













明明還有大量內存,為啥報錯“無法分配內存”?
大家好,我是飛哥!
讀者群里一位同學的線上服務器出現一個詭異的問題,執行任何命令都是報錯“fork:無法分配內存”。這個問題最近出現的,前幾次重啟后解決的,但是每隔 2-3 天就會出現一次。
# service docker stop
-bash fork: 無法分配內存
# vi 1.txt
-bash fork: 無法分配內存
看到這個提示,大家的第一反應肯定是懷疑內存真的不夠了。我們這位讀者也是這么認為的。但查看內存占用卻發現根本沒有,內存還空閑了一大把!(多試幾次才有機會執行成功一次)。

飛哥和群里的同學們一起參謀這個問題以后,幫出了三個思路。讓這位讀者回去挨個試。
1.是不是numa架構下,進程啟動的時候綁定了node,導致只有一個node里的內存在起作用?
2.numa架構下,如果所有內存都插到一個槽,其它node就會沒內存。
3.查看下現在的進(線)程數是多少,是不是超過最大限制了。
在經過一段時間的排查以后,這位讀者的問題順利解決。這里直接和大家匯報結論,前面關于 numa 內存不足的猜測是錯誤的。真實的原因是上面第 3 個,這臺服務器上面的某幾個java進程創建了太多的線程,導致了這個報錯的產生,并不真的是內存不夠。
一、底層過程分析
這個問題中,Linux 報錯提示存在誤導人的地方。導致大家并沒有第一時間往進程數上想。所以才有了這么復雜曲折的排錯過程,以至于在群里討論才得以解決。
于是我想深入到內核里看看,報錯到底是如何提示出來這么一個不恰當的錯誤提示的。然后順便咱們也來了解了解創建進程的過程。
讀者的線上服務器的操作系統是 CentOS 7.8,我查了一下對應的內核版本是 3.10.0-1127。
1.1 do_fork 剖析
在 Linux 內核里,無論是創建進程還是線程,都會調用到最核心的 do_fork 上來。在這個函數內部,通過拷貝的方式來創建新的進程(線程)所需要的內核數據對象。
//file:kernel/fork.c
long do_fork(unsigned long clone_flags, ...)
{
//所謂的創建,其實是根據當前進程進行拷貝
//注意:倒數第二個參數傳入的是 NULL
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
...
}
整個進程創建的核心都是位于 copy_process 中,我們來看它的源碼。
//file:kernel/fork.c
static struct task_struct *copy_process(unsigned long clone_flags,
...
struct pid *pid,
int trace)
{
//內核表示進程(線程)的數據結構叫task_struct
struct task_struct *p;
......
//拷貝方式生成新進程的核心數據結構
p = dup_task_struct(current);
//拷貝方式生成新進程的其它核心數據
retval = copy_semundo(clone_flags, p);
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
retval = copy_sighand(clone_flags, p);
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
retval = copy_io(clone_flags, p);
retval = copy_thread(clone_flags, stack_start, stack_size, p);
//注意這里!!!!!!
//申請整數形式的 pid 值
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
//將生成的整數pid值設置到新進程的 task_struct 上
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
bad_fork_cleanup_io:
if (p->io_context)
exit_io_context(p);
......
fork_out:
return ERR_PTR(retval);
}
通過以上代碼可以看出,Linux 內核創建整個進程內核對象的創建過程都是通過分別調用不同的 copy_xxx 的方式來實現的,包括 mm 結構體、包括 namespaces等等。
我們來重點 alloc_pid 相關的這一段。在這一段中,目的是要申請一個 pid 對象出來。如果申請失敗就返回錯誤了。大家注意這段代碼的細節:無論 alloc_pid 返回的是何種類型的失敗,其錯誤類型都寫死的返回 -ENOMEM...... 為了方便大家理解,我單獨把這段邏輯再展示一遍。
//file:kernel/fork.c
static struct task_struct *copy_process(...){
......
//申請整數形式的 pid 值
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
bad_fork_cleanup_io:
...
fork_out:
return ERR_PTR(retval);
}
在準備調用 alloc_pid 的時候,直接就先將錯誤類型設置成了 -ENOMEM(retval = -ENOMEM),只要 alloc_pid 返回的不正確,都是將 ENOMEM 這個錯誤返回給上層。而不管 alloc_pid 內存究竟是因為什么原因產生的錯誤。
我們來查看一下 ENOMEM 的定義。它代表的是 Out of memory 的意思。(內核只是返回錯誤碼,應用層再給出具體的錯誤提示,所以實際提示的是中文的“無法分配內存”)。
//file:include/uapi/asm-generic/errno-base.h
#define ENOMEM 12 /* Out of memory */
不得不說。內核的這個錯誤提示太成問題了。給使用者造成了很大的困惑。
1.2 導致 alloc_pid 失敗的原因
那我們接著再來詳細看看都有哪些情況下分配 pid 會失敗呢?來看 alloc_pid 的源碼:
//file:kernel/pid.c
struct pid *alloc_pid(struct pid_namespace *ns)
{
//第一種情況:申請 pid 內核對象失敗
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
if (!pid)
goto out;
//第二種情況:申請整數 pid 號失敗
//調用到alloc_pidmap來分配一個空閑的pid
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
...
