因為一個循環,CPU搞了個新技術!
好久不見,我叫阿Q,是CPU一號車間的員工。我所在的CPU有8個車間,也就是8個核心,咱們每個核心都可以同時執行兩個線程,就是8核16線程,那速度杠杠滴。

我所在的一號車間,除了負責執行指令的我,還有負責讀取指令的小A,負責指令譯碼的小胖和負責結果回寫的老K,我們幾個各司其職,一起完成執行程序的工作。
一個簡單的循環
那天,我們遇到了一段代碼:
void array_add(int data[], int len) {
for (int i = 0; i < len; i++) {
data[i] += 1;
}
}
循環了好幾百次之后,才把這段代碼執行完成,每次循環都是做簡單又重復的工作,把我累得夠嗆。
一旁負責結果回寫的老K也是累的滿頭大汗,吐槽道:“每次都是取出來加1又寫回去,要是能一次多取幾個數,批量處理就好了”
老K的話讓我眼前一亮,對啊,能不能批量操作呢?
心里一邊想著,一邊繼續干活了。
繁忙的一天很快結束了,轉眼又到了晚上,計算機關機后,我把大家召集了起來。
“兄弟們,還記得咱們白天遇到的那個循環嗎?”
“你說哪個循環,咱們這一天可執行了不少循環呢”,小A說到。
“就是那個把整數數組每個元素都加1的那個循環”
“我想起來了,那循環怎么了?有什么問題嗎?”
我看了老K一眼,說道:“我在想今天老K的話,像這種循環,每次都是取出來加1又寫回去,一次操作一個數,效率太低了,咱們要是升級改造一下,支持一次取出多個數,批量加1,這樣豈不是快很多?”
老K一聽來了興趣,“這敢情好,你打算怎么做?”
“這我還沒想好,大家有什么建議嗎?”
一旁負責指令譯碼的小胖說道:“可以新增一條指令,專門用來一次取出多個數據來加1”
“不行不行,不能限的這么死,今天是加1,萬一下次是加2呢?指令里面不能限制為1”
“那如果每個數據要加的是不一樣的怎么辦?”
“你這么一說,那萬一不是加法,是減法,乘法怎么辦?”
