一篇帶你了解一下CQRS模式

背景問題
簡單的需求
當我們系統中的數據模型層級較少時,數據模型足夠簡單時,模型與數據庫可以直接進行映射。這種簡單數據模型使我們不需要針對其相互關系進行復雜的建模設計,直接在工程中使用經典的三層模型就足以支撐項目需求。
對于這種簡單系統,過度設計會增加后續維護、重構的成本(并不能保證預設計能完美符合后續需求)。同時,對于簡單系統,我們大部分的需求都只涉及其中的少量數據模型邏輯處理。
而我們直接對數據模型進行CURD就能滿足需求,進而的結論就是:
針對簡單需求,我們不需要特別區別查詢和增刪改的程序結構。
復雜的需求
如果我們的系統具有一定復雜性,這種復雜性可能是源于訪問頻次、數據量或者是數據模型數量。這時候我們遇到的問題是數據在查詢和更新的需求差距逐漸變大。
- 頻次:數據的查詢頻次會遠高于新增、更新、刪除頻次。
- 數據量:數據量變大后會增加對數據進行分庫分表的設計訴求,從而導致數據查詢變得的復雜性(涉及分表關鍵字)。
- 數據模型數量:數據模型數量的增大,會導致在進行新增、更新與刪除操作時同時影響的數據模型變多,而在查詢時同時跨多模型的查詢條件會讓查詢的性能具有極大的挑戰性。
根據以上舉例我們可以發現,當我們的需求具有一定的復雜性后,根據引入復雜性的不同,會導致系統功能上需要用更加復雜的設計來對需求的復雜性進行支撐。同時我們也可以發現,引入的不同復雜性在增刪改和查詢方面的帶來的功能需求差別很大。
所以:
需求的復雜性會放大程序中查詢和增刪改的設計差異。
DDD的需求
如果我們對系統整體的構建與設計有了更高的可維護性與可擴展性要求,以至于我們需要使用DDD來設計整個系統。
在這種情況下往往模型中具有相對復雜的模型關系,在增刪改時我們需要將所有請求封裝為領域對象,以便程序可以基于領域模型完成大量復雜的校驗、業務邏輯。而在查詢需求時,我們常常需要組織跨領域數據來完成一個列表中數據內容的展示。所以:
在DDD設計中,增刪改操作便于應用領域模型執行,而查詢操作往往無法直接通過領域模型執行。
CQRS模式
問題的抽象
根據第一節中的內容我們可以發現,在進行系統架構設計時,當系統出現復雜性后存在一個核心問題:
增刪改類型的功能與查詢類型的功能,在功能需求上具有較大的差異。
這種差異帶來的直接結果就是在系統開發的過程中,針對增刪改和查詢操作的業務設計上差異會比較大。如果舉幾個例子來說的話,比如:
- 針對增刪改系統我們需要事務來保證多領域模型的更新原子性;針對查詢我們需要增加緩存來提高熱點數據的查詢性能。
- 數據讀取和寫入的模型通常是不匹配的,他們維護和查詢的列或者屬性坑沒有交集。
- 在更新的時候查詢數據可能會產生沖突。
- 使用統一模型進行存儲可能會導致復雜查詢時的性能降低。
CQRS本質
由于存在增刪改與查詢邏輯有差異的這個問題,為了更好的針對差異進行抽象,我們可以將它們分開進行設計。也就是我們的CQRS模式,即命令查詢的責任分離Command Query Responsibility Segregation模式。其中我們稱增刪改為命令型操作。
