Count(distinct) 玩出了新花樣

介紹使用索引、臨時(shí)表 + 文件排序?qū)崿F(xiàn) group by,以及單獨(dú)介紹臨時(shí)表的三篇文章中,多次以 count(distinct) 作為示例說(shuō)明。
那還有必要單獨(dú)為 count(distinct) 寫一篇文章嗎?
此刻,想到一句臺(tái)詞:別問(wèn),問(wèn)就是有必要。
回到正題,MySQL 使用 MEMORY 引擎臨時(shí)表實(shí)現(xiàn) count(distinct) 的去重功能時(shí),玩出了新花樣,所以,還是值得寫一下的。背景說(shuō)明到此為止,我們快快開始。
本文內(nèi)容基于 MySQL 5.7.35 源碼。
1、 概述
如果 count(distinct) 不能使用索引去重,就需要使用臨時(shí)表。臨時(shí)表的存儲(chǔ)引擎有三種選擇:MEMORY、MyISAM、InnoDB。
和使用 MyISAM 或 InnoDB 作為臨時(shí)表的存儲(chǔ)引擎處理邏輯有些不一樣,如果 MySQL 決定使用 MEMORY 作為臨時(shí)表的存儲(chǔ)引擎,臨時(shí)表會(huì)被創(chuàng)建,但只是作為輔助,表里不會(huì)寫入任何數(shù)據(jù)。
要說(shuō)清楚為什么會(huì)有這種花樣操作,需要從 MEMORY 引擎支持的兩種索引結(jié)構(gòu)說(shuō)起。
2、 MEMORY 支持的兩種索引結(jié)構(gòu)
MEMORY 引擎支持兩種索引結(jié)構(gòu):HASH 索引、B-TREE 索引。
HASH 索引,顧名思義,索引的數(shù)據(jù)結(jié)構(gòu)是哈希表。hash key 是索引字段內(nèi)容計(jì)算得到的哈希值,hash value 是索引記錄指向的數(shù)據(jù)行的地址。
HASH 索引中的記錄不是按照字段內(nèi)容順序存放的,而是亂序的,其優(yōu)點(diǎn)在于查找時(shí)間復(fù)雜度是 O(1),按單個(gè)值查找記錄速度非常快,但不能用于范圍查詢。
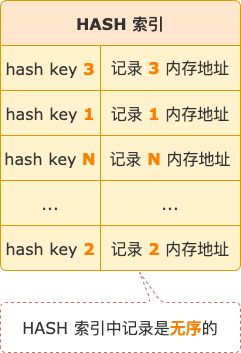
HASH 索引結(jié)構(gòu)示意圖
MyISAM、InnoDB 引擎 B-TREE 索引的數(shù)據(jù)結(jié)構(gòu)是 B+ 樹,而 MEMORY 引擎 B-TREE 索引的數(shù)據(jù)結(jié)構(gòu)是紅黑樹。
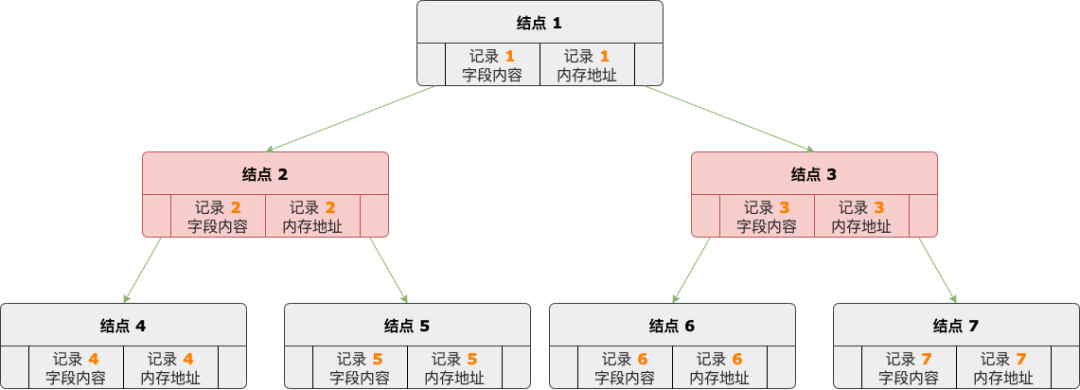
B-TREE 索引結(jié)構(gòu)示意圖
MEMORY 引擎的 B-TREE 索引結(jié)點(diǎn)中保存著索引字段內(nèi)容,以及對(duì)應(yīng)數(shù)據(jù)行的地址。
紅黑樹是平衡二叉排序樹,因此 B-TREE 索引中的結(jié)點(diǎn)是排好序的,支持范圍查詢,但是按單個(gè)值查找記錄的時(shí)間復(fù)雜度是 O(logN),相比于 HASH 索引來(lái)說(shuō)要低一些。
基于兩種數(shù)據(jù)結(jié)構(gòu)的特點(diǎn),HASH 索引適用于單值查找場(chǎng)景,B-TREE 索引適用于范圍查詢和需要排好序的記錄的場(chǎng)景。
3、去重方案怎么選?