“還有啊,···”
大家開始七嘴八舌討論了起來,沒想到一個小小的加法循環,一下子引出了這么多問題來,這是我們沒想到的。
并行計算
隨著討論的深入,我覺得已經超出了咱們一號車間能把控的范圍,需要上報給領導,組織八個車間代表一起來商討。
領導一聽說有提高性能的新技術,馬上來了興趣,很快便開會組織大家一起來商討方案。

“都到齊了是吧,阿Q你給大家說一下這個會議的目的”,領導說到。
我站了起來,開始把我們遇到的問題和想法跟大家講了一遍。
“是這樣的,我們一號車間那天遇到了一段循環代碼,循環體的內容很簡單,就是給數組中的每一個元素加1。我們執行的時候,就是不斷取出每一個元素,然后將其執行加法計算后,再寫回去。這樣一個一個來加1,我們感覺太慢了, 要是可以一次多取幾個,并行加1,那一定比一個一個加快上不少。”
我剛說完,大家都開始小聲議論起來。
“我看出來了,這其實就是并行計算!”,二號車間小虎一語道出了關鍵。
六號車間小六問道:”阿Q,你們已經有方案了嗎?“
“還沒有,這正是今天開會的目的,因為情況有點復雜,還需要大家一起來出出主意”
“好像并不復雜嘛”
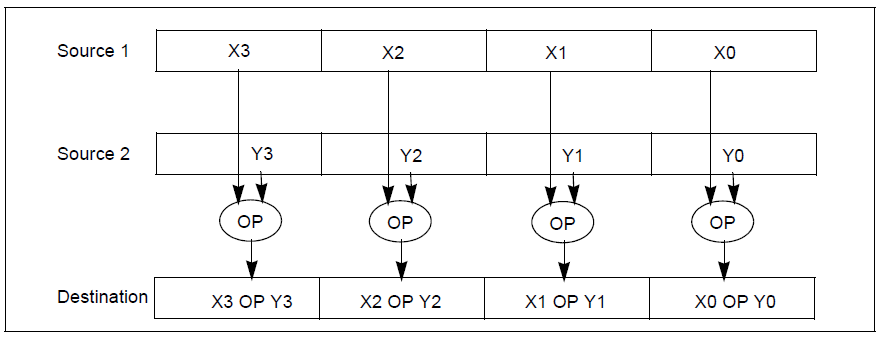
“我上面舉的例子只是一個簡單的情況,并行計算還可能不是固定的數,可能是一個數組和另一個數組相加。還有可能不是整數相加,而是浮點數,甚至,還可能不是加法,而是減法或者乘法,再或者不是算術運算,而是邏輯運算”
我剛一說完,大家又開始竊竊私語交流起來。
“我琢磨著你說的這一系列東西,咱們是要新增一套專門用來并行計算的指令集啊”,小虎說道。
“這可是大工程啊”
“是啊···”
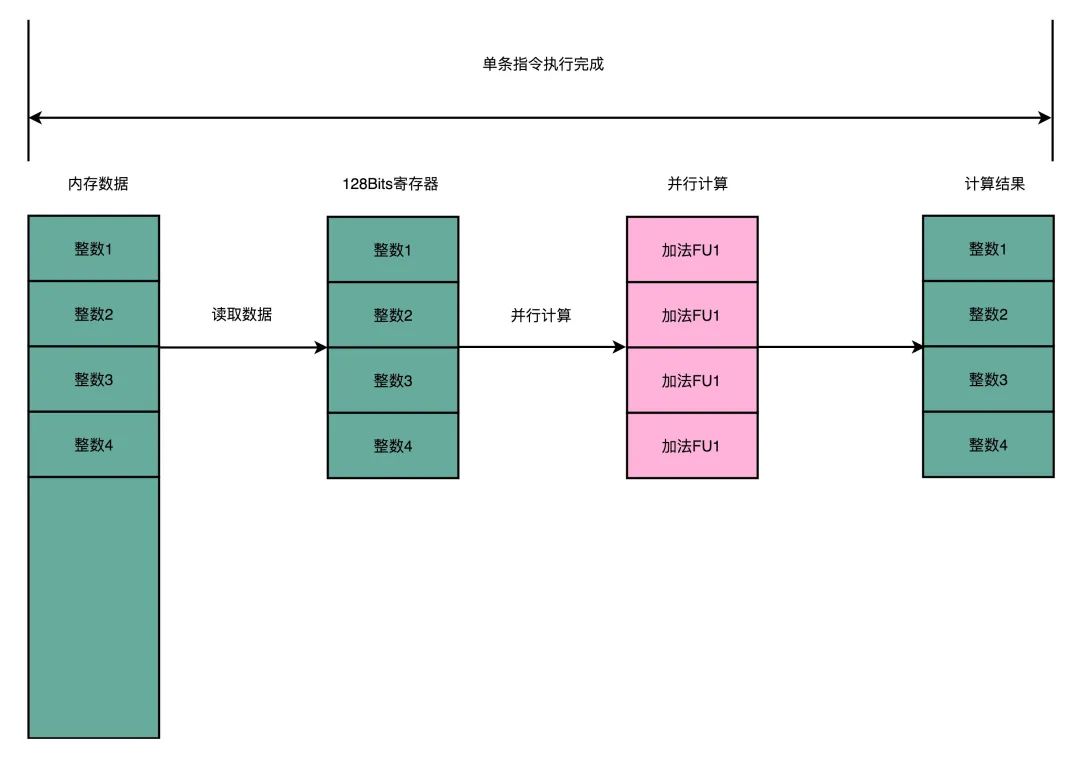
這時,小六又問道:“咱們的計算的時候,都是把數據讀取到寄存器進行的,可這寄存器一次只能裝一個數,怎么一次讀取多個數據呢?”
