













聊聊C語言中使用頻率較高的指針與數組

定義
指針:C語言中某種數據類型的數據存儲的內存地址,例如:指向各種整型的指針或者指向某個結構體的指針。
數組:若干個相同C語言數據類型的元素在連續內存中儲存的一種形態。
數組在編譯時就已經被確定下來,而指針直到運行時才能被真正的確定到底指向何方。所以數組的這些身份(內存)一旦確定下來就不能輕易的改變了,它們(內存)會伴隨數組一生。
而指針則有很多的選擇,在其一生他可以選擇不同的生活方式,比如一個字符指針可以指向單個字符同時也可代表多個字符等。
指針和數組在C語言中使用頻率是很高的,在極個別情況下,數組和指針是“通用的”,比如數組名表示這個數組第一個數據的指針。
如下代碼:
#include <stdio.h>
char array[4] = {1, 2, 3, 4};
int main(void)
{
char * p;
int i = 0;
p = array;
for (; i < 4; i++)
{
printf("*array = %d\n", *p++);
}
return (0);
}
這里我們將數組名array作為數組第一個數據的指針賦值給p。但是不能寫成*array++。準確來說數組名可以作為右值,不能作為左值(左值和右值的概念這里不再展開講解)。
數組名的值其實是一個指針常量,這樣我想你就明白了數組名為什么不能做為左值了。如果想用指針p訪問array的下面2的數據,以下寫法是合法的。
char data;
/*第一種寫法*/
p = array;
data = p[2];
/*第二種寫法*/
p = array;
data = *(p+2);
/*第三種寫法*/
p = array +
指針與二維數組
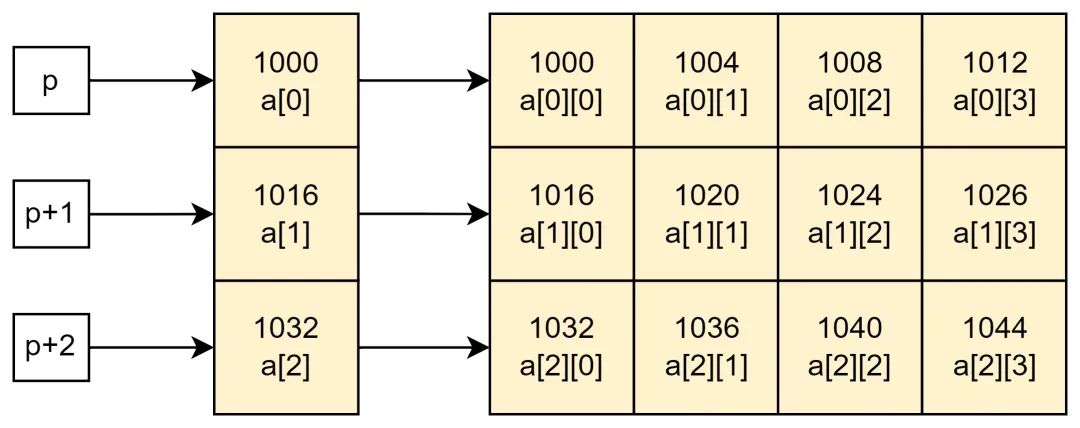
先說一下二維數組,二維數組在概念上是二維的,有行和列,但在內存中所有的數組元素都是連續排列的,它們之間沒有“縫隙”。以下面的二維數組 a 為例:
int a[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} };
從概念上理解,a 的分布像一個矩陣:
- 0 1 2 3。
- 4 5 6 7。
- 8 9 10 11。
但是內存是連續的,沒有這樣的“矩陣內存”,所以二維數組a分布是連續的一塊內存。


