聊聊大數據技術現狀和分類
隨著社交媒體、物聯網和多媒體應用等各種來源產生的海量數據的誕生,大數據已經成為一個重要的研究領域。大數據在許多決策和預測領域發揮了關鍵作用,如推薦系統、商業分析、醫療保健、網絡展示廣告、臨床醫生、交通、欺詐檢測和旅游營銷。Hadoop、Storm、Spark、Flink、Kafka和Pig等各種大數據工具的研究和工業界的快速發展,使得大規模數據得以分發、交流和處理[1]。大數據應用程序使用大數據分析技術來高效地分析大數據。
然而,由于大數據在處理和應用方面的挑戰,開發人員選擇合適的大數據工具來開發大數據系統非常困難。因此,本文提出了一個分類方案,根據不同的數據處理方式對大數據工具進行分類。
大數據工具的分類
大數據計算主要有三種工具,即批處理工具、流處理工具和混合處理工具。大多數批處理數據分析框架都基于Apache Hadoop。流式數據分析框架主要是實時應用中使用的Storm、S4和Flink。混合處理工具利用批處理和流處理的優點來計算大量數據。
批處理工具
批處理建模并將數據湖的文件轉換為批處理視圖,為分析用例做好準備。它負責安排和執行批量迭代算法,如排序、搜索、索引或更復雜的算法,如PageRank、貝葉斯分類或遺傳算法。批處理主要由MapReduce編程模型表示。
Apache Hadoop是一個眾所周知的批處理框架,它支持在集群上分布式存儲和處理大型數據。它是一個基于Java的開源框架,被Facebook、Yahoo和Twitter用于存儲和處理大數據。Hadoop主要由兩個組件組成:(1)Hadoop分布式文件系統(HDFS),其中集群節點之間的數據存儲是分布式的;(2)Hadoop MapReduce引擎,它將數據處理分配給集群的節點[2]。
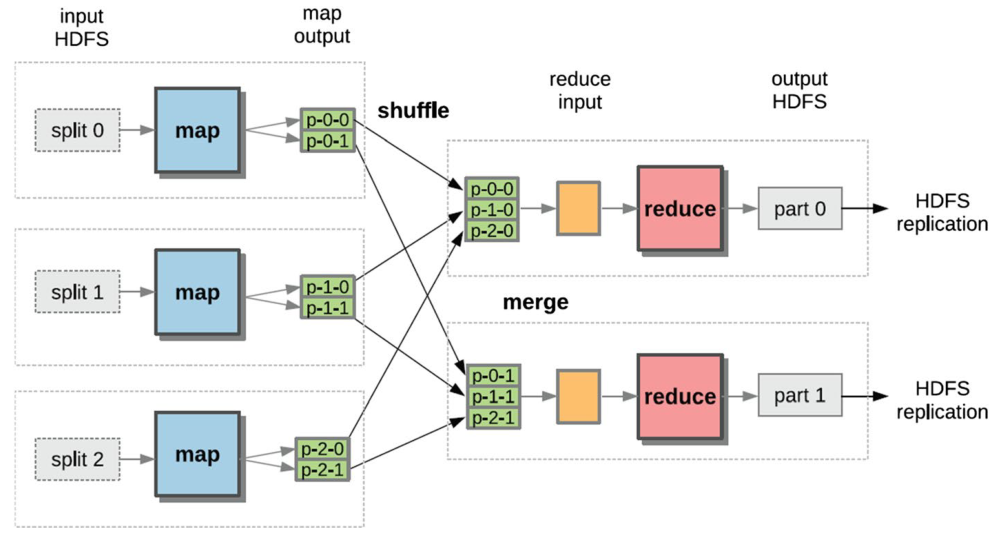
圖 1 Hadoop的MapReduce
Apache Pig是Hadoop生態系統的一個不可或缺的組件,它通過在Hadoop上并行執行數據流來減少數據分析時間。Pig是一種結構化查詢語言(SQL),被LinkedIn、Twitter、Yahoo等大型組織使用。該平臺的腳本語言稱為Pig Latin,它將MapReduce中的編程復雜性從其他語言(如Java)抽象為高級語言。Pig是一個最完整的平臺,因為它可以通過直接調用用戶定義函數(UDF)來調用JavaScript、Java、Jython和JRuby等多種語言的代碼。因此,開發人員可以使用Pig在Hadoop中完成所有必需的數據操作。Pig可以作為一個具有相當多并行性的組件,用于構建復雜而繁重的應用程序。
Flume被用作向Hadoop提供數據的工具。與處理框架一起,需要一個消息傳遞層來訪問和轉發流數據。Apache Flume是提供這一功能的較為成熟的選項之一。Flume一直是數據饋送的著名應用程序。它很好地嵌入到整個Hadoop生態系統中,并獲得了所有商業Hadoop發行版的支持。這使得Flume成為開發者的主要選擇[3]。
流處理工具
Hadoop是為批處理而設計的。Hadoop是一個多用途引擎,但由于其延遲,它不是一個實時和高性能的引擎。在一些流數據應用中,如日志文件處理、工業傳感器和遠程通信,需要實時響應和處理流式大數據。因此,有必要對流處理進行實時分析。流式大數據需要實時分析,因為大數據具有高速、大容量和復雜的數據類型,對于Map/Reduce框架將是一個挑戰。因此,Storm、S4、Splunk和Apache Kafka等流處理的實時大數據平臺已被開發為第二代數據流處理平臺用于實時分析數據,實時處理意味著連續數據處理需要極低的響應延遲[4]。