說(shuō)完了 MEMORY 引擎的兩種索引結(jié)構(gòu),以及它們的適用場(chǎng)景,再來(lái)介紹 count(distinct) 去重方案就有基礎(chǔ)了。
按照常規(guī)流程走,當(dāng) MySQL 選擇使用 MEMORY 作為臨時(shí)表的存儲(chǔ)引擎,加上為 distinct 字段創(chuàng)建的 HASH 索引,這完全能實(shí)現(xiàn)去重操作。但是本著節(jié)約精神,MySQL 向來(lái)是能省則省,只要有優(yōu)化方案,一定是要使用的,那還可以怎么優(yōu)化呢?
要回答這個(gè)問(wèn)題,我們需要先抓住去重功能的關(guān)鍵,那就是表中記錄的唯一性。
臨時(shí)表中為 distinct 創(chuàng)建的 HASH 索引默認(rèn)就是唯一索引,既然 HASH 索引本身就保證了唯一性,是不是可以考慮只使用 HASH 索引實(shí)現(xiàn) count(distinct) 的去重功能呢?
這種思路是可行的,不過(guò) MEMORY 引擎的 HASH 索引有一個(gè)不能滿足要求的地方:HASH 索引中沒(méi)有保存索引字段內(nèi)容,只保存了字段內(nèi)容的 hash 值。
只用索引的數(shù)據(jù)結(jié)構(gòu)去重為什么需要保存字段內(nèi)容,介紹去重過(guò)程的時(shí)候會(huì)說(shuō)明,在那個(gè)場(chǎng)景下解釋起來(lái)更好理解一點(diǎn),這里先按下不表。
既然 HASH 索引不能滿足要求,別忘了 MEMORY 引擎還支持另一種索引結(jié)構(gòu):B-TREE 索引。B-TREE 索引也能實(shí)現(xiàn)去重功能,索引結(jié)點(diǎn)中還保存了字段內(nèi)容,完美符合要求。
前面以流式的方式介紹了三種候選的去重方案,我們需要來(lái)個(gè)小結(jié):
方案一,臨時(shí)表 + HASH 索引,這種實(shí)現(xiàn)方案中規(guī)中矩,能夠滿足需求,缺點(diǎn)在于:只是為了實(shí)現(xiàn)去重功能,HASH 索引自己上陣就夠了,可偏偏還要搭上更多內(nèi)存往表里寫一份數(shù)據(jù),浪費(fèi)寶貴的內(nèi)存資源。
方案二,方案一中說(shuō)到,HASH 索引自己就能夠?qū)崿F(xiàn)去重了,這點(diǎn)毋庸置疑,只使用 HASH 索引也是候選方案之一,但 HASH 索引中沒(méi)有保存索引字段內(nèi)容,只能無(wú)奈的出局了。
方案三,B-TREE 索引,既能實(shí)現(xiàn)去重功能,索引中還保存了字段內(nèi)容,完美,就是它了。
不過(guò),MySQL 沒(méi)有在 MEMORY 臨時(shí)表上再創(chuàng)建一個(gè) B-TREE 類型的唯一索引,而是用了 B-TREE 索引所使用的紅黑樹,并且因?yàn)榕R時(shí)表中不會(huì)寫入任何數(shù)據(jù),紅黑樹結(jié)點(diǎn)中只需要保存字段內(nèi)容,不需要保存指向表中數(shù)據(jù)行的地址。