C語言允許把一個二維數組分解成多個一維數組來處理。對于數組 a,它可以分解成三個一維數組,即 a[0]、a[1]、a[2]。每一個一維數組又包含了 4 個元素,例如 a[0] 包含 a[0][0]、a[0][1]、a[0][2]、a[0][3]。那么定義如下指針如何理解呢?
int (*p)[4];
括號中的*表明 p 是一個指針,它指向一個數組,數組的類型為int [4],這正是 a 所包含的每個一維數組的類型。那么和下面定義有什么區別呢?
int *p[4];
這里就要先說明*和[]的優先級了,[]的優先級是高于*的,所以int *p[4];等同于int *(p[4]);。所以它是一個指針數組。這里很繞,總接下:
int (*p)[4];是數組指針,它指向二維數組中每個一維數組的類型,它指向的是一個數組。
int *p[4];是指針數組,它是一個數組,數組中每個數是指向int型的指針。
指針數組與數組指針
對于指針數組,說的已經很明確了,不再詳細講解,下面說一下數組指針。舉例看一下:
#include <stdio.h>
int main()
{
int a[3][4] = {{0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11}};
int(*p)[4];
p = a;
printf("%d\n", sizeof(*(p + 1)));
return (0);
}
對于數組指針p如下:
 那么printf("%d\n", sizeof(*(p +
1)));的結果就是16。如果想打印a[1][0]的值,代碼如下:
那么printf("%d\n", sizeof(*(p +
1)));的結果就是16。如果想打印a[1][0]的值,代碼如下:
printf("%d\n", *(*(p + 1)));
如果想打印a[1][1]的值,代碼如下:
printf("%d\n", *(*(p + 1)+1));
這個代價自行體會,p是數組指針,它指向的是一個數組,所以對獲取它指向的值,也就是*p,是指向一個數組還是一個值,指向a[0]。獲取獲取a[0][0],就需要寫成**p。
對指針進行加法(減法)運算時,它前進(后退)的步長與它指向的數據類型有關,p 指向的數據類型是int [4],那么p+1就前進 4×4 = 16 個字節,p-1就后退 16 個字節,這正好是數組 a 所包含的每個一維數組的長度。也就是說,p+1會使得指針指向二維數組的下一行,p-1會使得指針指向數組的上一行。
最后再次捋一下數組指針和指針數組。
int *p1[4];是指針數組。
int (*p2)[4];是數組指針。
“[]”的優先級比“*”要高。
對于指針數組,p1先和“[]”結合,構成一個數組的定義,數組名為p1,int *修飾的是數組的內容,即數組的每個元素。那么它本質是一個數組,這個數組里有4個指向int類型數據的指針。
對于數組指針,“()”的優先級比“[]”高,“*”號和p2 構成一個指針的定義,指針變量名為p2,int 修飾的是數組的內容,即數組的每個元素。數組在這里并沒有名字,是個匿名數組。那么它本質是一個指針,它指向一個包含4個int 類型數據的數組。
既然深入談了指針數組和數組指針,就多聊一下。
#include <stdio.h>
int main()
{
char a[5] = {'A', 'B', 'C', 'D'};
char(*p3)[5] = &a;
char(*p4)[5] = a;
return 0;
}
上面代碼是編譯編譯是報了waring的,報警如下:


注意:不同的編譯器編譯結果可能不同,我的編譯方法請參考《使用vscode編譯C語言》。p3 這個定義的“=”號兩邊的數據類型完全一致,而p4 這個定義的“=”號兩邊的數據類型就不一致了。左邊的類型是指向整個數組的指針,右邊的數據類型是指向單個字符的指針。所以才有了上面的警告。
但由于&a 和a 的值一樣,而變量作為右值時編譯器只是取變量的值,所以運行并沒有什么問題。不過編譯器仍然警告你別這么用。
再舉一個栗子:
int vector[10];
int matrix[3][10];
int *vp,*vm;
vp = vector;
vm = matrix;
上面的代碼第5行是錯誤的,因為vm是指向整型的指針,但是matrix不是指向正向的指針,他是指向整型數組的指針。下面是正確的寫法:
int matrix[3][10];
int (*vm)[10];
vm = matrix;
數組指針的應用
上面說了那么多,可能大部分開發者用不到,數組指針在很多時候都是可以代替二維數組的,有些程序員喜歡用指針數組來代替多維數組,一個常見的用法就是處理字符串。
#include <stdio.h>
char *Names[] =
{
"Bill",
"Sam",
"Jim",
"Paul",
"Charles",
0};
void main()
{
char **nm = Names;
while (*nm != 0)
printf("%s \n", *nm++);
}
具體運行我就不講解了,運行結果如下:

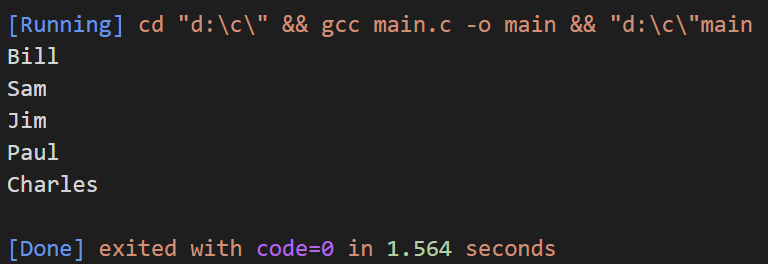
注意數組中的最后一個元素被初始化為0,while循環以次來判斷是否到了數組末尾。具有零值的指針常常被用做循環數組的終止符。
這種零值的指針稱為為空指針(NULL)。采用空指針作為終止符,在增刪元素時就不必改動遍歷數組的代碼,因為此時數組仍然以空指針作為結束。
操作
寫到這里想到一個“操作”,先看下面代碼是否正確。
p[-1]=0;
初看這句代碼,覺得奇怪,甚至覺得它就是錯誤,日常C語言開發基本有見到小標是負數的,但是仔細想想沒有哪一本書說過下標能為負數的。看下面代碼:
void main()
{
int data[4] = {0, 1, 2, 3};
int *p;
p = data +2;
printf("p[-1] is %d\n",p[-1]);
printf("*(p-1) is %d\n",*(p-1));
}
運行結果如下:
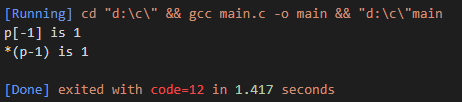
不僅可以編譯通過,還能正確的輸出結果為1。這表明,C的下標引用和間接訪問表達式是一樣的。當然不鼓勵這種操作,代碼需要很強的可讀性,而不是這樣的操作,這里只是演示下標引用和簡介表達式的關系。


















