阿里巴巴開源大規模稀疏模型訓練/預測引擎DeepRec
原創經歷6年時間,在各團隊的努力下,阿里巴巴集團大規模稀疏模型訓練/預測引擎DeepRec正式對外開源,助力開發者提升稀疏模型訓練性能和效果。
一、DeepRec是什么
DeepRec(PAI-TF)是阿里巴巴集團統一的大規模稀疏模型訓練/預測引擎,廣泛應用于淘寶、天貓、阿里媽媽、高德、淘特、AliExpress、Lazada等,支持了淘寶搜索、推薦、廣告等核心業務,支撐著千億特征、萬億樣本的超大規模稀疏訓練。
DeepRec在分布式、圖優化、算子、Runtime等方面對稀疏模型進行了深度性能優化,同時提供了稀疏場景下特有的Embedding相關功能。
DeepRec項目從2016年開發至今,由阿里巴巴集團內AOP團隊、XDL團隊、PAI團隊、RTP團隊以及螞蟻集團AIInfra團隊共建,并且得到了淘寶推薦算法等多個業務算法團隊的支持。DeepRec的研發也得到了Intel CESG軟件團隊、Optane團隊和PSU團隊,NVIDIA GPU計算專家團隊及Merlin HughCTR團隊的支持。
二、DeepRec架構設計原則
在TensorFlow引擎上支持大規模稀疏特征,業界有多種實現方式,其中最常見的方式是借鑒了ParameterServer的架構實現,在TensorFlow之外獨立實現了一套ParameterServer和相關的優化器,同時在TensorFlow內部通過bridge的方式橋接了兩個模塊。這個做法有一定的好處,比如PS的實現會比較靈活,但也存在一些局限性。
DeepRec采取了另一種架構設計方式,遵循“視整個訓練引擎為一個系統整體”的架構設計原則。TensorFlow是一個基于Graph的靜態圖訓練引擎,在其架構上有相應的分層,比如最上層的API層、中間的圖優化層和最下層的算子層。TensorFlow通過這三層的設計去支撐上層不同Workload的業務需求和性能優化需求。