“可能需要新增一些容量大一些的寄存器,比如128bit長度,可以同時容納4個32位的整數”
“有這個必要嗎?咱們是通用CPU,又不是專門做數學計算的芯片,搞這些東西干嘛?”,四號車間代表提出了質疑。
我也不甘示弱:“那可太有必要了,在圖像、視頻、音頻處理等領域,有大量這樣的計算需求,咱們得提升處理這些數據的能力”
見我們爭執不下,領導拍了拍桌子,會場一下安靜了下來。
“我覺得阿Q說的有道理,咱們確實需要提升處理這類數據運算的能力了。不過不用一下搞那么復雜,先支持整數并行運算就行了。新增寄存器這個也不用著急,可以先借用一下浮點數運算單元FPU的寄存器。這件事先這么定下來,具體的方案你們再繼續討論。”,說完便離開了會議室。
領導不愧是領導,幾句話就把我們安排的明明白白。
SIMD
又經過一陣緊張的討論,我們終于敲定了方案。
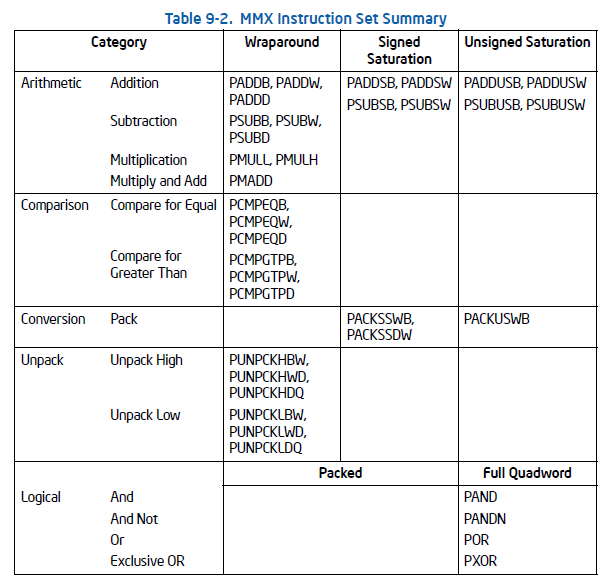
我們借用浮點數運算單元的寄存器,還給它們起了新的名字:MM0-MM7。因為是64位的寄存器,所以可以同時存儲兩個32位的整數或者4個16位整數或者8個8位的整數。
我們還新增了一套叫MMX的指令集,用來并行執行整數的運算。
我們把這種在一條指令中同時處理多個數據的技術叫做單指令多數據流(Single Instruction Multiple Data),簡稱SIMD。
有了這套指令集,咱們處理這類整數運算問題的速度快了不少。
不過漸漸地發現了兩個很麻煩的問題:
- 第一個問題,因為是借用FPU的寄存器,所以當執行SIMD指令的時候,就不能用FPU計算單元,反過來也一樣,同時使用的話就會出亂子,所以要經常在不同的模式之間切換,實在是有些麻煩。
- 另一個更重要的問題,咱們這套指令集只能處理整數的并行運算,可現在浮點數的并行運算越來越多,尤其是圖像、視頻還有深度學習的一些數據處理,浮點數情況越來越多,這時候都派不上用場。
我們把這些問題給領導做了匯報,看到我們已經做出的成績,領導終于同意繼續升級。
這一次,我們擴展了一套新的SSE指令集出來,新增了XMM0-XMM7總共8個128位的寄存器,再也不用跟FPU共享寄存器了。而且位寬加了一倍,能容納的數據更多了,能同時處理的數據自然也變多了。
后來,我們又不斷的修改升級,不僅支持了對浮點數并行處理,還推出了新一代的AVX指令集,把寄存器再一次擴大為256位,現在我們的SIMD技術更加先進,處理數據運算的能力越來越強了!