新手應該知道的 Kubernetes 架構
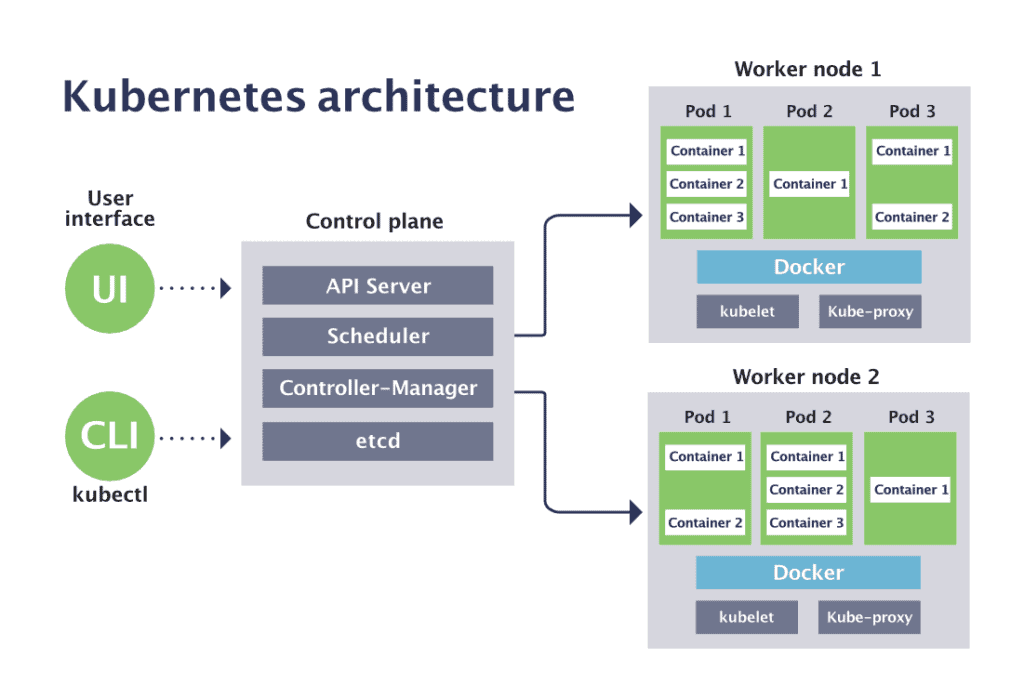
控制平面組件
ETCD
etcd 是一個快速、分布式、一致的鍵值存儲,用作持久存儲 Kubernetes 對象數據(如 pod、replication controllers, secrets, services 等)的后備存儲。實際上,etcd 是 Kubernetes 存儲集群狀態和元數據的唯一地方。唯一直接與 etcd 對話的組件是 Kubernetes API Server。所有其他組件通過 API Server 間接讀取和寫入數據到 etcd。
Etcd 還實現了一個監視功能,它提供了一個基于事件的接口,用于異步監控鍵的更改。一旦密鑰被更改,它的觀察者就會收到通知。API Server 組件在很大程度上依賴于此來獲得通知并將 etcd 的當前狀態移動到所需狀態。
etcd 實例的數量應該是奇數嗎?
在 HA 環境中,您通常會運行 3、5 或 7 個 etcd 實例,但為什么呢?由于 etcd 是分布式數據存儲,因此可以水平擴展它,但您還需要確保每個實例中的數據是一致的,為此,您的系統需要就狀態達成共識。Etcd 為此使用了RAFT 共識算法。
該算法需要多數(或仲裁)集群才能進入下一個狀態。如果您只有 2 個 ectd 實例,如果其中任何一個失敗,則 etcd 集群無法轉換到新狀態,因為不存在多數,并且在 3 個實例的情況下,一個實例可能會失敗并且可以達到多數的實例仍然可用。
API Server
API Server 是 Kubernetes 中唯一與 etcd 直接交互的組件。Kubernetes 以及客戶端(kubectl)中的所有其他組件都必須通過 API Server 來處理集群狀態。API Server 提供以下功能:
- 提供在 etcd 中存儲對象的一致方式。
- 執行這些對象的驗證,以便客戶端無法存儲配置不正確的對象,如果它們直接寫入 etcd 數據存儲區可能會發生這種情況。
- 提供 RESTful API 來創建、更新、修改或刪除資源。
- 提供樂觀并發鎖定,因此在并發更新的情況下,對對象的更改永遠不會被其他客戶端覆蓋。
- 對客戶端發送的請求執行身份驗證和授權。它使用插件提取客戶端的用戶名、用戶 ID 和用戶所屬的組,并確定經過身份驗證的用戶是否可以對請求的資源執行請求的操作。
- 如果請求試圖創建、修改或刪除資源,則執行準入控制。示例:AlwaysPullImagesDefaultStorageClass、ResourceQuota 等。
- 為客戶端實現監視機制(類似于 etcd)以監視更改。這允許調度程序和 Controller Manager 等組件以松散耦合的方式與 API Server 交互。
Controller Manager
在 Kubernetes 中,控制器是監控集群狀態的控制循環,然后根據需要進行更改或請求更改。每個控制器都嘗試將當前集群狀態移動到更接近所需狀態。控制器跟蹤至少一種 Kubernetes 資源類型,并且這些對象有一個表示所需狀態的規范字段。
控制器示例:
- Replication Manager(ReplicationController 資源的控制器)
- ReplicaSet、DaemonSet 和 Job 控制器
- Deployment 控制器
- StatefulSet 控制器
- node 控制器
- service 控制器
- endpoints 控制器
- namespace 控制器
- PersistentVolume 控制器
控制器使用監視機制來獲得更改通知。他們監視 API Server 對資源的更改并針對每個更改執行操作,無論是創建新對象還是更新或刪除現有對象。大多數時候,這些操作包括創建其他資源或自己更新被監視的資源,但是由于使用監視并不能保證控制器不會錯過任何事件,它們還會定期執行重新列出操作以確保沒有錯過了任何東西。
Controller Manager 還執行生命周期功能,例如命名空間創建和生命周期、事件垃圾回收、終止 pod 垃圾回收、級聯刪除垃圾回收、節點垃圾回收等。
Scheduler