CQRS本質上是一種讀寫分離設計思想,這種框架設計模式將命令型業務和查詢型業務分開單獨處理。通過這種方式,CQRS可以針對命令和查詢單獨進行業務模型上的設計,從而用更加適合各自場景的方案與組件來提供能力。
查詢
查詢操作并不會修改數據庫中的內容,所以查詢本身是一種冪等操作,以同一個查詢條件在系統不改變的情況下反復執行會返回相同的結果,我們可以針對這種特性提供數據緩存來提高系統性能;同時因為不影響數據庫,查詢邏輯是不會產生數據一致性問題。查詢往往會存在較高的使用頻率。
命令操作會直接修改數據庫,并針對多個領域模型的情況下我們需要增加來保證操作的原子性。而對于一個命令操作,我們往往是不直接依賴命令的返回值的,所以通常可以異步執行命令操作。對于一般系統來說,往往命令操作的使用頻次會較低。
簡單實用
由于CQRS的本質是對于讀寫操作的分離,所以比較簡單的CQRS的做法是:
CQ兩端數據庫表共享,CQ兩端只是在上層代碼上分離。
這種做法在不對數據庫進行分離設計的情況下,CQ兩端在上層代碼進行分離個字單獨維護,例如命令型的都用xxxManagerController、xxxManagerService來定義,而查詢則直接用xxxController、xxxService定義。
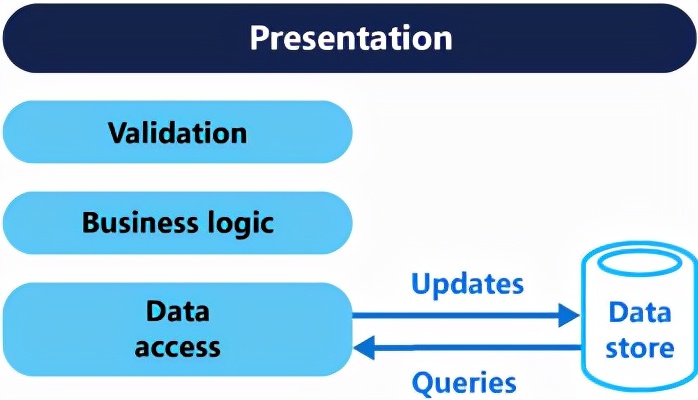
因為使用同一個數據庫,所以沒有CQ兩端的數據一致性問題。但因為已經對上層代碼進行了抽離,所以可以滿足一些設計特性如:
- 命令應基于任務,而不是以數據為中心。
- 命令可以放置在隊列上進行異步處理,而不是同步處理。
- 查詢從不修改數據庫。 查詢返回的 DTO 不封裝任何域知識。
這種方案可以滿足代碼邏輯上的分離維護,但由于是使用同一數據庫表,所以無法根據CQ兩種業務的特點單獨進行模型設計。
關注性能
在代碼分離的基礎上,我們可以再將數據存儲的模型進行物理分離,讀取存儲可以是寫入存儲的只讀副本,使用多個只讀副本可以提高查詢性能;也可能為讀取模型單獨設計庫表。單獨對查詢和更新進行模型設計可以減小設計和實現的難度。并且此時讀取數據庫可使用自己的已針對查詢進行優化的數據架構。比如讀數據庫可以直接存儲查詢數據寬表從而避免進行join操作或者復雜的查詢映射。甚至可以針對讀取操作使用mongo或者es等nosql數據庫對查詢邏輯進行增強。
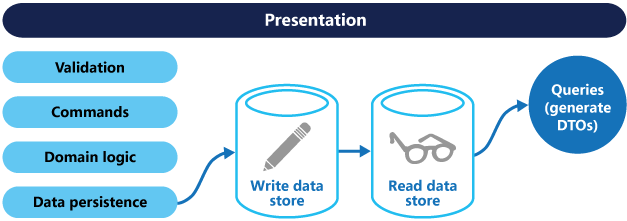
分離后的數據將存在在不同的數據庫中,Q的數據由C端同步過來。通常,這是通過在每次更新數據庫時使寫入模型發布事件來實現的。 而說到數據同步則就有同步執行和異步執行兩種方案:
- 同步:導致性能降低,但是可以保證數據的強一致性。
- 異步:擁有較高的性能,但需要系統接受最終一致性的。
同樣的,這種同步也可以解釋為對緩存進行的更新,即:查詢數據庫是使用緩存,而寫入數據庫使用普通MySQL,兩者之間數據同步通過領域事件實現最終一致性。
進一步強化
進一步的,由于命令操作實際上是對“操作”進行的記錄,而只有查詢才需要將所有的操作進行匯總展示。基于這種思想,可以使用事件溯源EventSourcing模式來進行命令操作的記錄。在這種方案下,保存記錄時更新的不是當前的記錄,而是會導致狀態變化的事件日志,每個事件表示對數據所作的一系列更改,而我們可以通過重播事件構造數據當前的狀態(可以參考Mysql的Binlog設計)。這種記錄的優點是可以根據回放,重現每一次狀態變更的時間點以及變更軌跡。而查詢則可以根據當前狀態的快照來為查詢提速。來自于網絡的架構圖:
