數據管理治理的發展趨勢
隨著云、本地、邊緣間的界限逐漸消失,數據管理的未來可以用四個關鍵詞來描述。
四大關鍵字
首先是分布式(Distributed),未來的數據管理將是分布式的,因為數據管理須隨數據所在的位置而進行。
其次是無服務器(Serverless),此概念較特殊、并不是指未來的數據管理不再需要服務器,而是指未來將沒有一個明確的集中式服務器。
再者是協調(Orchestrated),今天的數據會產生在不同的地方和設備上,所以須把它們協調管理。
最后就是元數據(Metadata),無論數據分散在何處,元數據均能把它們協調在一起,因此元數據是未來數據管理中非常重要的一個元素。
三大維度
總體而言,數據管理的未來發展趨勢可從三個維度來看——架構的改變、技術的轉變以及組織的衍化。
1.架構的改變(Architecture Shifts)
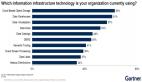
Gartner于2018年針對數據和分析的采用趨勢進行了一項調查(多選題)。結果顯示企業機構目前使用最普遍的信息基礎架構技術為“基于云平臺的數據存儲”(63%)。
一些傳統技術,例如數據倉庫(Data Warehouse)和數據庫管理系統(DBMS)仍然占著相當大的比重。這些傳統技術在未來并不會消失。
舉例而言,“數據倉庫”是一個非常廣泛的案例,未來數據的研究和分析都將需要用到該技術——主要配合在特定案例和場合中使用。
此外,未來還將有諸如“數據目錄”(Data Catalogs)這樣的技術被廣泛使用。
“數據目錄”是元數據的重要基礎,以往“數據目錄”主要用于幫助企業機構了解數據的定義和來源,但現在的趨勢是“數據目錄”可以幫助企業機構了解數據的特性、使用者以及使用場景。
因此,在數據管理的未來趨勢中,“數據目錄”將具有舉足輕重的地位。
此外,數據湖(Date Lake)已從此前放置在內部數據中心中轉變為目前可放在云端上,這是一個非常大的變化,未來諸如此類比較高端的技術均可以移至云平臺之上。
