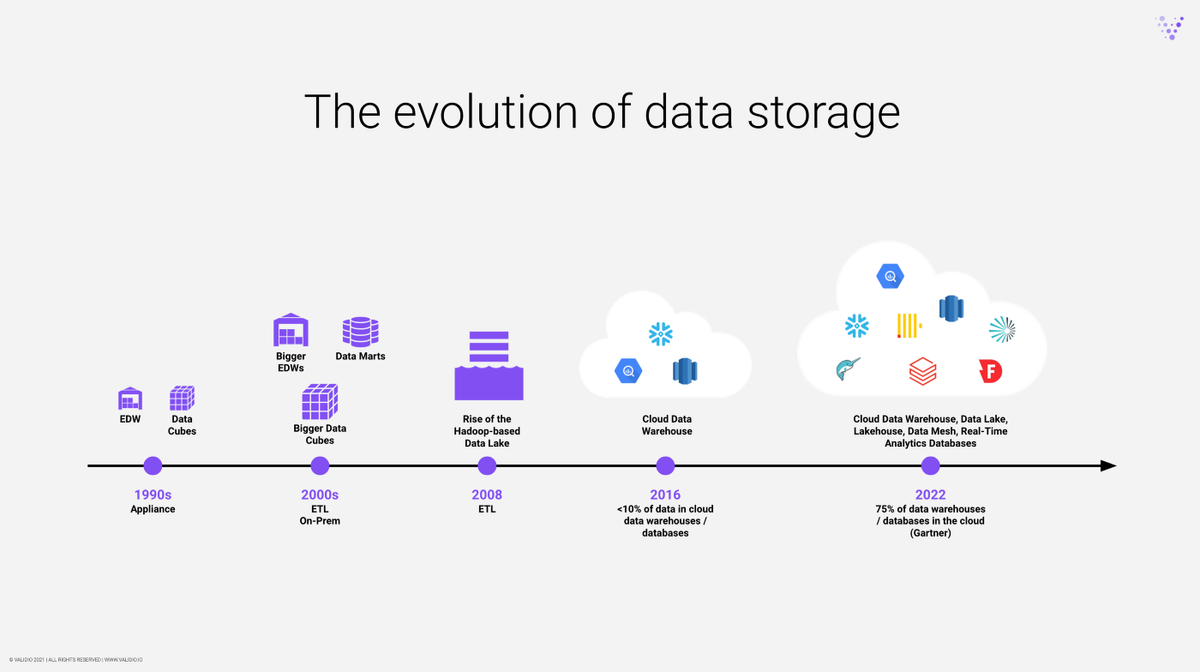
數據存儲和倉庫的演變
正如阿里-高德西所言,這不會是一個贏家通吃的市場。
"我認為Snowflake將非常成功,我認為Databricks將非常成功......你還會看到其他的頂級公司出現,我肯定,在未來三到四年內。這只是一個巨大的市場,很多人專注于追求它是有道理的。"
根據 Bill Inmon他一直被認為是數據倉庫之父,數據湖庫提供了一個類似于數據倉庫市場早期的機會。數據湖庫可以 "將數據湖的數據科學重點與數據倉庫的分析能力相結合。"
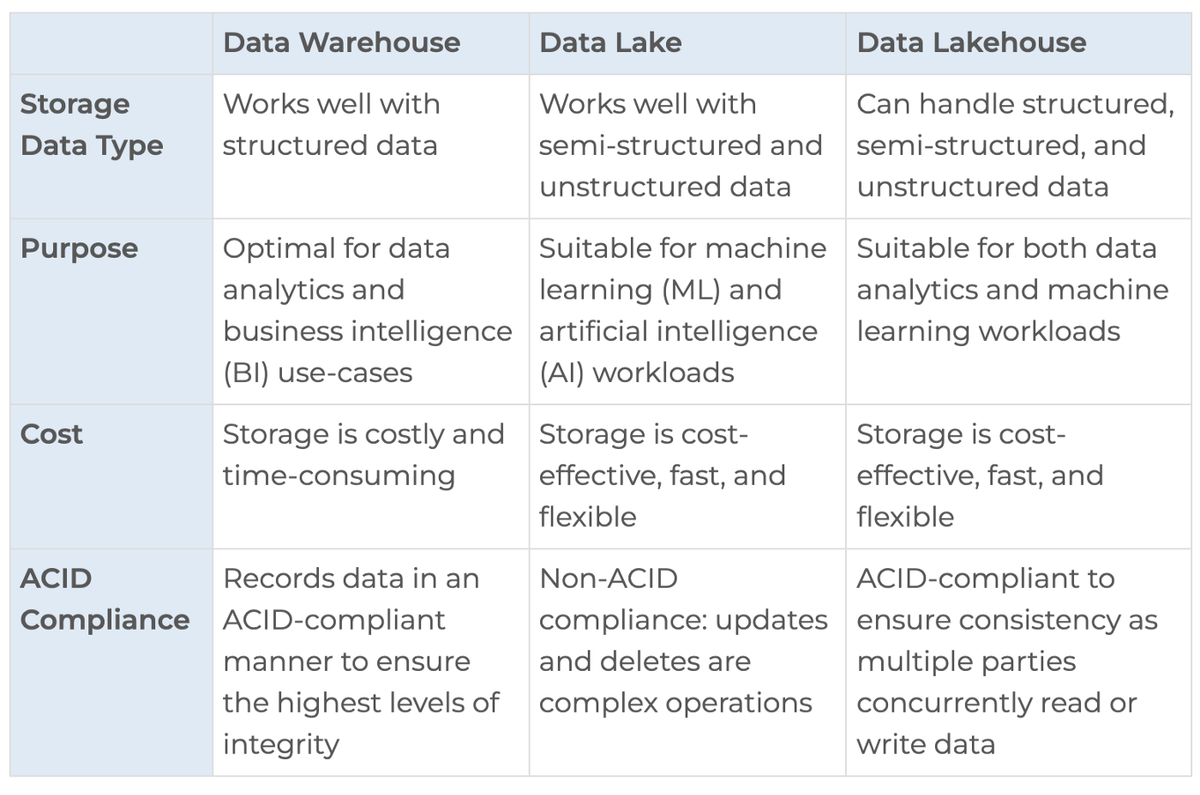
數據倉庫VS數據湖VS數據湖館 by Striim
數據湖倉與數據倉庫(與數據湖)仍然是一個正在進行的辯論。數據架構的選擇最終自然應取決于團隊所處理的數據類型、數據來源以及利益相關者將如何使用這些數據。
隨著2022年數據倉庫與數據湖倉的爭論加劇,重要的是要把炒作和營銷術語與現實分開。
3.實時流管道和運營分析將繼續推動
正如Matt Turck在他的 MAD Landscape 2021 analysis,感覺實時性一直是一個技術范式,一直是剛要爆發的。當我們進入2022年時,我們聽到的權衡似乎還是在成本和復雜性方面。如果一個公司正在建立一個云數據倉庫,并且需要立即產生4-6周的影響,那么總體概念似乎仍然是,這是一個實時流管線與批處理管線相比。或者說,如果公司處于數據旅程的開始階段,那就是純粹的矯枉過正。