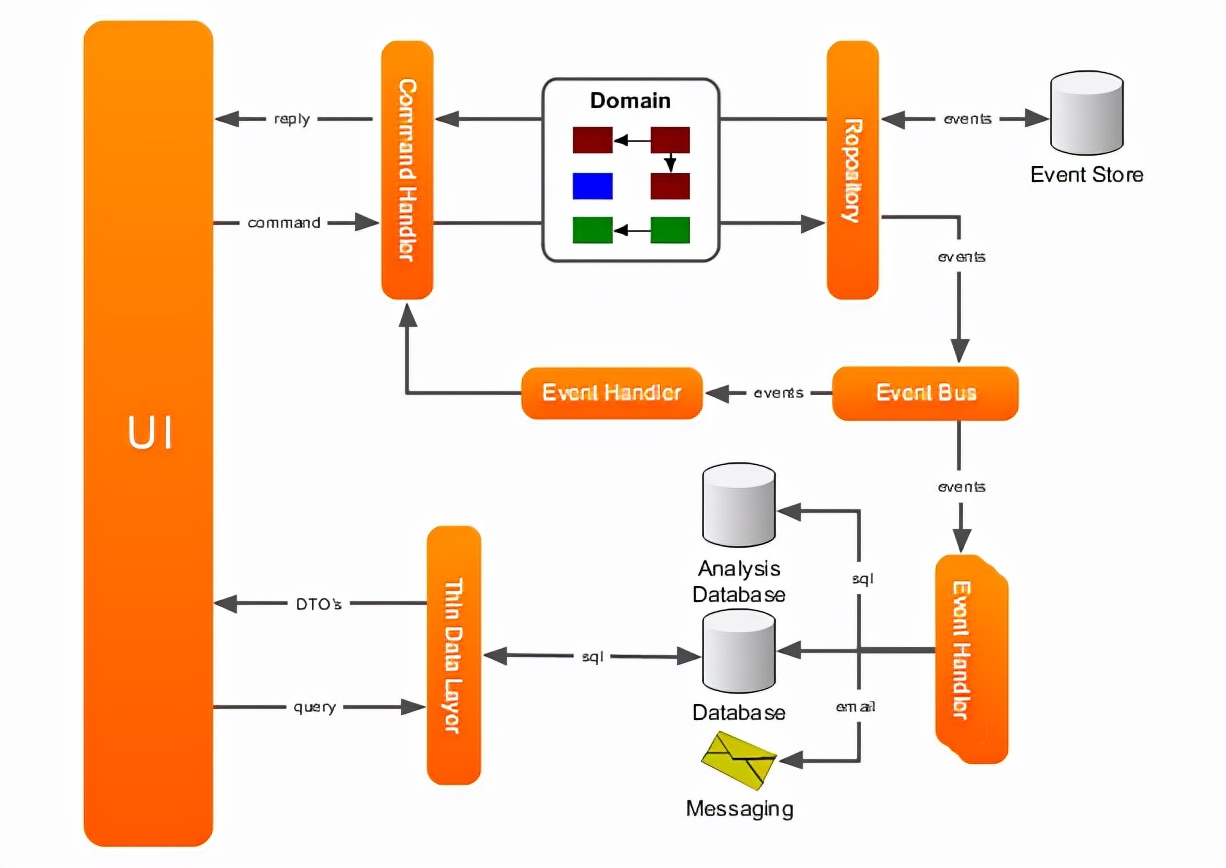
這種設計模式聽起來就比較復雜,但是卻有很多好處,例如:實現透明的分布式處理,當使用事件作為狀態改變的引擎時,你可以通過實現多任務并發處理,比如通過JVM并行計算或事件消息總線機制,事件能夠很容易序列化,并在多個服務器之間傳送。同時因為是保留的操作記錄,可以在回放的時候對于異常操作數據進行過濾,從而增加了數據的魯棒性。
使用挑戰
如果希望使用CQRS,根據你希望實現的系統性能,你需要評估當前系統架構以及個人經驗是否有以下能力:
- 復雜性設計:盡管CQRS基礎理念較為容易理解,但是這種模式會導致系統的構建復雜度上升,尤其是進一步使用事件溯源模式時。
- 消息隊列處理:在進行高性能設計的時候,通常會使用消息處理命令和發布更新事件。在此情況下,應用程序必須處理消息失敗或重復的消息。
- 最終一致性:如果分離讀取和寫入數據庫,讀取數據可能會過時。 必須更新讀取模型存儲,以反映對寫入模型存儲區所做的更改,并且在用戶根據過時的讀取數據發出請求時,可能很難檢測到這種情況。
選型建議
對于以下場景不建議引入CQRS:
- 領域或者業務十分簡單。
- 基本的CRUD就可以支撐完整的系統數據訪問需求。
如果系統存在一定的復雜性,并且有以下的特點,則可以根據特點,選擇適合的CQRS實現方式。
- 在用戶操作中,需要在用戶界面中進行一系列的復雜操作來最終定義、組裝、修改領域模型。寫模型需要有完成的命令處理堆棧,包括:輸入驗證、業務處理、業務驗證。而讀模型只需要返回視圖中所用到的DTO數據。讀模型與寫模型只需要最終一致性關系。
- 對于用戶的操作訪問,需要以較小的粒度定義命令,并通過合并命令的方式避免命令沖突。
- 數據寫入和數據讀取之前存在比較大的性能區別,需要分開進行數據優化。尤其是讀取次數遠大于寫入次數的場景,可以對讀模型進行水平擴展。
- 當團隊人員可以分拆分,組成專門針對復雜業務寫場景的組,以及專門針對高頻查詢和用戶界面的組。
- 當系統隨時間不斷演進,不斷包含多個版本的模型,或者業務規則會定期修改。可以在寫模式中包含多個版本的模型,而讀模式中使用統一的視圖模型。
- 與其他系統集成時,希望不會受到其他系統故障的影響(讀寫庫表分離)。
最后
總的來說,CQRS是處理復雜問題的一種具體實現方案,常用于配合DDD使用。
總結CQRS 的主要優點包括:
- 獨立縮放:CQRS 允許讀取和寫入工作負載獨立縮放,這可能會減少鎖爭用。
- 優化的數據架構: 讀取端可使用針對查詢優化的架構,寫入端可使用針對更新優化的架構。
- 安全性:更輕松地確保僅正確的域實體對數據執行寫入操作。
- 關注點分離:分離讀取和寫入端可使模型更易維護且更靈活。 大多數復雜的業務邏輯被分到寫模型。 讀模型會變得相對簡單。
- 查詢更簡單:通過將具體化視圖存儲在讀取數據庫中,應用程序可在查詢時避免復雜聯接。