1)重“關聯”、輕“采集”


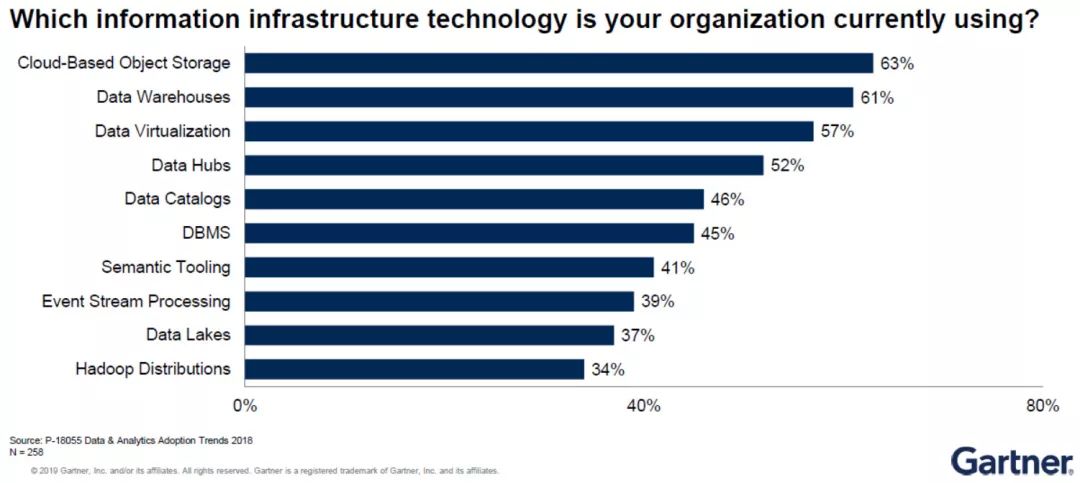
從上述調查背景可以看出,未來的數據管理和集成將會變得更加“關聯”(Connect),更少“采集”(Collect)。
當前,在數據管理上,企業機構通常重“采集”、輕“關聯”,此情形在中國尤為嚴重——即企業機構在采集和存儲數據后,并不能立即挖掘其中的價值,失去其時效性。
原因在于,從數據被“采集”到應用其價值,這中間有相當長的流程(如上左圖所示),包括描述、整理、集成、分享、治理和實施。這一長串流程對企業機構內部IT技術具有相當大的考驗。
隨著機器學習技術的引入和元數據的應用,目前數據管理和集成已開始呈現出一種新趨勢,即更加注重數據的“關聯”(如上右圖所示),也就是指無論數據是在本地、云端、某個設備感應器上或任何地方,我們都可以在數據保留在原地的情況下,將它們關聯起來,而無須采集到特定地方。
在未來增強式的數據管理的環境中,自動發掘數據、透過機器自動意識識別數據中的價值、認定有價值的數據、分析數據、自動采用適合數據的安全措施、分享數據、優化數據,最終實現在最短時間內將精準的數據發送給對的人,對于企業機構至關重要。
2)“移動性數據”成為主要案例
數據管理與集成方面的另一個趨勢是“移動性數據”(Data in Motion)。
以往,諸如交易產生后,企業機構便把數據存儲進數據庫或數據中心內,后續任務即制作報表等工作,這類的數據被稱為“靜態型”。
“移動性數據”指的是在交易過程中,企業機構就可以看到實時的數據處理——無論數據處在邊緣設備還是在數據中心內。數據始終是數據商用平臺的核心所在。
3)集中式、分布式、隨機式數據治理并存
與數據管理(Data Management)不同,數據治理(Data Governance)注重數據的使用者、使用方式、使用權限的合規性制定。
未來的“數據治理”將會非常動態——可以是集中式、分布式,亦可是隨機式。“隨機式”是指企業機構可以通過機器學習來增強數據內容以及評估用例。