out:
return pid;
out_free:
goto out;
}
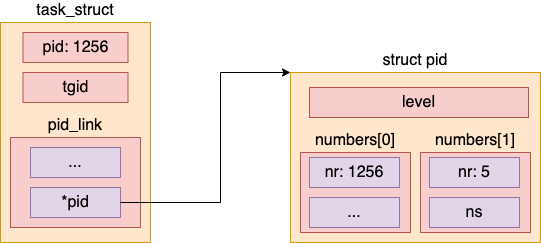
我們平時說的 pid 在內核中并不是一個簡單的整數類型,而是一個小結構體來表示的(struct pid),如下。
//file:include/linux/pid.h
struct pid
{
atomic_t count;
unsigned int level;
struct hlist_head tasks[PIDTYPE_MAX];
struct rcu_head rcu;
struct upid numbers[1];
};
所以需要先到內存中申請一塊內存用來存儲這個小對象。第一種錯誤情況是如果內存申請失敗,alloc_pid 會返回失敗。這種情況下確實是內存問題,出錯后內核返回 ENOMEM 無可厚非。
接著往下看第二種情況,alloc_pidmap 是要為當前的進程申請進程號,就是我們平時所說的 PID 編號。如果申請失敗,也會返回錯誤。
對于這種情況來說,只是分配進程編號出錯了,和內存不夠用半毛錢的關系都沒有。但在這種情況下內核卻會導致返回給上層的錯誤類型是 ENOMEM(Out of memory)。這實在是挺不合理的。
通過這里我們還額外學習到了另外一個知識!一個進程并不只是申請一個進程號就夠了。而是通過一個 for 循環去申請了多個。
//file:kernel/pid.c
struct pid *alloc_pid(struct pid_namespace *ns)
{
//調用到alloc_pidmap來分配一個空閑的pid
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
}
假如說當前創建的進程是一個容器中的進程,那么它至少得申請兩個 PID 號才行。一個 PID 是在容器命名空間中的進程號,一個是根命名空間(宿主機)中的進程號。
這也符合我們平時的經驗。在容器中的每一個進程其實我們在宿主機中也都能看到。但是在容器中看到的進程號一般是和在宿主機上看到的是不一樣的。比如一個進程在容器中的 pid 是 5,在宿主機命名空間下是 1256。那么該進程在內核中的對象大概是如下這個樣子。
二、新版本是否有所改觀
接下來,我首先想到的可能是因為咱們用的內核版本太舊了。(熟悉飛哥的讀者都知道,我用的內核版本是 3.10.1,這是為了和我們公司線上服務器的版本保持一致。)
所以我又到非常新的 Linux 5.16.11 翻了一翻,看看新版本是否有修復這個不恰當的提示。
推薦一個工具:https://elixir.bootlin.com/ 。在這個網站上可以查看任意版本的 linux 內核源碼。如果只是臨時看一下,用它非常的合適。
//file:kernel/fork.c
static __latent_entropy struct task_struct *copy_process(...)
{
...
pid = alloc_pid(p->nsproxy->pid_ns_for_children, args->set_tid,
args->set_tid_size);
if (IS_ERR(pid)) {
retval = PTR_ERR(pid);
goto bad_fork_cleanup_thread;
}
}
貌似看起來有戲,retval 不再寫死的是 ENOMEM 了,而是根據 alloc_pid 實際的錯誤進行了設置。我們再來看 alloc_pid 是不是正確地設置錯誤類型了呢?
當我打開 alloc_pid 的源碼里,看到這一大段注釋的時候,我的心涼了半截......
//file:include/pid.c
struct pid *alloc_pid(struct pid_namespace *ns, ...)
{
/*
* ENOMEM is not the most obvious choice especially for the case
* where the child subreaper has already exited and the pid
* namespace denies the creation of any new processes. But ENOMEM
* is what we have exposed to userspace for a long time and it is
* documented behavior for pid namespaces. So we can't easily
* change it even if there were an error code better suited.
*/
retval = -ENOMEM;
.......
return retval
}
我把這段注釋給大家大致翻譯一下。它的意思是“ENOMEM不是最明顯的選擇,尤其是對于 pid 創建失敗的情況下。但是,ENOMEM 是我們長期暴露給用戶空間的東西。因此,即使有更適合的錯誤代碼,我們也無法輕易更改它”。
看到這兒,我想起了有不少人也稱 Linux 為屎山,可能這就是其中的一坨吧!最新的版本里也并沒有很好地解決這個問題。
結論
在 Linux 里創建進程時,如果在 pid 不足的時候竟然返回的錯誤提示是“內存不足”。這個不恰當的錯誤提示導致很多同學都困惑不已。
通過今天的文章,以后你再遇到這種內存不足錯誤的時候,你就要多留個心眼兒了,別被內核被蒙騙了,先來看看自己的進程(線程)數是不是過多了。
至于說發現了這個問題該如何解決嘛,可以通過修改內核參數加大可用 pid 數量(/proc/sys/kernel/pid_max)。
但是我覺得最根本的方法還是要揪出來為啥系統中會出現這么多的進程(線程),然后把它干掉。默認情況下的兩三萬個進程數對于絕大多數的服務器來說已經是一個過于龐大的數字了,連這個數都超過了,一定是不合理的。

