Storm是實時分析中最受認可的數據流處理程序之一,專注于可靠的消息處理。Storm是一個免費、開源的分布式流媒體處理環境,用于開發和運行分布式程序,處理源源不斷的數據流。因此,可以說Storm是一個開源、通用、分布式、可擴展和部分容錯的平臺,可以可靠地處理無限的數據流以進行實時處理。Storm的一個優點是,開發人員可以專注于使用穩定的分布式進程,同時將分布式/并行處理的復雜性和技術挑戰(如構建復雜的恢復機制)委托給框架。Storm是一個復雜的事件處理器和分布式計算框架,基本上是用Clojure編程語言編寫的。它是一個分布式實時計算系統,用于快速處理大數據流。Storm是一個分布式/并行框架,由Nimbus、Supervisor和Zookeeper組成,如圖2所示。Storm集群主要由主節點和工作節點組成,由Zookeeper進行協調。
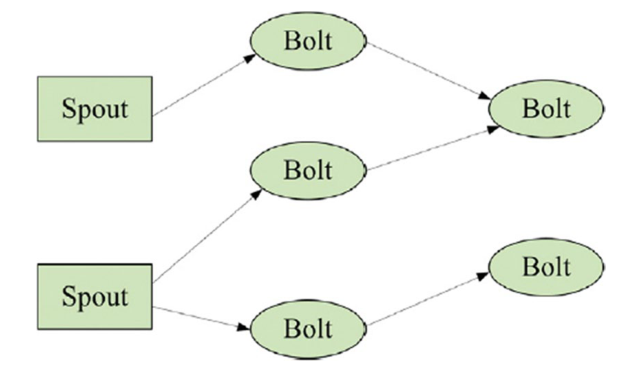
圖2 Storm拓撲的示例
S4是一個受MapReduce模型啟發的分布式流處理平臺。流的操作由用戶代碼和用XML描述的配置作業指定。S4是一個通用的、容錯的、可擴展的、分布式的、可插拔的計算框架,程序員可以輕松地開發用于處理連續無界數據流的應用程序。它最初由Yahoo 2010年發布,并從2011年起成為Apache孵化器項目。S4允許程序員基于幾個有競爭力的特性開發應用程序,包括可伸縮性、分散性、健壯性、可擴展性和集群管理。S4是用Java編寫的。S4作業的任務是模塊化和可插拔,以便于動態處理大規模流數據。S4使用Apache ZooKeeper來管理集群,就像Storm一樣。
Kafka是一個開源的分布式流媒體框架,最初由LinkedIn在2010年開發。它是一個靈活的發布-訂閱消息傳遞系統,旨在快速、可擴展,并通常用于日志收集。Kafka是用Scala和Java編寫的。它有一個多生產者管理系統,能夠從多個來源獲取消息。通常,Kafka的數據分區和保留功能使其成為容錯事務收集的有用工具。這是因為應用程序可以開發和訂閱記錄流,具有容錯保證,并且可以在記錄流出現時對其進行處理。
Flink是一個流式處理工具,旨在解決微批量模型衍生的問題。Flink還支持使用Scala和Java中的編程抽象進行批處理數據處理,盡管它被視為流處理的特例。在Flink中,每個作業都作為流計算執行,每個任務都作為循環數據流執行,并進行多次迭代。Flink還提供了一種復雜的容錯機制,以一致地恢復數據流應用程序的狀態。該機制生成分布式數據流和操作員狀態的一致快照。如果出現故障,系統可以退回到這些快照。FlinkML的目標是為Flink用戶提供一套可伸縮的機器學習算法和直觀的API。
Apache Spark是Hadoop最新的替代方案。它包括一個名為MLlib的額外組件,這是一個面向機器學習算法的庫,例如:聚類、分類、回歸,甚至數據預處理[6]。由于Spark的容量,批量和流式分析可以在同一平臺上完成。Spark的開發是為了克服Hadoop的缺點,即它沒有針對迭代算法和交互式數據分析進行優化,后者對同一組數據執行多個操作。Spark被定義為下一代分布式計算框架的核心,由于其內存密集型方案,它可以在內存中快速處理大容量數據集。
