SQL語句在MySQL中是如何被執行的?
前言
相信大家用了這么久的MySQL,一定很好奇自己寫的SQL是如何執行并返回結果的,今天我們就來一層一層剝開MySQL這顆洋蔥。
首先我們通過一張圖來了解下整個過程,然后再開始一步一步解析。
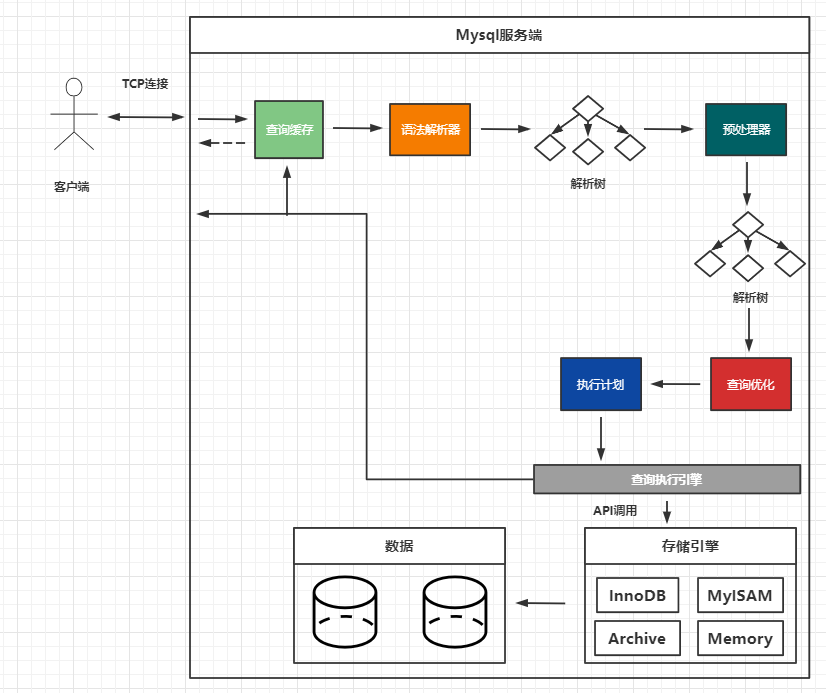
第一步:客戶端發送SQL語句到MySQL服務端
假如項目中用到了Mybatis來操作數據庫,那么Mybatis就會通過JDBC來連接數據庫,并發送語句給數據庫,因為一般運行Web后臺服務的機器和MySQL服務都是物理上隔開的,是一個分布式架構,所以需要通過網絡來訪問,JDBC采用TCP連接的方式與MySQL服務端進行通信,通信的內容包括發送語句、接收執行結果等。雖然TCP是全雙工的,但是Mysql的TCP是半雙工的,這意味著同一時刻要么客戶端在發送數據,要么服務端在發送數據。
第二步:驗證連接合法性
JDBC與數據庫建立的連接的時候,會要求輸入用戶名和密碼,Mysql需要驗證用戶名是否存在,密碼是否正確。驗證通過后,再根據mysql.user表中的host字段來驗證客戶端IP是否是允許的IP,這個host字段相當于一個白名單。
前面的合法性都通過后,JDBC才會發送實際的SQL語句給MySQL服務端。
第三步:查詢緩存
像上面這種SELECT語句,MySQL服務端收到這個SQL時,如果開啟了查詢緩存,就會根據SQL語句在查詢緩存中查找,查找成功就直接返回查詢緩存中的結果給客戶端,而不會執行下面這些操作。
請注意,這里的查找方式是根據SQL語句進行hash運算,只要SQL中有一個字節不同都不會命中緩存。
第四步:語法解析和預處理
當查詢緩存沒有命中時,才會開始進行語法解析和預處理。語法解析就像一個編譯程序一樣,根據語句生成語法樹,并檢查語法樹中的關鍵字是否正確,順序是否正確,引號是否前后匹配等。
經過語法解析后,預處理就會檢查sql中的表、列是否存在,列名是否有歧義等,同時預處理還會對SQL進行權限認證,比如該用戶是否有SELECT權限、INSERT權限..., 是否有對應數據庫的權限、表的權限等等。
第五步:查詢優化
查詢優化主要分為兩部分,一是靜態優化二是動態優化。靜態優化可以把語句中一些where條件進行等價交換,比如:WHERE 1=1 AND a > 2將被替換為WHERE a > 2;靜態優化不依賴sql語句的具體值,就像Java靜態編譯器的語法糖一樣。
動態優化:因為動態優化以頁為最小單元來評估成本,所以需要分析SQL語句所對應的表的索引頁或者數據頁的數量,以此來確定是走索引還是全表掃描。這些信息都是通過存儲引擎來獲得的,所以如果存儲引擎給出的結果不精確,那么查詢優化的執行計劃可能就不是最優的。