舉例而言,某件物品在首次被海關征收關稅時,海關可能不知如何“治理”它。但“機器學習”引擎可以自動分辨該物品的屬性,進而據此自動幫助海關生成此件物品應該遵循的“治理”規則。
4)元數據是未來數據管理的關鍵
企業機構的數據來源不僅多種多樣(包括ERP、CRM、SCM和HCM),且用途極為廣泛(可用于外部供應商、客戶與合作伙伴,呈現方式包括圖表、報表和指示板)。
將這些來源與用途連接起來——即連通無服務器進程(Serverless Processes)和物理合并(Physical Consolidation)的關鍵橋梁就是元數據。
2.技術的轉變(Technology Changes)
Gartner預計,在2021年之前,能夠采用數據中心、數據湖或者數據倉庫這種統一戰略的企業機構,將比競爭對手多出30%的使用案例。
此外,在2023年之前,75%的數據庫將遷移至云平臺上,此舉意味著減少數據庫管理系統供應商的規模并且增加數據治理和集成的復雜性。
1)人工智能讓數據管理軟件的運行更加流暢


現在,人工智能可以幫助企業機構增強數據管理。事實上,數據管理技術的未來就是人工智能和機器學習的應用。
具體而言,有以下四方面:
第一是數據質量(Data Quality)。目前市場上有很多供應商都是在用機器學習的方式幫助企業機構擴展和增強數據的分析、清理、連接、識別、語義協調和重組。企業機構在不同數據源中管理主數據質量以往需要人為操作、費時費力,而機器學習可以使這一整串流程變得完全自動化,且準確率明顯提高。
第二是主數據管理(Master Data Management)。機器學習可以幫助企業機構配置和優化主數據,尤其在記錄匹配和算法融合方面,機器學習可以讓企業機構對主數據的管理更加便利。
第三是數據集成(Data Integration)。人工智能可以通過升級多個相同模式并根據語義分析,向企業機構告知數據源的相關性,推薦企業機構將相同的數據源進行連接,最終使得數據集成的流程更加簡化。