DeepRec也堅持了這一設計原則,基于存儲/計算解耦的設計原則在Graph層面引入EmbeddingVariable功能;基于Graph的特點實現了通信的算子融合。通過這樣的設計原則,DeepRec可以支持用戶在單機、分布式場景下使用同一個優化器的實現和同一套EmbeddingVariable的實現;同時在Graph層面引入多種優化能力,從而做到獨立模塊設計所做不到的聯合優化設計。
三、DeepRec的優勢
DeepRec是基于TensorFlow1.15、Intel-TF、NV-TF構建的稀疏模型訓練/預測引擎,針對稀疏模型場景進行了定制深度優化,主要包含以下三類功能優化:
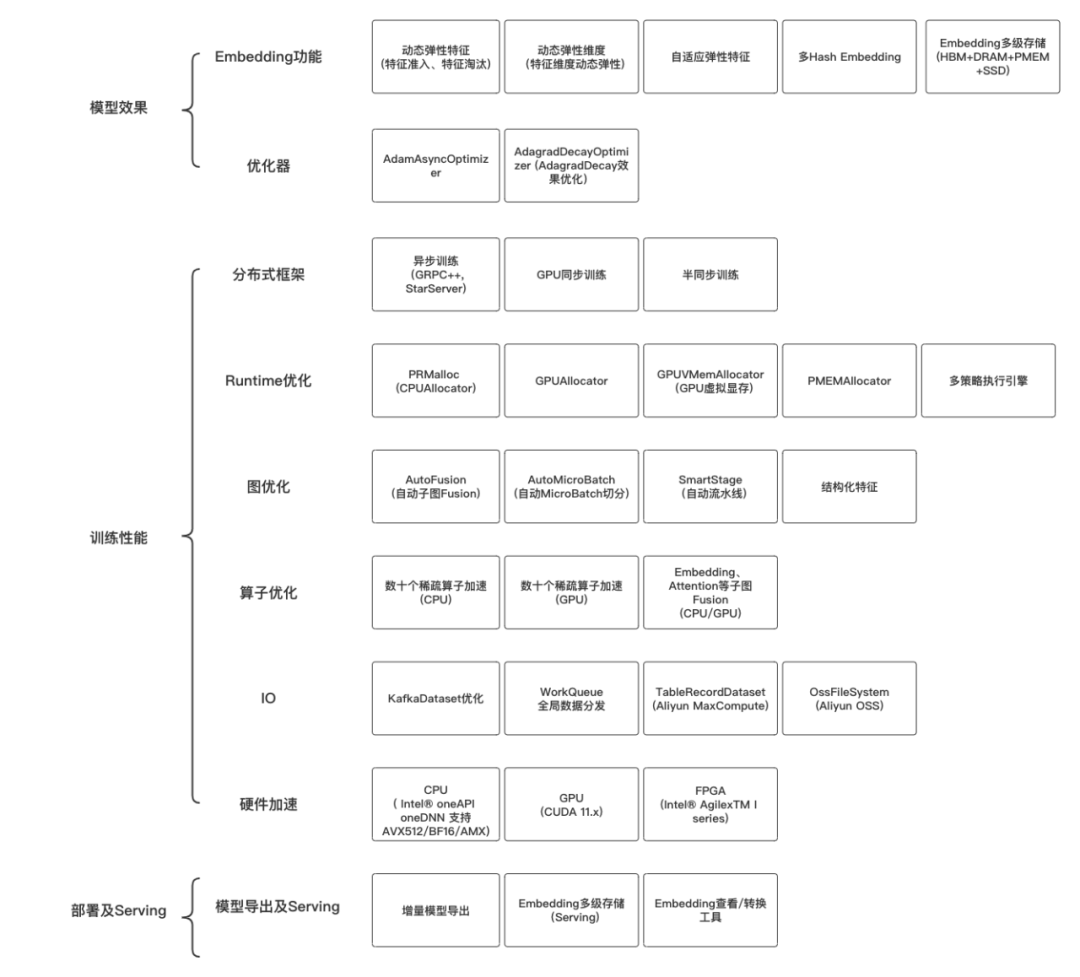
1.模型效果
DeepRec提供了豐富的稀疏功能支持,提高模型效果的同時降低稀疏模型的大小,并且優化超大規模下Optimizer的效果。下面簡單介紹Embedding及Optimizer幾個有特色的工作:
- EmbeddingVariable(動態彈性特征):
(1)解決了靜態Shape Variable的vocabulary_size難以預估、特征沖突、內存及IO冗余等問題,并且在DeepRec中提供了豐富的EmbeddingVariable的進階功能,包括不同的特征準入方式、支持不同的特征淘汰策略等,能夠明顯提高稀疏模型的效果。
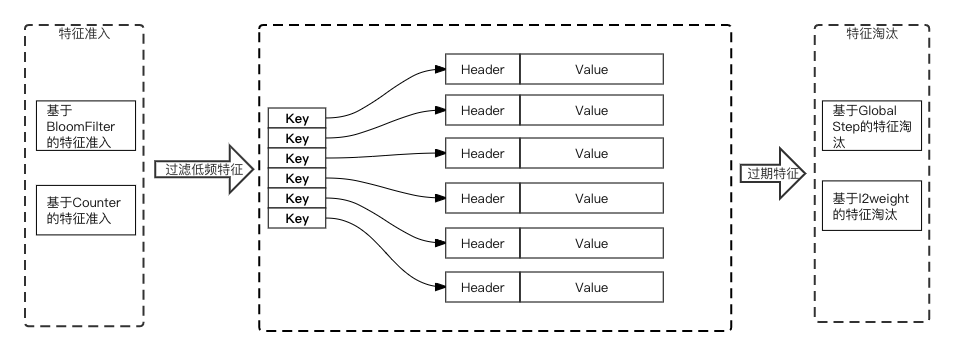
(2)在訪問效率上,為了達到更優化的性能和更低的內存占用,EmbeddingVariable的底層HashTable實現了無鎖化設計,并且進行了精細的內存布局優化,優化了HashTable的訪問頻次,使得在訓練過程中前后向只需訪問一次HashTable。
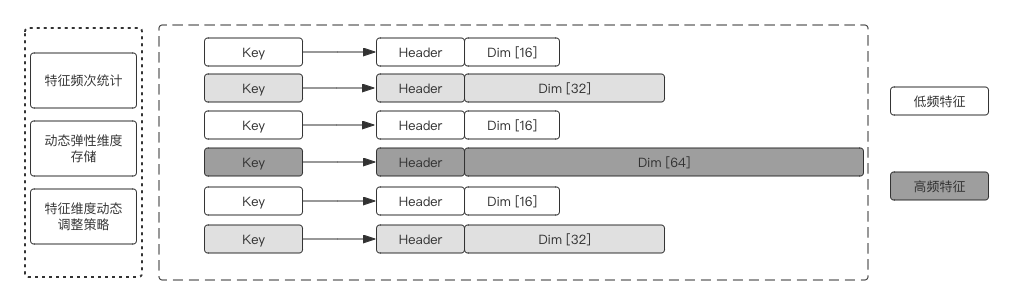
- DynamicDimensionEmbeddingVariable(動態彈性維度):
在典型的稀疏場景中,同類特征的出現頻次往往極度不均勻。通常情況下,同一個特征列的特征都被設置成統一維度,如果Embedding維度過高,低頻特征容易過擬合,而且會額外耗費大量內存;如果維度設置過低,高頻部征特征可能會由于表達不夠而影響效果。