在Validio,我們預計隨著實時領域技術的不斷成熟和云主機的不斷發展,這種觀念將在未來幾年內發生改變。許多使用案例,如欺詐檢測和動態定價,如果不進行實時處理,就很難獲得價值。
隨著云服務提供商不斷改進其流媒體工具,以數據為主導的組織正朝著建立大規模流媒體平臺的方向發展。這也是Ali Ghodsi所暗示的一個概念。
"如果你沒有一個實時的流處理系統,你必須處理這樣的事情,好吧,那么數據每天都會到達。我要把它放在這里。我要把它加到那邊去。那么,我如何進行核對?如果有些數據晚了怎么辦?我需要連接兩個表,但那個表不在這里。所以,也許我會等一下,然后再重新運行一次。" - Ali Ghodsi on a16z
在過去的10年里,Apache Kafka一直是一個堅實的流引擎。進入2022年,我們看到公司越來越多地轉向云托管的引擎,如亞馬遜的Kinesis和谷歌的Pub/Sub。
僵尸儀表盤是一個非常具體的例子,說明為什么這種流/實時運動正在逐漸發生。在現代數據驅動的公司中,它們似乎成了一個非常真實的東西,Ananath Packkildurai(《數據工程周刊》的創始人)在以下文章中討論了這個問題 this Twitter thread.