第四是數據庫管理系統(DataBase Management System)。人工智能技術的引入將使數據庫從存儲、索引、分區到調整、優化、修補——這一系列繁瑣的人工流程變得更加自動化。
2)動態元數據創造“自我驅動型”數據管理
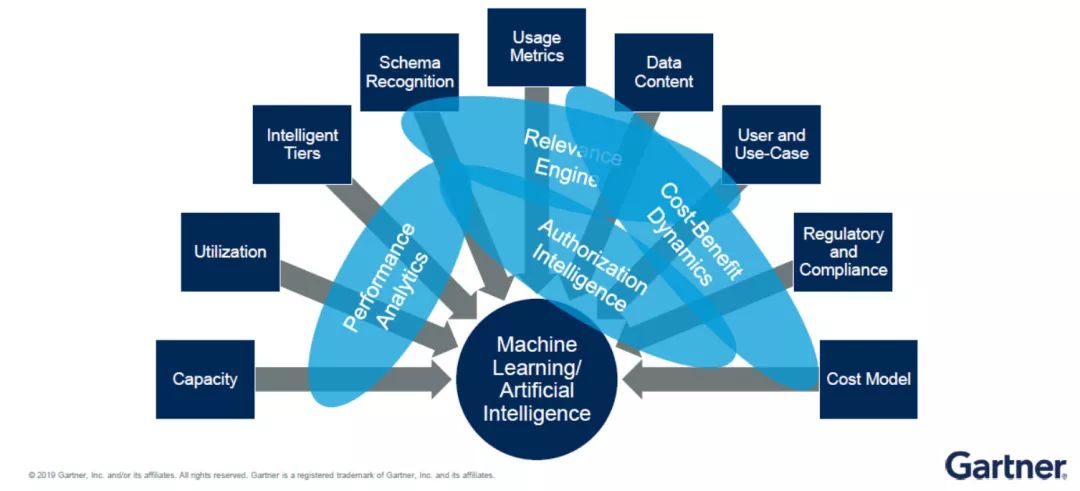
機器學習和人工智能是一個后端底層技術,諸如性能分析等更多數據管理工作的完成還需動態元數據的支持。元數據專門用于描述數據的特質,幫助企業機構將不同的數據進行關聯并做推薦。
以數據分析為例,企業機構在定義數據的相關性時,動態元數據就會起到中間凝合力的作用。
3)開源軟件收益與風險的平衡
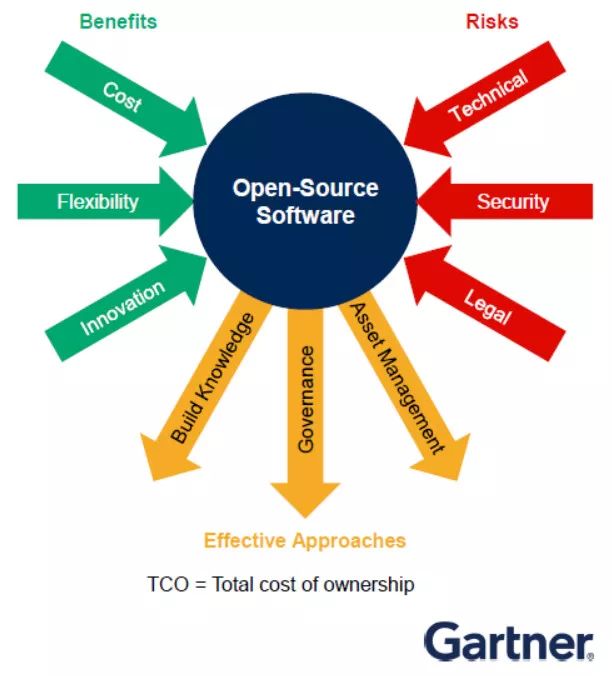
提及開源,一般想到的是總擁有成本(TCO)很低、企業機構的回本速度很快。
雖然企業機構有時無法通過開源軟件(OSS)得到所需支持,但目前市場上已有很多商業軟件包可給予幫助。
其次,若企業機構需要研發創新并保持靈活性,那么開源軟件應是首要選擇。
再者,據Gartner調查,全球90%的企業機構已把開源軟件用在任務關鍵型的IT流程中。
最后,企業機構應把服務水平協議與商業供應商的平衡性放入自身的數據管理策略考量中。
3.組織的衍化(Organization Evolves)
Gartner預測,到2022年之前,使用動態元數據去連接、優化、自動化數據集成流程的企業機構將減少30%的數據交付的時間。
此外,到2023年之前,在數據管理中使用人工智能技術能夠幫助企業機構進行更多的自動化工作,因此這些企業機構對于IT專業人士的需求將減少20%。
1)自動化數據與分析工作即將來臨
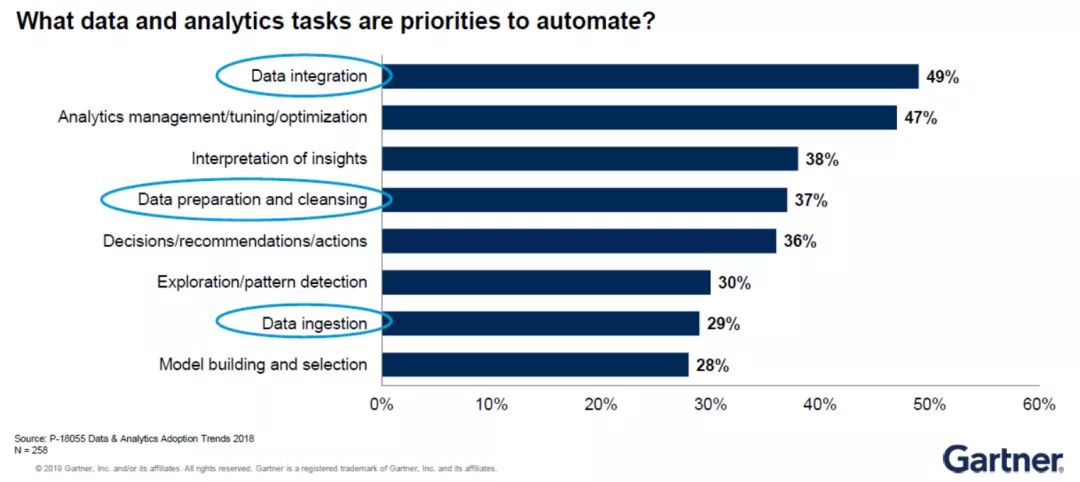
Gartner就數據分析工作的自動化優先級進行過一項調研。調研結果顯示,數據集成(Data Integration)排名第一,因為其最費時間也最易出錯。