Dynamic Dimension Embedding Variable提供了同一特征列的不同特征值,根據特征的冷熱自動配置不同的特征維度,高頻特征可以配置更高維度增強表達能力,而低頻特征因為給定低維度embedding緩解了過擬合的問題,而且可以極大程度節省內存(低頻長尾特征的數量占據絕對優勢)。
- Adaptive Embedding(自適應Embedding):
當使用動態彈性特征功能時,低頻特征存在過擬合問題。EmbeddingVariable中所有的特征都從initializer設定的初始值(一般設為0)開始學起,對于一些出現頻次從低到高的特征,也需要逐漸學習到一個較好的狀態,不能共享別的特征的學習結果。AdaptiveEmbedding功能使用靜態Shape Variable和動態EmbeddingVariable共同存儲稀疏特征,對于新加入的特征存于有沖突的Variable,對于出現頻率較高的特征存于無沖突的EmbeddingVariable,特征遷移到EmbeddingVaraible可以復用在有沖突的靜態Shape Variable的學習結果。

- Adagrad Decay Optimizer:
為支持超大規模訓練而提出的一種改進版Adagrad優化器。當模型訓練的樣本量大,同時持續增量訓練較長時間時,Adagrad優化器的梯度會趨近于0,導致新增訓練的數據無法對模型產生影響。已有的累積打折的方案雖然可以解決梯度趨近0的問題,但也會帶來模型效果變差的問題(通過iteration打折策略無法反映實際的業務場景特點)。Adagrad Decay Optimizer基于周期打折的策略,同一個周期內的樣本相同的打折力度,兼顧數據的無限累積和樣本順序對模型的影響。
此外,DeepRec還提供Multi-HashEmbedding、AdamAsyncOptimizer等功能,在內存占用、性能、模型效果等方面為業務帶來實際的幫助。
2.訓練性能