混合處理工具
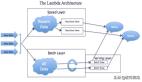
混合處理使大數據平臺進入第三代成為可能,因為它是大數據應用中許多領域所必需的。該范例綜合了基于Lambda架構的批處理和流處理范例。Lambda體系結構是一種數據處理體系結構,旨在通過利用批處理和流處理方法來處理大量數據。這個范例的高級架構包含三層。批處理層管理已存儲在分布式系統中且不可更改的主數據集,服務層加載并在數據存儲中公開批處理層的視圖以供查詢,而速度層只處理低延遲的新數據。最后,通過批處理和實時視圖的組合,將完整的結果合并[7]。
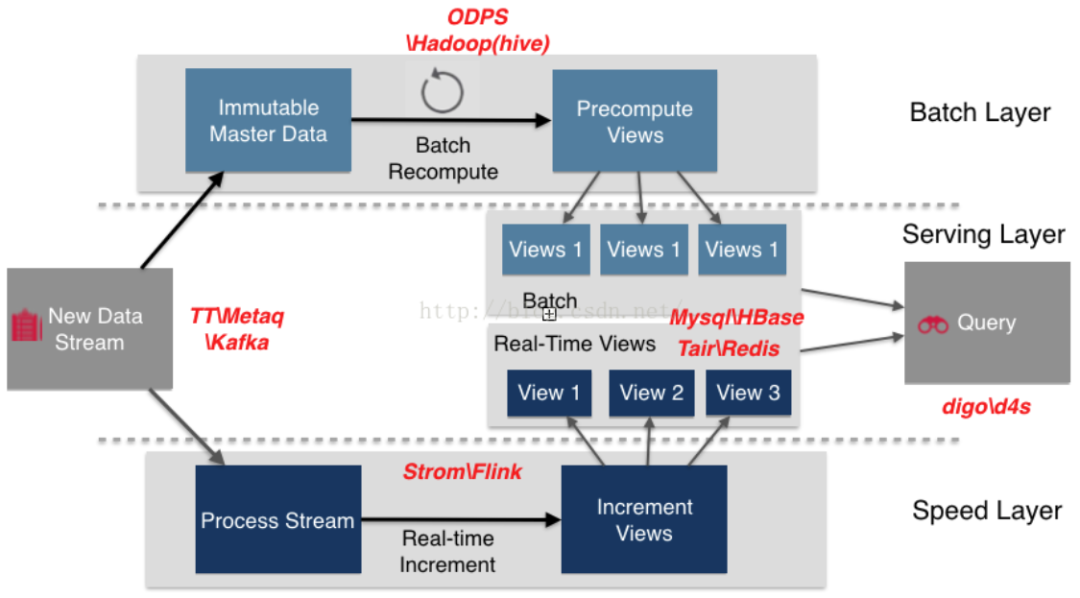
圖3 Lambda架構
引 用
[1] Mohamed A, Najafabadi M K, Wah Y B, et al. The state of the art and taxonomy of big data analytics: view from new big data framework[J]. Artificial Intelligence Review, 2020, 53(2): 989-1037.
[2] Singh H, Bawa S. A MapReduce-based scalable discovery and indexing of structured big data[J]. Future generation computer systems, 2017, 73: 32-43.
[3] Bharti S K, Vachha B, Pradhan R K, et al. Sarcastic sentiment detection in tweets streamed in real time: a big data approach[J]. Digital Communications and Networks, 2016, 2(3): 108-121.
[4] Manco G, Ritacco E, Rullo P, et al. Fault detection and explanation through big data analysis on sensor streams[J]. Expert Systems with Applications, 2017, 87: 141-156.
[5] Tennant M, Stahl F, Rana O, et al. Scalable real-time classification of data streams with concept drift[J]. Future Generation Computer Systems, 2017, 75: 187-199.
[6] Ai W, Li K, Li K. An effective hot topic detection method for microblog on spark[J]. Applied Soft Computing, 2018, 70: 1010-1023.
[7] Hasani Z, Kon-Popovska M, Velinov G. Lambda architecture for real time big data analytic[J]. ICT Innovations, 2014: 133-143.