如何構建政務大數據生態
政務大數據的重要價值和發展前景早已不言而喻。近年,全國各地不乏挖掘和利用政務大數據價值的探索實踐。
但是,由于受慣性思維影響,項目模式仍被普遍套用到政務大數據工作上,從實際效果看并不理想,政務大數據成果的數量和質量都很不夠,遠遠不能滿足政府、企業和社會的發展需要,距離期待中的大數據產業相去甚遠。這揭示了當前政務大數據工作的一個嚴重問題——創新力不足。
如何構建政務大數據生態,培育政務大數據創新力,早日迎來政務大數據的春天,使得政務大數據的價值源源不斷地釋放出來,已經成為一個重要問題和努力方向。
項目模式扼制了政務大數據的創新力
長期以來,項目模式一直是政務信息化采購和建設的默認方式,有力保障和推動了政務信息化水平大幅提升。但是,在政務大數據建設中如果繼續簡單套用項目模式,則會導致上述創新力匱乏的問題。分析原因如下:
項目模式的排他性與政務大數據的公共性存在根本沖突。
政務大數據具有天然的公共性,因此決定政務大數據必然要為政府決策服務,為社會治理服務,為便民利民服務,為產業經濟服務。而且基于政務大數據的服務一旦開始輸出,就需要持續地做下去,不能夠中斷或半途而廢。
然而項目模式在合同期(譬如1-2年)內具有明顯的封閉性和排他性,這跟政務大數據的公共性構成了根本性沖突。
項目模式嚴重束縛了政務大數據的創新力。
經過幾十年的信息化建設,政務數據積累的資源規模足夠龐大,增長速度足夠迅猛,蘊藏價值足夠豐富;與此同時,隨著大數據時代來臨,政務大數據的社會需求也足夠深厚和寬廣。數據之間進行跨時空的、高密度的碰撞、連接、融合、交互等相互作用,必將能夠產生無可限量的經濟價值和商業機會。
由此可見,要想做好政務大數據工作,就必然要求新的條件:創新的工作管理模式、持續的資源投入和廣泛的社會參與。只有這樣,才可能涌現出旺盛不竭的創新力,才可能挖掘出連綿不斷的數據價值。
項目模式嚴重束縛了創新力。在浩瀚的政務大數據面前,項目模式下任何一家公司的力量都是微不足道的,無力應對業務場景的復雜多變,無力應對自身創新力的匱乏和技術人員的自然流動。由于在合同期內缺乏競爭,項目成效乏善可陳,客戶體驗普遍較差。這些問題必然會導致政務大數據項目陷入難以為繼的困局。
項目模式下隱藏著多緯度風險。
政府部門承擔的風險在于,一方面投入了寶貴的數據資源,支出了大量的資金成本和時間成本;另一方面卻難以收獲滿意的成果,不斷增長的迫切的決策需求、管理需求和服務需求得不到有效滿足,開展大數據創新應用的意愿受挫。
創新公司面臨的風險在于,處在合同里面的公司創新能力不足。這個不足有兩層含意,一是由于合同期內缺少競爭,必然導致公司一定程度上的惰性,表現為創新力不足、成果不足;二是相對于龐大的大數據需求來說,一家公司的創新力必然是有限的。合同外面的大量公司在合同期內進不來,錯過了大數據創新的窗口期。
社會層面的風險在于,基于政務大數據的服務能力輸出匱乏,強烈的公共服務需求被“餓死”;區域大數據產業成為空中樓閣。
服務模式有利于創新力涌現出來
政務大數據呼喚旺盛不竭的創新力。然而創新力并不會憑空冒出來,它的不斷涌現離不開良好的政務大數據生態環境。這需要在政府主導下,拓展思路,轉換模式。
政府購買服務是現有的一種財政采購模式,過去在信息化建設中運用得比較少。現在正好適合用來構建政務大數據生態。
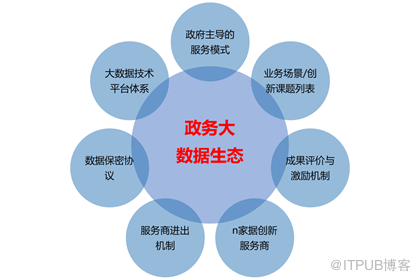
政務大數據生態的構成要素有:
1.服務模式。采取政府購買服務模式是構建政務大數據生態的核心機制。