DeepRec針對稀疏模型場景在分布式、圖優化、算子、Runtime等方面進行了深度性能優化。其中,DeepRec對不同的分布式策略進行了深度的優化,包括異步訓練、同步訓練、半同步訓練等,其中GPU同步訓練支持HybridBackend以及NVIDIA HugeCTR-SOK。DeepRec提供了豐富的針對稀疏模型訓練的圖優化功能,包括自動流水線SmartStage、結構化特征、自動圖Fusion等等。DeepRec中優化了稀疏模型中數十個常見算子,并且提供了包括Embedding、Attention等通用子圖的Fusion算子。DeepRec中CPUAllocator和GPUAllocator能夠大大降低內存/顯存的使用量并顯著加速E2E的訓練性能。在線程調度、執行引擎方面針對不同的場景提供了不同的調度引擎策略。下面簡單介紹分布式、圖優化、Runtime優化方面幾個有特色的工作:
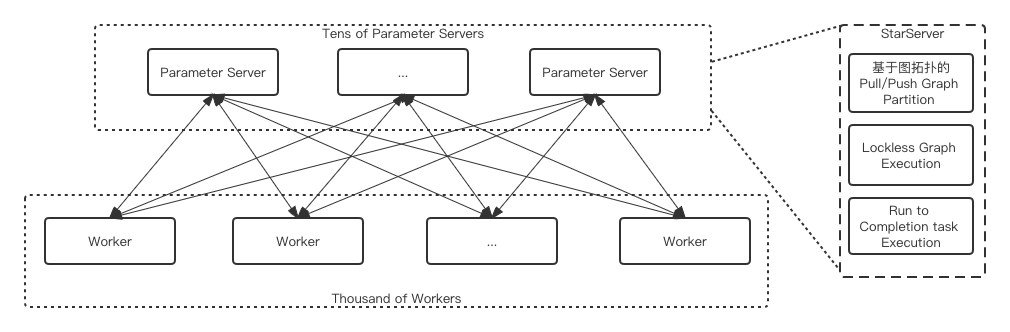
- StarServer(異步訓練框架):
在超大規模任務場景下(幾百、上千worker),原生開源框架中的一些問題被暴露出來,譬如低效的線程池調度、關鍵路徑上的鎖開銷、低效的執行引擎、頻繁的小包rpc帶來的開銷導致ParameterServer在分布式擴展時成為明顯的性能瓶頸。StarServer進行了包括圖、線程調度、執行引擎以及內存等優化,將原有框架中的send/recv語義修改為pull/push語義,并且在子圖劃分上支持了該語義,同時實現了ParameterServer端圖執行過程中的lockfree,實現了無鎖化的執行,大大提高了并發執行子圖的效率。對比原生框架,能夠提升數倍的訓練性能,并且支持3000worker規模的線性分布式擴展。
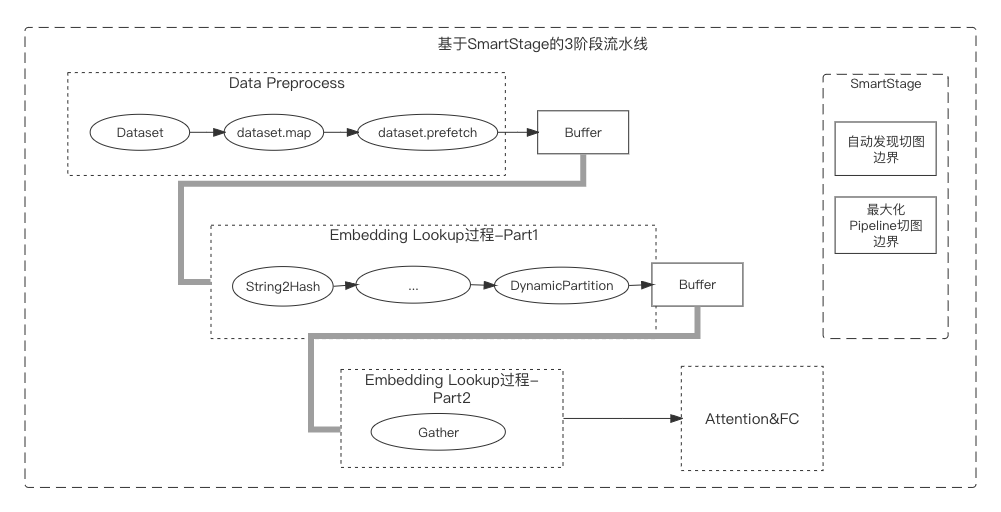
- SmartStage(自動流水線):
稀疏模型訓練通常包含樣本數據的讀取、Embedding查找、Attention/MLP計算等,樣本讀取和Embedding查找非計算密集操作,同時并不能高效利用計算資源(CPU、GPU)。原生框架中提供的dataset.prefetch接口可以異步化樣本讀取操作,但Embedding查找過程中涉及特征補齊、ID化等復雜的過程,這些過程無法通過prefetch進行流水線化。SmartStage功能能夠自動分析圖中異步流水線化的邊界并自動插入,可以使并發流水線發揮最大的性能提升。