對于許多公司來說,運營分析是開始他們走向實時/近實時分析的一個良好起點。正如Kleiner Perkins的合伙人Bucky Moore在他最近的文章中討論的那樣 blog post:
"云數據倉庫的設計是為了支持商業智能用例,這相當于掃描整個表并匯總結果的大型查詢。這是對歷史數據分析的理想選擇,但對于 "現在發生了什么?"這類查詢正變得越來越流行,以推動實時決策。這就是運營分析指的是什么。這方面的例子包括應用內的個性化、流失預測、庫存預測和欺詐檢測。相對于商業智能,運營分析查詢將許多不同的數據源連接在一起,需要實時數據攝取和查詢性能,并且必須能夠同時處理許多查詢。"
由于 noted by McKinsey back in 2020,實時數據信息傳遞和流媒體管道的成本已經大幅下降,為主流使用鋪平了道路。麥肯錫在一篇文章中進一步預測 recent article到2025年,數據的生成、處理、分析和終端用戶的可視化將被新的和更普遍的技術大大改變,例如用于實時分析的Kappa或lambda架構,導致更快和更強大的洞察力。他們認為,隨著云計算成本的不斷下降和更多強大的 "內存 "數據工具的上線(如Redis、Memcached),即使是最復雜的高級分析也能合理地提供給所有組織。
不能客觀地說,在我們進入2022年后,流數據是否比批處理數據變得更加關鍵--因為這在不同的公司和用例之間存在巨大的差異。例如,Chris Riccomini設計了一個數據管道進展的層次結構。他認為,數據驅動的組織在他們的管道成熟度中會經歷這樣的演變序列。

數據管道成熟度的六個階段 Chris Riccomini
我們不做任何預測,上述管道的成熟度進展是否會變得更加普遍--有人認為實時流管道幾乎都是矯枉過正的。
然而,我們看到,越來越多的公司正在投資實時基礎設施,因為他們正在從數據驅動(根據歷史數據做出決策)變成數據主導(根據實時和歷史數據做出決策)。這一趨勢的良好指標是Confluent的爆炸性IPO和新產品,如Clickhouse、Materialize和Apache Hudi,它們在數據湖上提供實時功能。
數據的及時性,例如從這種基于批量的周期性架構到更實時的架構,將成為一個越來越重要的競爭要素,因為每一個現代公司都在成為一個數據公司。我們預計這將在2022年進一步加速。
4.現代數據棧采用的云市場的崛起
在數據基礎設施領域,PLG(產品主導型增長)趨勢已經持續了幾年,因為基于使用的定價、開源和軟件的可負擔性已經將購買決策推向了終端用戶。然而,與傳統的銷售主導的市場模式相比,從商業模式和產品的角度來看,產品主導的增長和基于使用的定價在軟件方面的實施和執行可能很復雜。通過AWS、GCP和Azure的云市場平臺正在成為企業向未來數字銷售發展的最佳第一步。
隨著開發者工具公司--包括現代數據棧中的初創公司--部署不同級別的PLG動議(產品的免費/免費/免費試用版)或多或少成為一種規范,我們也在經歷云市場的崛起,成為現代數據團隊采用新技術渠道的首選。這主要是由于它們所提供的類似于消費者的無摩擦購買體驗(想想蘋果應用商店或谷歌游戲商店),而且數據團隊可以利用他們已經承諾的云供應商的支出,通過云市場采用新技術。
對于全球領先的云計算公司來說,云市場現在是進入市場的必要條件,而不是選擇。這些數字--包括已實現的和預測的--說明了原因。
