數據湖三劍客,大數據時代的新范式?
隨著互聯網高速發展,大數據技術快速發展和迅速迭代,降低了用戶處理海量數據的門檻,越來越多的應運場景出現在我們的身邊存儲和處理需求越來越多樣化,逐漸呈現出數據倉庫往數據湖方向發展、批處理往流式處理發展、本地部署往云模式發展的趨勢。
但在技術發展層面,逐漸出現了諸多的掣肘,不斷有新的問題出現,僅僅就存儲方面來講,與數據庫這樣高度優化的技術相比,大數據技術的抽象和實現還是太原始和初級。
目前的數據倉庫技術出現了一定的局限性,比如單一不變的 schema 和模型已經無法滿足各類不同場景和領域的數據分析的要求、流批一體的數據存儲引擎和計算引擎適配問題以及Hadoop體系文件系統的ACID能力缺失等問題急需要解決,但就目前的技術棧而言,打破這些技術的桎梏,似乎多少有些力不從心,這個過程中,一項重大變革似乎在破曉前顯得尤為必要。
在不停地探索和思考中,大數據人開始慢慢醒悟,回頭看向成名已久的數據庫,將更多數據庫的成熟技術和理念借鑒到大數據中,似乎是一條高效又穩健的道路。至此,數據湖技術應運而生,在諸多方面向數據庫看齊,你可以說是學習,當然,也可以說是致敬,是業界針對這些問題的一種解決方案。
那么,什么是數據湖技術呢?
計算引擎之下、數據存儲之上,處于中間層的數據湖。
簡單地說,這類新技術是介于上層計算引擎和底層存儲格式之間的一個中間層,我們可以把它定義成一種“數據組織格式”。其最核心的點便是將事務能力帶到了大數據領域,并抽象成統一的中間格式供不同引擎適配對接。
為此,Uber開源了Apache Hudi,Databricks提出了Delta Lake,而 Netflix 則發起了 Apache Iceberg 項目,一時間這種具備 ACID 能力的表格式中間件成為了大數據、數據湖領域炙手可熱的方向。
Iceberg 將其稱之為“表格式”也是表達類似的含義。它與底層的存儲格式(比如 ORC、Parquet 之類的列式存儲格式)最大的區別是,它并不定義數據存儲方式,而是定義了數據、元數據的組織方式,向上提供統一的“表”的語義。它構建在數據存儲格式之上,其底層的數據存儲仍然使用 Parquet、ORC 等進行存儲。
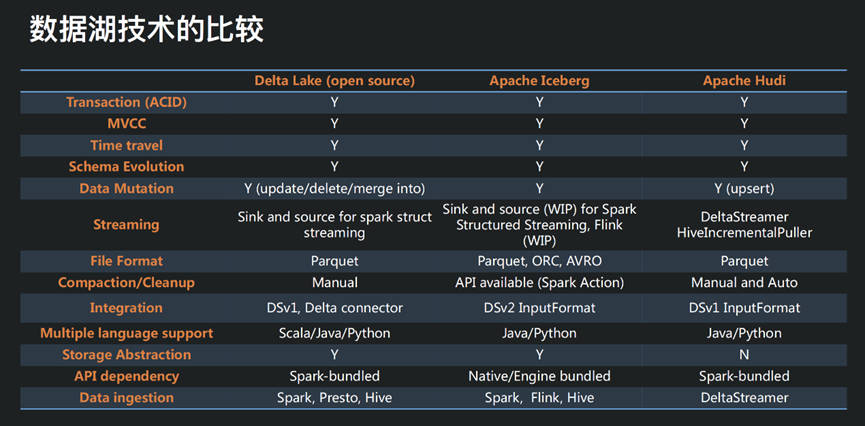
Apache Iceberg、Hudi 和 Delta Lake 誕生于不同公司,需要解決的問題存在差異,因此三者在設計初衷上稍有不同。
其中,Iceberg 的設計初衷更傾向于定義一個標準、開放且通用的數據組織格式,同時屏蔽底層數據存儲格式上的差異,向上提供統一的操作 API,使得不同的引擎可以通過其提供的 API 接入;Hudi 的設計初衷更像是為了解決流式數據的快速落地,并能夠通過 upsert 語義進行延遲數據修正;Delta Lake 作為 Databricks 開源的項目,更側重于在 Spark 層面上解決 Parquet、ORC 等存儲格式的固有問題,并帶來更多的能力提升。
