













MySQL 多表聯合查詢有何講究?
今天我們來聊聊微信中的多表聯合查詢,應該是小表驅動大表還是大表驅動小表?
1. in VS exists
在正式分析之前,我們先來看兩個關鍵字 in 和 exists。
假設我現在有兩張表:員工表和部門表,每個員工都有一個部門,員工表中保存著部門的 id,并且該字段是索引;部門表中有部門的 id、name 等屬性,其中 id 是主鍵,name 是唯一索引。
這里我就直接使用 vhr 中的表來做試驗,就不單獨給大家數據庫腳本了,小伙伴們可以查看 vhr 項目(https://github.com/lenve/vhr)獲取數據庫腳本。
假設我現在想查詢技術部的所有員工,我有如下兩種查詢方式:
第一種查詢方式是使用 in 關鍵字來查詢:
select * from employee e where e.departmentId in(select d.id from department d where d.name='技術部') limit 10;
這個 SQL 很好理解,相信大家都能懂。查詢的時候也是先查詢里邊的子查詢(即先查詢 department 表),然后再執行外表的查詢,我們可以看下它的執行計劃:

可以看到,首先查詢部門表,有索引就用索引,沒有索引就全表掃描,然后查詢員工表,也是利用索引來查詢,整體上效率比較高。
第二種是使用 exists 關鍵字來查詢:
select * from employee e where exists(select 1 from department d where d.id=e.departmentId and d.name='技術部') limit 10;
這條 SQL 的查詢結果和上面用 in 關鍵字的一樣,但是查詢過程卻不一樣,我們來看看這個 SQL 的執行計劃:

可以看到,這里先對員工表做了全表掃描,然后拿著員工表中的 departmentId 再去部門表中進行數據比對。上面這個 SQL 中,子查詢有返回值,就表示 true,沒有返回值就表示 false,如果為 true,則這個員工記錄就保留下來,如果為 false,則這個員工記錄會被拋棄掉。所以在子查詢中的可以不用 SELECT *,可以將之改為 SELECT 1 或者其他,MySQL 官方的說法是在實際執行時會忽略SELECT 清單,因此寫啥區別不大。
對比兩個查詢計劃中的掃描行數,我們就能大致上看出差異,使用 in 的話,效率略高一些。
如果用 in 關鍵字查詢的話,先部門表再員工表,一般來說部門表的數據是要小于員工表的數據的,所以這就是小表驅動大表,效率比較高。
如果用 exists 關鍵字查詢的話,先員工表再部門表,一般來說部門表的數據是要小于員工表的數據的,所以這就是大表驅動小表,效率比較低。
總之,就是要小表驅動大表效率才高,大表驅動小表效率就會比較低。所以,假設部門表的數據量大于員工表的數據量,那么上面這兩種 SQL,使用 exists 查詢關鍵字的效率會比較高。
2. 為什么要小表驅動大表
在 MySQL 中,這種多表聯合查詢的原理是:以驅動表的數據為基礎,通過類似于我們 Java 代碼中寫的嵌套循環 的方式去跟被驅動表記錄進行匹配。
以第一小節的表為例,假設我們的員工表 E 表是大表,有 10000 條記錄;部門表 D 表是小表,有 100 條記錄。
假設 D 驅動 E,那么執行流程大概是這樣:
for 100 個部門{
匹配 10000 個員工(進行B+樹查找)
}那么查找的總次數是 100+log10000。
假設 E 驅動 D,那么執行流程大概是這樣:
for 10000 個員工{
匹配 100 個部門(進行B+樹查找)
}那么總的查找次數是 10000+log100。
從這兩個數據對比中我們就能看出來,小表驅動大表效率要高。核心的原因在于,搜索被驅動的表的時候,一般都是有索引的,而索引的搜索就要快很多,搜索次數也少。
3. 沒有索引咋辦?
前面第二小節我們得出的結論有一個前提,就是驅動表和被驅動表之間關聯的字段是有索引的,以我們前面的表為例,就是 E 表中保存了 departmentId 字段,該字段對應了 D 表中的 id 字段,而 id 字段在 D 表中是主鍵索引,如果 id 不是主鍵索引,就是一個普通字段,那么 D 表豈不是也要做全表掃描了?那個時候 E 驅動 D 還是 D 驅動 E 差別就不大了。
對于這種被驅動表上沒有可用索引的情況,MySQL 使用了一種名為 Block Nested-Loop Join (簡稱 BNL)的算法,這種算法的步驟是這樣:
- 把 E 表的數據讀入線程內存 join_buffer 中。
- 掃描 D 表,把 D 表中的每一行取出來,跟 join_buffer 中的數據做對比,滿足 join 條件的,作為結果集的一部分返回。
小伙伴們來看下,如果我把 E 表中 departmentId 字段上的索引刪除,再把 D 表中的 id 字段上的主鍵索引也刪除,此時我們再來看看如下 SQL 的執行計劃:

可以看到,此時 E 表和 D 表都是全表掃描,另外需要注意,這些比對操作都是在內存中,所以執行效率都是 OK 的。
但是,既然把數據都讀入到內存中,內存中能放下嗎?內存中放不下咋辦?我們看上面的查詢計劃,對 E 表的查詢中,Extra 中還出現了 Using join buffer (Block Nested Loop),Block 不就有分塊的意思嗎!所以這意思就很明確了,內存中一次放不下,那就分塊讀取,先讀一部分到內存中,比對完了再讀另一部分到內存中。
通過如下指令我們可以查看 join_buffer 的大小:
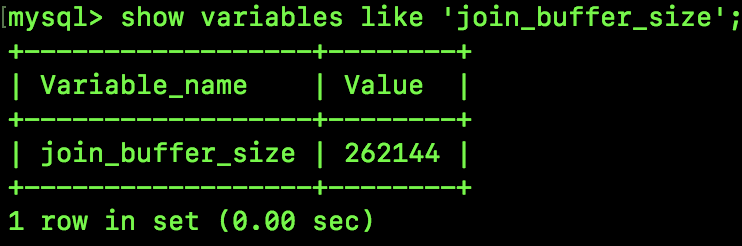
262144/1024=256KB
默認大小是 256 KB。
我現在把這個值改大,然后再查看新的執行計劃,如下:
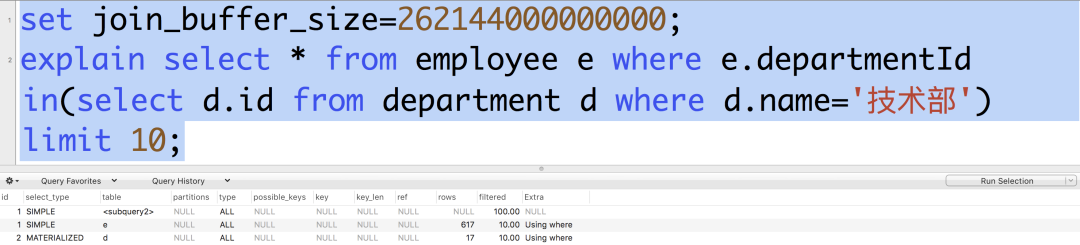
大家看到,此時已經沒有 Using join buffer (Block Nested Loop) 提示了。
總結一下:
- 如果 join_buffer 足夠大,一次性就能讀取所有數據到內存中,那么大表驅動小表還是小表驅動大表都無所謂了。
- 如果 join_buffer 大小有限,那么建議小表驅動大表,這樣即使要分塊讀取,讀取的次數也少一些。
不過老實說,這種沒有索引的多表聯合查詢效率比較低,應該盡量避免。
綜上所述,在多表聯合查詢的時候,建議小表驅動大表。














