Ceph存儲節點系統盤損壞集群恢復

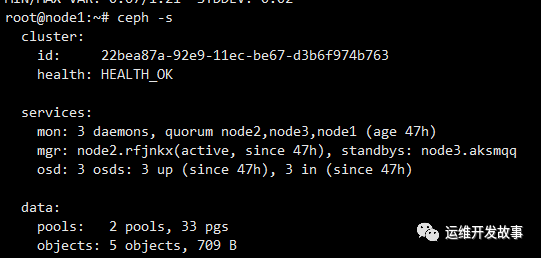
本文主要介紹ceph16版本集群節點系統磁盤故障后的集群恢復,雖然系統盤很多都是做了raid1,但從實際做的項目看,總是有很多未知意外發生,節點掛掉后,上面的mon和osd,mgr都會down掉,如果所在節點的mgr服務是激活狀態,則其他節點所在的備用節點將會升級為激活狀態。
移除問題主機
節點掛掉后,在確定不能繼續開機進入系統的情況下,需要在其他正常的節點將故障節點進行移除,此次宕機的節點為node4,以下命令可能會導致數據丟失,因為 osd 將通過調用每個 osd 來強制從集群中清除。
ceph orch host rm node4 --offline --force
節點初始化操作
將node4節點即故障節點更換新的系統盤并重新安裝系統,重裝后node4主機名我修改成了node1,并更換了新的ip,在三臺ceph節點上重新添加hosts解析
192.168.1.1 node1
192.168.1.2 node2
192.168.1.3 node3
將公鑰添加至新主機。
ssh-copy-id -f -i /etc/ceph/ceph.pub node1
安裝docker環境。
curl -sSL https://get.daocloud.io/docker | sh
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
安裝cephadm以及ceph-common。
# curl --silent --remote-name --location https://github.com/ceph/ceph/raw/pacific/src/cephadm/cephadm
# chmod +x cephadm
# ./cephadm add-repo --release pacific
# ./cephadm install
# ./cephadm install ceph-common
向集群中添加新節點
在ceph集群添加新主機。
[root@node2 ~]# ceph orch host add node1
Added host 'node1'
添加后的主機列表可通過以下命令查看。
ceph orch host ls
之后會自動安裝mon以及crash等服務,還有node-exporter監控agent,但是新添加的節點上還不能進行ceph集群操作,因為新添加的節點上缺少ceph集群管理的密鑰環,在上面的命令中其實可以看到新加的node1是缺少一個_admin標簽的,這里提一下ceph是有幾個特殊的主機標簽的,以_開頭的屬于ceph主機的特殊標簽,將_admin標簽添加到這臺新節點,就會導致cephadm 將配置文件ceph.conf和密鑰環文件ceph.client.admin.keyring分發到新節點上,這里我們把_admin標簽添加至新節點,這樣可以在新節點上執行ceph集群的操作。
ceph orch host label add node1 _admin
或者在添加節點時就可以把標簽添加上
ceph orch host add node1 --labels=_admin
添加osd
之前想著原有的故障節點的osd直接恢復到現有集群上,后來發現雖然是恢復回去了,但是osd的daemon沒有被cephadm所管理,osd的容器也沒有被創建,因此還是把原來故障節點的osd給格式化了,重新添加的osd,不過這里還是把我恢復的操作寫一下吧。先創建一個空的osd。
# vceph osd create
2
然后激活bluestore-osd的tmpfs目錄 由于bluestore中osd的目錄是以一個tmpfs的形式存在的,所以被umount掉了以后需要重新激活。
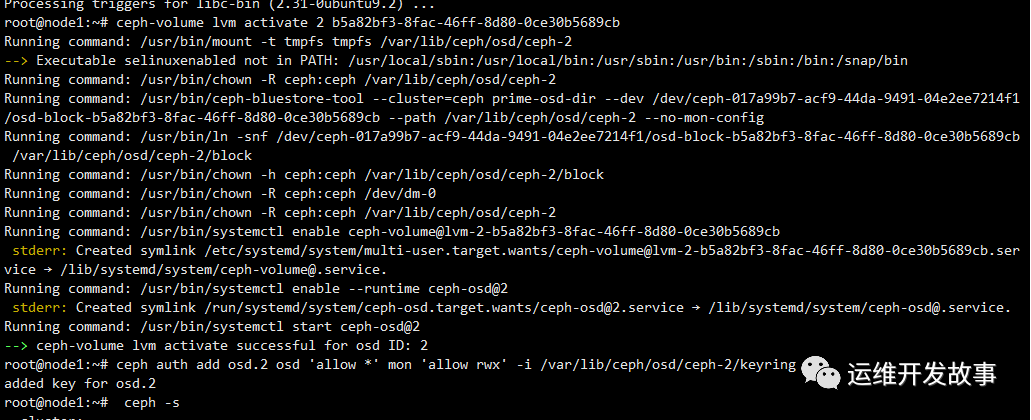
ceph-volume lvm activate (osdid) (fsid)
- PS:這里的osdid就是我剛創建的,osdid為2,后面的fsid不是集群的fsid,而是這個osd自己的fsid,獲取方式可以直接執行ll /dev/ceph*查看,osd-block-后面的即為osd的fsid。
然后添加auth和crush map,重啟osd。
ceph auth add osd.2 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-2/keyring
 之后三個osd都會up,但是存在osd的daemon不被cephadm管理的問題,因此我還是刪掉這個osd,重新格式化后添加的,刪除osd的操作如下:
之后三個osd都會up,但是存在osd的daemon不被cephadm管理的問題,因此我還是刪掉這個osd,重新格式化后添加的,刪除osd的操作如下:
ceph orch ps --daemon_type osd
#查看osd對應的容器id,先停止容器,我這里沒有osd容器啟動,所以這步可以忽略
ceph osd out 2
ceph osd crush remove osd.2
ceph auth del osd.2
ceph osd rm 2
上步只是在ceph刪除,還需要在磁盤上進行格式化。
# 顯示當前設備的狀態
# dmsetup status
# 刪除所有映射關系
# dmsetup remove_all
# 格式化剛才刪除的osd所在磁盤
mkfs -t ext4 /dev/vdb
重新添加osd。
ceph orch daemon add osd node1:/dev/vdb
此時集群就恢復正常了。