雖然這三個項目在設計初衷上稍有不同,但實現的思路和提供的能力卻非常相似,他們都提供了 ACID 的能力,都基于樂觀鎖實現了沖突解決和提供線性一致性,同時相應地提供了 time travel 的功能。
但是因為設計初衷的不同,三個項目當前的能力象限各有不同,Iceberg 在其格式定義和核心能力上最為完善,但是上游引擎的適配上稍顯不足;Hudi 基于 Spark 打造了完整的流式數據落地方案,但是其核心抽象較弱,與 Spark 耦合較緊;Delta Lake 同樣高度依賴于 Spark 生態圈,與其他引擎的適配尚需時日。
那么,當下數據湖技術呈現的三足鼎立的技術場面,優劣點如何看待,技術選型如何去做,當然是我們最關心的問題,下文逐步解析。
Delta Lake,spark生態圈急先鋒
傳統的 lambda 架構需要同時維護批處理和流處理兩套系統,資源消耗大,維護復雜。
基于 Hive 的數倉或者傳統的文件存儲格式(比如 parquet / ORC),都存在一些難以解決的問題:小文件問題、并發讀寫問題、有限的更新支持及海量元數據(例如分區)導致 metastore 不堪重負問題等。
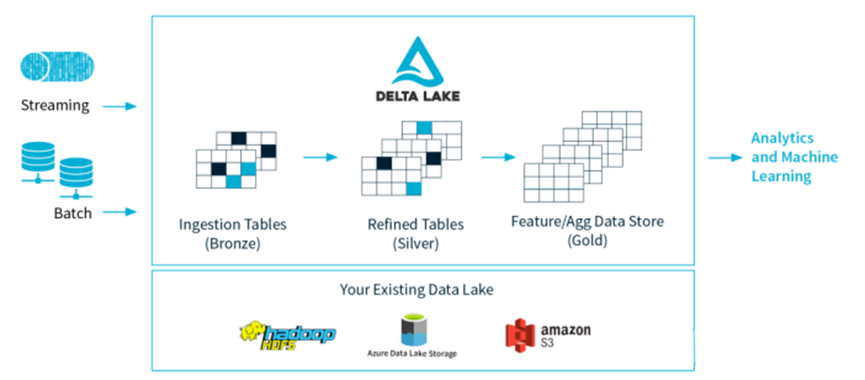
如上圖,Delta Lake 是 Spark 計算框架和存儲系統之間帶有 Schema 信息的存儲中間層。
它集中解決了傳統hive數倉的諸多問題,使得實時數據湖變得優雅又絲滑,不見了天生的慵懶,只看到輕盈又婀娜的身姿。重要變化如下:
- 設計了基于 HDFS 存儲的元數據系統,解決 metastore 不堪重負的問題;
- 支持更多種類的更新模式,比如 Merge / Update / Delete 等操作,配合流式寫入或者讀取的支持,讓實時數據湖變得水到渠成;
- 流批操作可以共享同一張表;
- 版本概念,可以隨時回溯,避免因為一次誤操作或者代碼邏輯而無法恢復的災難性后果。
基于Parquet的列式存儲層,在多并發寫入之間提供 ACID 事務保證。每次寫入都是一個事務,并且在事務日志中記錄了寫入的序列順序。
但是,Delta Lake定位于spark流批一體的數據處理工具,地主家的公子,自己家的事情如數家珍,輕松搞定,但走出家門后,難免會有些水土不服。
Apache Hudi,有天生缺陷的優等生
Apache Hudi 代表 Hadoop Upserts and Incrementals,能夠使HDFS數據集在分鐘級的時延內支持變更,也支持下游系統對這個數據集的增量處理。
Hudi數據集通過自定義的inputFormat 兼容當前 Hadoop 生態系統,包括 Apache Hive,Apache Parquet,Presto 和 Apache Spark,使得終端用戶可以無縫的對接。
如下圖,基于 Hudi 簡化的服務架構,分鐘級延遲。
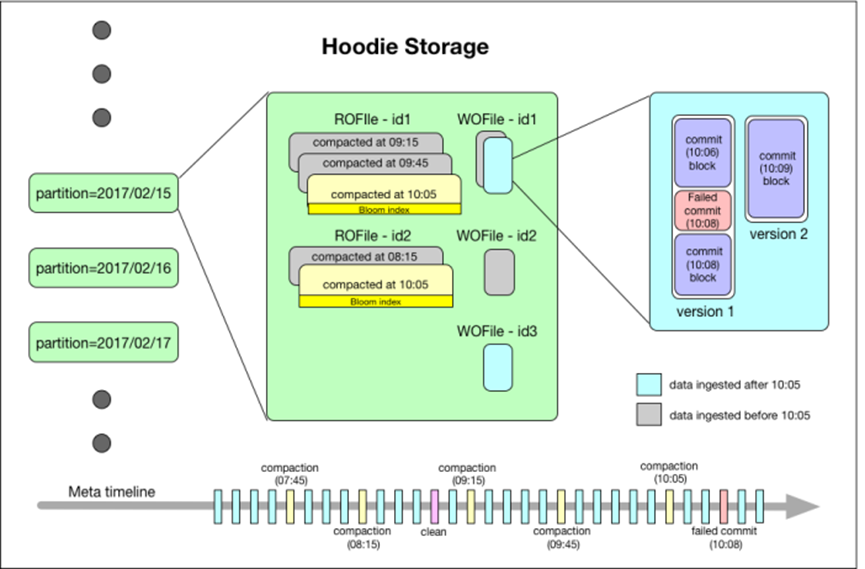
Hudi 會維護一個時間軸,在每次執行操作時(如寫入、刪除、合并等),均會帶有一個時間戳。
通過時間軸,可以實現在僅查詢某個時間點之后成功提交的數據,或是僅查詢某個時間點之前的數據。