此外,機器學習相關技術的研發需要進行大量前期的數據準備(Data Preparation)。Gartner預計數據科學家大約需要花費70%到80%的時間進行數據準備。
因此,若數據準備無法進行自動化,那么項目交付的時間就會極其漫長。
2)人機聯盟:少花錢、多做事
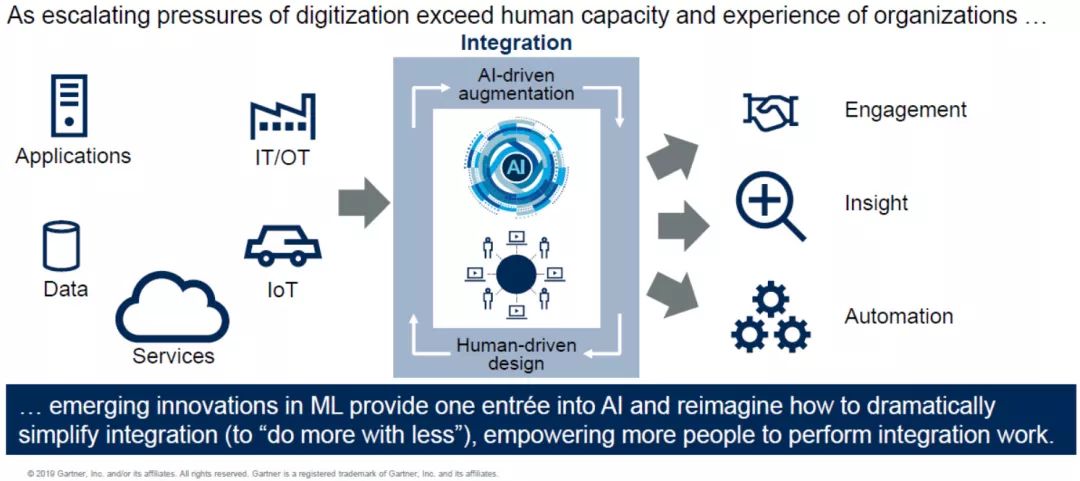
未來,數據集成工作需要人與機器共同完成。數據存在不同的端口且數量龐大,因此單獨的人力難以進行處理、需有工具進行支持。未來,這種工具將引入人工智能與機器學習技術,讓人力做不到或短期內無法實現的工作變成現實。
與此同時,此前從事這類工作的IT工程師將可騰出時間去做更多、更重要的事情。
3)元數據與數據管理架構緊密貼合
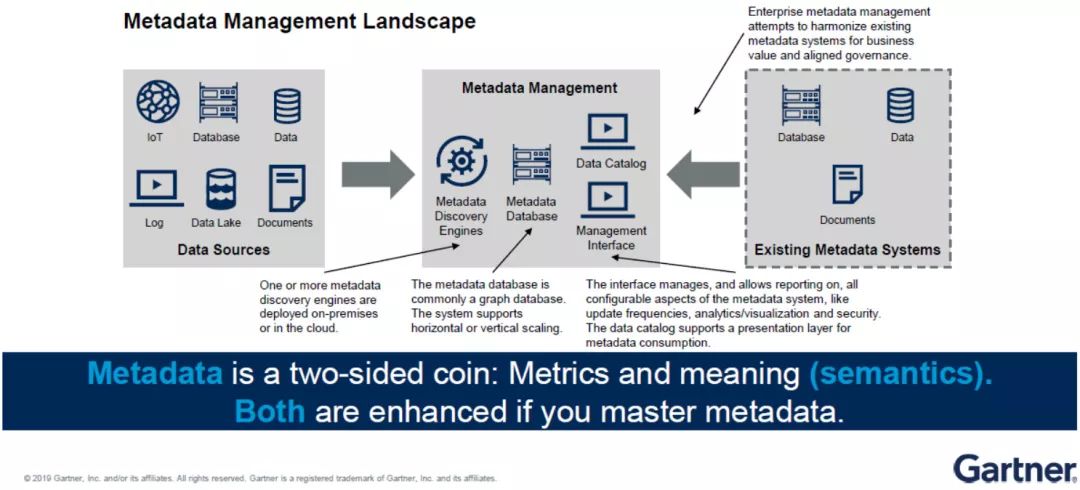
元數據的管理平臺上有很多引擎,有些可以根據數據目錄,即目前所存儲的數據信息,自動地發現企業機構目前架構中有哪些數據源還未掌控,然后進行處理。
元數據有兩種維度——度量(Metrics)與語義(Meaning)。
以往,企業機構做得更多的是語義,但在未來元數據的管理上,兩者具有同等重要性,甚至“度量”的地位更高,因為它可以根據此前類似數據的集成方式自動進行數據挖掘和規劃。
4)數據管理新角色不斷涌現
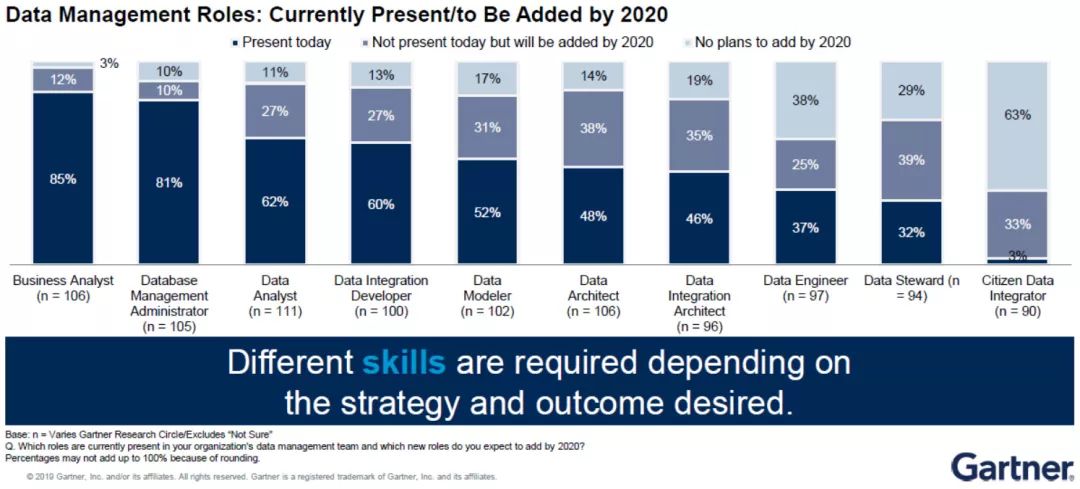
Gartner針對“企業機構目前及2020前的數據管理職位”進行過調研,結果如上圖所示。其中,需重點強調的是數據管家(Data Steward)。“數據管家”在未來的數據管理工作中占有極其重要的地位。
當前,企業機構已經意識到自己的數據源變得更多、數據使用案例變得更為復雜,在此情況下,它們需要新的崗位去應對挑戰。
但需強調的是,每個企業機構都有自己不同的戰略,它們需要根據預測的業務結果來應用不同的技能、設置不同的數據管理崗位。