- 超過45%的 Forbes The Cloud 100公司積極使用云市場作為其軟件的分銷渠道。
- 流經三大云計算供應商的企業承諾支出 exceeds $250 billion per year- 而這個數字正在快速攀升。
- 僅在2021年,獨立軟件供應商通過云市場平臺 產生了超過30億美元的收入,根據 Bessemer predictions. 貝瑟默公司預計,在未來幾年,這一數字將以10的倍數增長。
- Forrester had projected到2023年,全球13萬億美元的B2B支出中有17%將通過電子商務和市場平臺流動 - 但這個數字可能在2021年就已經達到了。
- A 2020 Tackle survey發現,70%的軟件供應商表示,由于COVID-19的出現,他們已經增加了對市場平臺的關注和投資,將其作為進入市場的渠道。
云市場的爆炸性增長主要源于它們為現代數據團隊和數據基礎設施技術供應商提供的相互優勢。

云市場的雙贏
最近發表的一項研究 by Gartner預測,到2025年,近80%的銷售互動將通過數字渠道進行。通過GCP、AWS或Azure云市場分發技術正成為現代數據團隊的自然入口。現代數據棧公司,如 Astronomer and Fivetran已經通過成為云市場的早期采用者而獲得了成功。其他早期采用云市場的公司,如CrowdStrike,已經看到銷售周期時間減少了近50%。
購買行為已經徹底改變,現代數據團隊在他們的商業生活中期待著消費者級別的體驗。他們希望以一種非常低調、技術領先的方式來發現、試用、甚至購買新的數據基礎設施技術。云市場正在成為這些團隊探索新技術的接入點,就像蘋果應用商店和谷歌游戲商店成為我們所有人探索新的日常服務和娛樂的接入點。
提供現代數據基礎設施工具的初創企業可以從我們的消費者生活中學習到明顯的模式和經驗,以消除摩擦,更有效地擴大銷售,并幫助數據團隊更快地獲得價值。
我們預計,在2022年,云市場將成為現代數據團隊采用現代數據棧技術的首選方式。由于云和新基礎設施的爆炸性增長,圍繞現代數據棧的概念已經出現了很多,因此,云市場將成為自然的切入點,這讓人感覺很合理。
5.圍繞現代數據棧和數據質量的術語的統一和一致
看到現代數據棧背景下的數據質量空間從2020年的小眾類別到過去18個月內完全爆發,2021年共有2億美元的資金流入該空間,這是非常不可思議的。甚至G2在他們最近的"What Is Happening in the Data Ecosystem in 2022"的文章中指出,2022年將是數據質量的天下,他們在2021年看到數據質量類別的流量急劇增加,這是一個不尋常的趨勢。
在現代云數據基礎設施的背景下,數據質量類別的崛起是非常有意義的。數據質量不僅是任何現代數據驅動型公司的基礎(無論它是普通的報告、商業智能、運營分析還是高級機器學習),根據 2022 State of Data Engineering Survey數據質量和驗證是調查對象(主要是數據工程師)提到的第一大挑戰。27%的調查對象不確定他們的組織使用什么(如果有的話)數據質量解決方案。對于DataOps成熟度低的組織,這一數字躍升至39%。