調度程序是一個控制平面進程,它將 pod 分配給節點。它監視沒有分配節點的新創建的 pod,并且對于調度程序發現的每個 pod,調度程序負責為該 pod 找到運行的最佳節點。
滿足 Pod 調度要求的節點稱為可行節點。如果沒有合適的節點,則 pod 將保持未調度狀態,直到調度程序能夠放置它。一旦找到可行節點,它就會運行一組函數來對節點進行評分,并選擇得分最高的節點。然后它會通知 API Server 有關所選節點的信息,此過程稱為綁定。
節點的選擇分為兩步:
- 過濾所有節點的列表以獲取 pod 可以調度到的可接受節點列表。(例如,PodFitsResources 過濾器檢查候選節點是否有足夠的可用資源來滿足 Pod 的特定資源請求)
- 對從第 1 步獲得的節點列表進行評分并對它們進行排名以選擇最佳節點。如果多個節點得分最高,則使用循環法確保 pod 均勻地部署在所有節點上。
調度決策需要考慮的因素包括:
- Pod 對硬件/軟件資源的請求?節點是否報告內存或磁盤壓力情況?
- 該節點是否具有與 pod 規范中的節點選擇器匹配的標簽?
- 如果 pod 請求綁定到特定的主機端口,該端口是否已在該節點上占用?
- pod 是否容忍節點的污點?
- pod 是否指定節點親和性或反親和性規則?等。
調度程序不會指示所選節點運行 pod。Scheduler 所做的只是通過 API Server 更新 pod 定義。API server 通過 watch 機制通知 Kubelet pod 已經被調度。然后目標節點上的 kubelet 服務看到 pod 已被調度到它的節點,它創建并運行 pod 的容器。
工作節點組件
Kubelet
Kubelet 是在集群中的每個節點上運行的代理,是負責在工作節點上運行的所有內容的組件。它確保容器在 Pod 中運行。
kubelet 服務的主要功能有:
- 通過在 API Server 中創建節點資源來注冊它正在運行的節點。
- 持續監控 API Server 上已調度到節點的 Pod。
- 使用配置的容器運行時啟動 pod 的容器。
- 持續監控正在運行的容器并將其狀態、事件和資源消耗報告給 API Server。
- 運行容器活性探測,在探測失敗時重新啟動容器,在容器的 Pod 從 API Server 中刪除時終止容器,并通知服務器 Pod 已終止。
kube-proxy
它在每個節點上運行,并確保一個 pod 可以與另一個 pod 對話,一個節點可以與另一個節點對話,一個容器可以與另一個容器通信等。它負責監視 API Server 以了解Service和 pod 定義的更改,以保持整個網絡配置的最新狀態。當一個Service由多個 pod 時,proxy會在這些 pod 之間負載平衡。
kube-proxy 之所以得名,是因為它是一個實際的代理服務器,用于接受連接并將它們代理到 Pod,當前的實現使用 iptables 或 ipvs 規則將數據包重定向到隨機選擇的后端 Pod,而不通過實際的代理服務器傳遞它們。
- 創建服務時,會立即分配一個虛擬 IP 地址。
- API Server 通知在工作節點上運行的 kube-proxy 代理已經創建了新服務。
- 每個 kube-proxy 通過設置 iptables 規則使服務可尋址,確保攔截每個服務 IP/端口對,并將目標地址修改為支持服務的 pod 之一。
- 監視 API Server 對服務或其端點對象的更改。
容器運行時
專注于運行容器、設置命名空間和容器的 cgroup 的容器運行時稱為低級容器運行時,專注于格式、解包、管理和共享images并提供 API 以滿足開發人員需求的容器運行時稱為高級容器運行時(容器引擎)。
容器運行時負責:
- 如果本地不可用,則從鏡像注冊表中拉取容器所需的容器鏡像。
- 將鏡像提取到寫入時復制文件系統,所有容器層相互重疊以創建合并文件系統。
- 準備容器掛載點。
- 從容器鏡像設置元數據,例如覆蓋 CMD、來自用戶輸入的 ENTRYPOINT、設置 SECCOMP 規則等,以確保容器按預期運行。
- 更改內核以向該容器分配某種隔離,例如進程、網絡和文件系統。
- 提醒內核分配一些資源限制,如 CPU 或內存限制。
- 將系統調用(syscall)傳遞給內核以啟動容器。
- 確保 SElinux/AppArmor 設置正確。