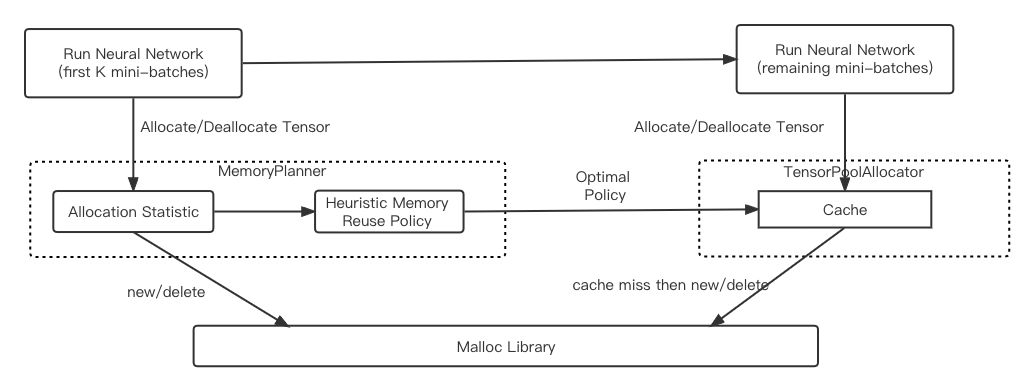
- PRMalloc(內存分配器):
如何做到既高效又有效的使用內存,對于稀疏模型的訓練非常關鍵,稀疏場景模型訓練中大塊內存分配使用造成大量的minor pagefault,此外,多線程分配效率存在比較嚴重的并發分配效率問題。針對稀疏模型訓練前向、后向,Graph計算模式的相對固定、多輪反復迭代的特點,DeepRec設計了一套針對深度學習任務的內存管理方案,提高內存的使用效率和系統性能。使用DeepRec中提供的PRMalloc能夠極大降低訓練過程中minor pagefault,提高多線程并發內存分配、釋放的效率。
- PMEM allocator(持久內存分配器):
基于PMDK的底層libpmem庫實現的PMEM allocator將從PMEM map出的一塊空間分為若干segment,每個segment又分成若干blocks,block是allocator的最小分配單元。分配block的線程為避免線程競爭,緩存一些可用空間,包括一組segment和free list。可用空間中為每種record size(若干個block)維護一個free list和segment。各record size對應的segment只分配該大小的PMEM空間,各record size對應的free list中的所有指針均指向對應record size的空閑空間。此外,為了均衡各thread cache的資源,由一個后臺線程周期地將thread cache中的free list移動到后臺的pool中,pool中的資源由所有前臺線程共享。實驗證明,基于持久內存實現的內存分配器在大模型的訓練性能方面與基于DRAM的訓練性能差別很小,但是TCO會有很大的優勢。
3.部署及Serving
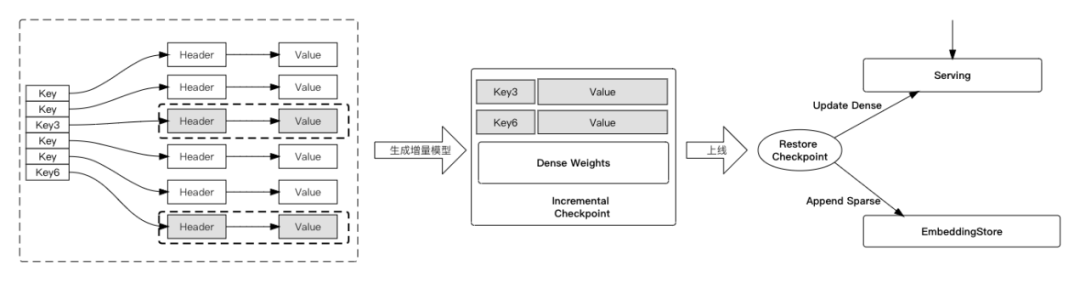
- 增量模型導出及加載:
時效性要求高的業務,需要頻繁的線上模型更新,頻率往往達到分鐘級別甚至秒級。對于TB-10TB級別的超大模型而言,分鐘級別的模型生成到上線很難完成。此外,超大模型的訓練和預測存在著資源浪費、多節點Serving延時加大等問題。DeepRec提供了增量模型產出及加載能力,極大加速了超大模型生成和加載。