因為一條sql可以選擇的執行方式有很多種,比如一張表里有多個索引,SQL語句涉及多個表的連接查詢,那么得到上述信息后,就需要評估使用哪些索引、哪個表關聯的順序是最優的,并以此來生成一條執行計劃。這部分也是Mysql服務層最復雜的地方,因為需要考量的因素有很多,這里筆者只是列出了一小部分。
第六步:調用存儲引擎執行
其實在MySQL中,真正決定怎么存儲數據和查詢數據的組件是存儲引擎。所以在第五步中得到了執行計劃后,MySQL會調用表所對應的存儲引擎的API,來執行真正的查詢。Mysql定義了一系列存儲引擎接口,來讓編寫存儲引擎的人來實現,所以只要符合接口定義的存儲引擎都是可以放入MySQL中去使用的。其中使用最廣泛的引擎莫過于InnoDB,InnoDB是一個支持事務、支持崩潰快速恢復的高性能存儲引擎。
Mysql服務層和存儲引擎層最大的區別是:服務層實現了一些不依賴于具體存儲引擎的通用操作,比如上面的連接驗證、SQL驗證這些。而存儲引擎則完成具體的查詢存儲操作,所以好的存儲引擎是Mysql的關鍵。
第七步:將結果返回給客戶端
容易想到的一種方式是MySQL服務端先把查詢結果緩存到內存中,然后再一次性發送給客戶端,可實際上不是這樣的。實際是拿到符合條件的第一條數據就返回給客戶端,這是一個增量過程。這樣做的原因,是可以緩解服務端的內存壓力。
如果開啟了查詢緩存,并且語句是UPDATE、DELETE、INSERT之類的操作,那么這個時候也會更新查詢緩存。
總結
在整個過程中,最復雜的部分是第五步的查詢優化和第六步中具體的存儲引擎,實現細節是造就了MySQL長盛不衰的原因。如果想要優化MySQL的性能,有幾步可以優化:
客戶端使用連接池,這樣可以讓連接復用,因為MySQL每接收一個連接都要用一個線程去處理,和其他Web服務器的連接池解決的問題一樣,這里也可以解決。
查詢緩存雖然在查詢時可以避免很多后續操作的成本,但是維護它的成本也挺高的,因為每次UPDATE、DELETE、INSERT都需要互斥地更新對應表的查詢緩存,這會成為MySQL的可擴展性瓶頸。根據阿姆達爾定律,決定一個系統能否水平擴展的是程序串行的部分。在MySQL8.0以上版本中,默認禁用了查詢緩存。所以除非你能確定查詢緩存確實對吞吐量有幫助,否則禁用查詢緩存是個好建議。
默認情況下,客戶端在第七步的接收過程中,其實是在自己的內存里緩存了全部結果之后,才會解除阻塞,這些會創建很多對象,當并發增高時,可能會引起JVM的OOM。所以這里可以改為每次只接收部分數據,處理完后再接收部分。但這里服務端對于資源都是持有狀態,所以是一個空間和時間上的權衡。
如果有必要,你可以干涉第五步的查詢優化過程,MySQL提供一些hint語句,比如強制走規定的關聯表順序或者強制使用某些索引。但是大多數情況下,請不要以為自己比查詢優化器更聰明,使用推薦的方案可能更好。
設計一個好的索引對于查詢的性能影響非常之大,所以對于使用關系型數據庫來說,索引設計是非常重要的一環。