這樣可以避免掃描更大的時間范圍,并非常高效地只消費更改過的文件(例如在某個時間點提交了更改操作后,僅 query 某個時間點之前的數據,則仍可以 query 修改前的數據)。
如上圖的左邊,Hudi 將數據集組織到與 Hive 表非常相似的基本路徑下的目錄結構中。
數據集分為多個分區,每個分區均由相對于基本路徑的分區路徑唯一標識。
如上圖的中間部分,Hudi 以兩種不同的存儲格式存儲所有攝取的數據。
讀優化的列存格式(ROFormat):僅使用列式文件(parquet)存儲數據。在寫入/更新數據時,直接同步合并原文件,生成新版本的基文件(需要重寫整個列數據文件,即使只有一個字節的新數據被提交)。此存儲類型下,寫入數據非常昂貴,而讀取的成本沒有增加,所以適合頻繁讀的工作負載,因為數據集的最新版本在列式文件中始終可用,以進行高效的查詢。
寫優化的行存格式(WOFormat):使用列式(parquet)與行式(avro)文件組合,進行數據存儲。在更新記錄時,更新到增量文件中(avro),然后進行異步(或同步)的compaction,創建列式文件(parquet)的新版本。此存儲類型適合頻繁寫的工作負載,因為新記錄是以appending 的模式寫入增量文件中。但是在讀取數據集時,需要將增量文件與舊文件進行合并,生成列式文件。
Apache Iceberg,基礎扎實,后生可畏
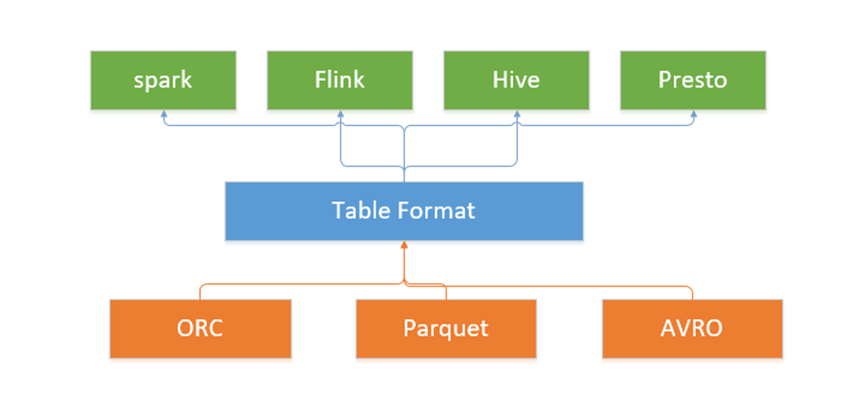
Iceberg 作為新興的數據湖框架之一,開創性地抽象出“表格式”table format)這一中間層,既獨立于上層的計算引擎(如Spark和Flink)和查詢引擎(如Hive和Presto),也和下層的文件格式(如Parquet,ORC和Avro)相互解耦。
此外 Iceberg 還提供了許多額外的能力:
- ACID事務;
- 時間旅行(time travel),以訪問之前版本的數據;
- 完備的自定義類型、分區方式和操作的抽象;
- 列和分區方式可以進化,而且進化對用戶無感,即無需重新組織或變更數據文件;
- 隱式分區,使SQL不用針對分區方式特殊優化;
- 面向云存儲的優化等;
Iceberg的架構和實現并未綁定于某一特定引擎,它實現了通用的數據組織格式,利用此格式可以方便地與不同引擎(如Flink、Hive、Spark)對接。
所以 Iceberg 的架構更加的優雅,對于數據格式、類型系統有完備的定義和可進化的設計。
綜合而言,三個引擎的初衷場景并不完全相同,Hudi 為了 incremental 的 upserts,相對而言最為成熟,但底層架構設計較差,擴展性及生態延續方面難度較大;Iceberg 定位于高性能的分析與可靠的數據管理,底層架構的抽象及架構的開放性方面做的很好,數據湖upsert和compaction兩個關鍵的功能也趨于完善,正在快速發展期;Delta 定位于流批一體的數據處理,無縫對接Spark生態。
我們在技術選型的時候,不僅要知到要到哪里去,更要明確我們從哪里來,選擇適合自己當下業務需求的技術,才能更快速、更高效輔助業務開發。