然而,數據質量技術的爆炸性增長也帶來了一些負面的影響。隨著現代數據質量工具的快速爆炸性增長,我們也可以看到該領域的術語有很多不一致和重疊的用法。正如作者所指出的 Bessemer在數據質量領域的參與者已經創造了一些借用應用性能監控的術語,如 "數據停機"(對 "應用停機 "的戲稱)和 "數據可靠性工程"(對 "站點可靠性工程 "的戲稱)。
現在有無數種方法來描述重要但有點龐雜的過程,可以被定義為數據質量驗證和監測。我們看到諸如數據可觀察性、數據可靠性、數據可靠性工程、數據質量監控、數據的Datadog、實時數據質量監控、數據停機、未知數據故障、無聲數據故障等術語被交替使用且不一致。
在目前的狀態下,現代數據棧中的大多數數據質量工具都集中在監控管道元數據或對倉庫中的靜態數據進行SQL查詢--有些工具與不同層次的數據脈絡或根本原因分析相聯系。
一個現在被定義為數據可觀察性工具的軟件可能只關注數據線,或者只關注監測管道元數據。一個提供實時數據質量警報但不支持監測實時流管道的工具,現在可能被定義為一個實時數據質量監測工具。一個只對倉庫中的數據進行SQL查詢的工具可能被定義為端到端的數據可靠性工具,而一個監控管道元數據的工具可能被定義為數據質量監控工具(反之亦然)。這個名單還在繼續。現在有很多不一致的地方,導致市場和終端用戶的混亂。
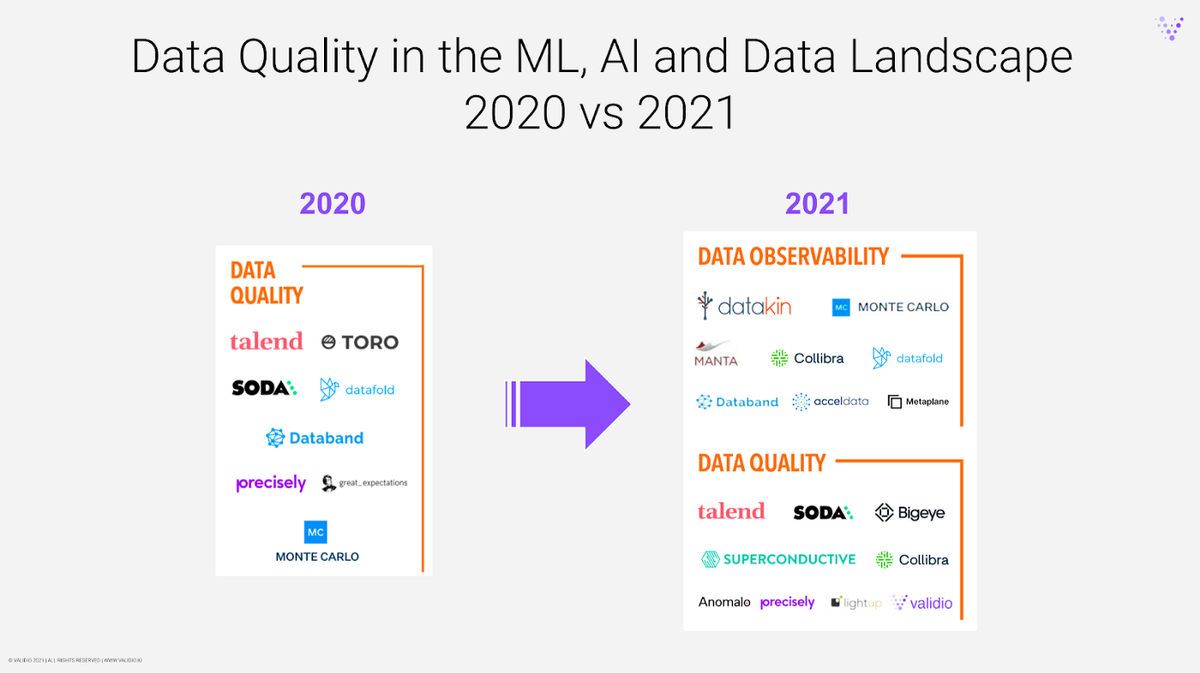
2020年MAD格局中的數據質量類別與2021年的格局相比,由 Matt Turck
術語的不一致性是超出數據質量范疇,擴展到整個現代數據棧的東西。
一個行業的早期最有力的指標之一是新術語的擴散,而這些術語的使用是不一致的。作為一個具體的例子,當有人說電子商務平臺或CMS平臺時,我們大多數人都會想到例如Shopify或WordPress,并對該工具在業務中的功能有一個清晰的認識。但是,當你聽到 "運營分析"、"數據湖 "或 "數據可觀察性 "這樣的術語時,一個在數據世界工作的人可能會發現很難說清楚它們的確切含義和/或包含的內容。這往往與以下事實直接相關,即許多術語是由一些公司創造的,它們利用特定的技術開辟了新的領域,并進行了分類創造。有趣的是,即使是最熱門的數據術語,例如 "現代數據棧",在數據世界中也缺乏一個一致的定義--此外,諸如 "數據網 "和 "數據結構 "等術語也經常被用來描述新的數據架構。
隨著實際用戶將該技術分層到他們的堆棧并建立用例,該行業將最終幫助形成特定工具和架構模式的定義。
在2022年,隨著現代數據棧和數據質量類別的成熟,我們也希望看到術語使用方式的協調和一致。
綜上所述
我們相信,我們仍然處于現代數據棧革命的早期階段。正如云計算改變了我們今天的工作方式一樣,通過現代云原生基礎設施來駕馭數據,對各種規模和行業的公司來說都是至關重要的。此外,隨著現代數據棧被更廣泛地采用,我們預計將看到許多需要進一步加強的領域,包括流式數據,使公司能夠采取實時行動。
如果說軟件一直在吞噬世界,那么數據就是機器的燃料。近十年來,Airbnb、Netflix、Uber和其他大公司都在其數據棧上進行了大量投資,不僅為個性化的內容提供服務,而且還幫助進行動態和自動化決策。隨著現代數據棧的興起,任何公司無論大小都可以以靈活和非成本高昂的方式存儲和利用大量的數據,而不需要一支技術人員的軍隊。
現代云數據基礎設施正在進行大規模建設,未來將由數據的可訪問性、使用和質量來定義。
我們對2022年所帶來的一切感到無比興奮。

