2.政府主導。政府部門主導構建本部門的政務大數據生態, 有序有限地開放政務大數據資源,提出大數據應用的需求和場景,同時與多家大數據創新公司合作,以服務模式購買和應用大數據創新成果。省政府大數據局是省內整個政務大數據生態的領導者、倡導者。
3.業務場景和創新課題列表。緊密結合工作發展需要,政府部門通過內外部征集,定期向社會 公布本部門大數據創新課題列表。
4.大數據創新公司。 設定合理的入圍條件,選擇一批有能力、負責任的大數據創新公司。公司從部門大數據創新課題列表中選擇課題,投入專業力量,各盡所能,并行開展大數據創新活動。可以被要求交納一定數量的風險保證金。
5. 成果評價與激勵機制。建立綜合的政務大數據創新成果評價與激勵機制。包括公司準入條件、退出條件,成果評價標準,服務費分配辦法,大數據增值服務管理辦法等。成果評價專家組構成多元化,包含部門內部的業務專家、技術專家,部門外部的大數據專家、經濟學家、法律專家、企業用戶代表、個人用戶代表等。
6. 數據保密協議。明確界定具體大數據創新課題所能訪問數據的內容、范圍、期限、用途、方式及違約責任等。
7.大數據技術支撐平臺。在省政府建設的政務云當中,建設敏捷、先進、開放的大數據技術平臺,足以容納各政府部門的大數據,足以支撐眾多創新主體在該平臺上迸發出創新活力,持續輸出大數據創新應用和服務。
以服務模式構建政務大數據生態的優勢:
1.全程都有較高烈度的公平競爭。
2.催生政務大數據創新力的持續涌現,十分有利于大數據成果的研發、輸出與迭代,更多、更好的業務場景持續得以落地和演進。
3.有利于平抑各方風險。政府投入了數據、資金、人力、時間,服務模式遠比項目模式更有確定性地保障政府部門持續收割大數據成果。日益增長的基于大數據的公共服務需求不斷得到滿足。富于創新力的公司將得到穩定的資金收入,能夠生存發展下去;缺乏創新力的公司則在每日持續的競爭中顯出頹勢,也能夠及時出局和得到“止損”。
4.政務大數據創新活動可持續,有利于促進大數據產業的形成與發展。
政務大數據生態建設需要分兩步走
1.推動政務大數據從部門開始是第一階段。
各政府部門是政務大數據的生產者、維護者和應用者,是數據的直接責任主體,是公共服務的提供者。
政府部門有最直接的、旺盛的大數據應用場景需求,用于本部門的宏觀決策、精細管理和公共服務,最熟悉本部門業務,最具有數據洞察力。
因此說,部門大數據是整體政務大數據的必要構成和基礎。
部門在數據上的協作意識需要在具體的大數據實踐中逐漸養成和提高,同時積累大數據工作的管理經驗。
部門需要在實施大數據活動過程中持續開展內部數據質量治理。
2.開展跨部門的大數據應用是第二階段。
在各部門成功開展大數據活動的基礎上,協商建立跨部門的大數據協作機制,就比較順理成章了。
跨部門協作應立足于“不拿走”數據,通過“數據沙箱”、系統接口服務等安全機制“訪問”所需要的部門數據。這樣易于推行,易于管理,易于劃清部門責任邊界。
綜合性的大數據課題則可以分解為若干子課題,分派給相應部門分別完成或協作完成。由省大數據局或其授權的專業機構匯總來自各部門的分析結果,形成報告并對成果加以利用。
上述兩個階段可以有適度的重疊。
不容忽視的數據質量治理
數據質量問題是普遍存在的,并且一定會在大數據環節暴露出來,并有可能被放大,引起連鎖反應,造成不良后果,嚴重影響政務大數據生態的健康發展。
不宜過度依賴數據清洗技術,因為數據清洗是對數據做“減法”,是權宜之計。
需要從數據生產環節入手,采取可行、有效、成本低、難度小、能夠治本的數據質量治理方案。
結論:良好的政務大數據生態不是“硬造”出來的,而是在適合的機制-服務模式下,自然而然地“生長”出來的。