Embedding多級混合存儲:
稀疏模型中特征存在冷熱傾斜的特性,這產生了某些冷門特征很少被訪問和更新導致的內存/顯存浪費問題,以及超大模型內存/顯存放不下的問題。DeepRec提供了多級混合存儲(支持最多四級的混合存儲HBM+DRAM+PMEM+SSD)的能力,自動將冷門特征存放到廉價的存儲介質中,將熱門特征存放到訪問更快、更貴的存儲介質上,通過多級混合存儲,使得單節點可以進行TB-10TB模型的Training和Serving。
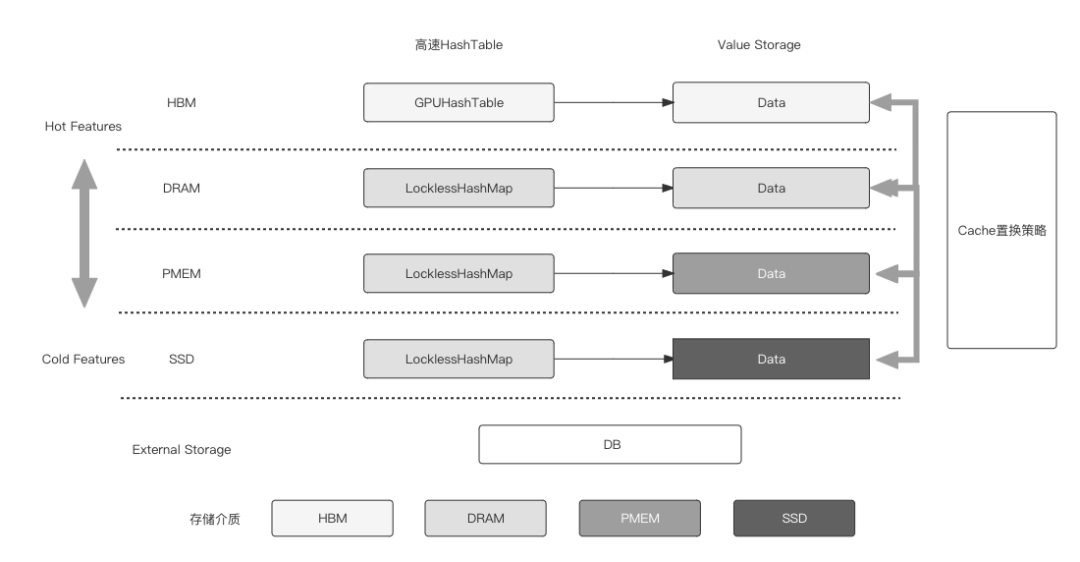
通過多級混合存儲,能夠更大發揮GPU訓練稀疏模型的能力,同時降低由于存儲資源限制造成的計算資源浪費,可以使用更少的機器進行相近規模的模型訓練,或者使用相同數量的機器進行更大規模的訓練。多級混合存儲也能使得單機進行超大模型預測時避免分布式Serving帶來的latency增大問題,提高大模型的預測性能的同時降低成本。多級混合存儲功能也擁有自動發現特征的訪問特性,基于高效的熱度統計策略,將熱度高的特征放置到快速的存儲介質中,將低頻的特征offload到低速存儲介質中,再通過異步方式驅動特征在多個介質之間移動。
四、為什么開源DeepRec
開源深度學習框架都不能很好地支持稀疏場景中對于稀疏Embedding功能的需求、模型訓練性能需求、部署迭代和線上服務的需求。DeepRec經過阿里巴巴集團搜索、推薦、廣告等核心業務場景及公有云上各種業務場景的打磨,能夠支持不同類型的稀疏場景訓練效果和性能需求。
阿里巴巴希望通過建立開源社區,和外部開發者開展廣泛合作,進一步推動稀疏模型訓練/預測框架的發展,為不同業務場景中的搜推廣模型訓練和預測帶來業務效果和性能提升。
今天DeepRec的開源只是我們邁出的一小步。我們非常期待得到您的反饋。最后,如果你對DeepRec有相應的興趣,你也可以來轉轉,為我們的框架貢獻一點你的代碼和意見,這將是我們莫大的榮幸。
開源地址:https://github.com/alibaba/DeepRec