再次說(shuō)明:MEMORY 臨時(shí)表還是會(huì)創(chuàng)建,但是不會(huì)寫入任何數(shù)據(jù),就是空表。紅黑樹實(shí)現(xiàn)去重功能的過(guò)程中,會(huì)用到 MEMORY 臨時(shí)表的字段信息、記錄緩沖區(qū)。
以后,用 explain 查看執(zhí)行計(jì)劃時(shí),如果發(fā)現(xiàn) count(distinct) 既沒(méi)有使用索引,也沒(méi)有使用臨時(shí)表,那你可能就會(huì)想到:這家伙大概是悄無(wú)聲息的使用了紅黑樹。
前面說(shuō)了這么多,只是為了弄清楚一個(gè)問(wèn)題:為什么選擇紅黑樹實(shí)現(xiàn)去重功能。這很重要,我們要知其然,更要知其所以然,這樣我們理解起來(lái)也會(huì)更容易些,你說(shuō)是嗎?
接下來(lái)我們就要說(shuō)說(shuō)紅黑樹實(shí)現(xiàn) count(distinct) 去重功能的點(diǎn)點(diǎn)滴滴了。
4、 紅黑樹結(jié)點(diǎn)存了些什么?
紅黑樹是平衡二叉排序樹,既然是二叉樹結(jié)構(gòu),就會(huì)有指向左子樹、右子樹的指針。
紅黑樹的結(jié)點(diǎn)分為紅色和黑色,自然要有個(gè)屬性來(lái)標(biāo)記結(jié)點(diǎn)顏色。
MySQL 實(shí)現(xiàn)的紅黑樹,還支持插入重復(fù)結(jié)點(diǎn),這是通過(guò)在結(jié)點(diǎn)中增加一個(gè)記錄結(jié)點(diǎn)內(nèi)容重復(fù)次數(shù)的屬性實(shí)現(xiàn)的。
以上信息都屬于結(jié)點(diǎn)元數(shù)據(jù),元數(shù)據(jù)占用 24 字節(jié)內(nèi)存空間。每一個(gè)結(jié)點(diǎn)中,除了保存著結(jié)點(diǎn)元數(shù)據(jù),還要保存結(jié)點(diǎn)數(shù)據(jù),就是字段內(nèi)容。

 結(jié)點(diǎn)元數(shù)據(jù)
結(jié)點(diǎn)元數(shù)據(jù)
5、 紅黑樹占用內(nèi)存太大怎么辦?
使用紅黑樹去重雖然不用往 MEMORY 臨時(shí)表寫入數(shù)據(jù),但是紅黑樹也不能無(wú)限制占用內(nèi)存。
它能夠占用的最大內(nèi)存和 MEMORY 引擎臨時(shí)表一樣,也是由 tmp_table_size、max_heap_table_size 兩個(gè)系統(tǒng)變量中較小的的那個(gè)決定的。默認(rèn)配置下,紅黑樹能夠占用的最大內(nèi)存為 16M。
既然內(nèi)存大小有限制,那就可能會(huì)出現(xiàn)紅黑樹中沒(méi)有空間容納新結(jié)點(diǎn)的情況,此時(shí),磁盤文件就要粉墨登場(chǎng)了。
如果紅黑樹占用內(nèi)存達(dá)到最大值,所有結(jié)點(diǎn)數(shù)據(jù)(不包含元數(shù)據(jù))會(huì)被寫入磁盤文件,然后刪除紅黑樹所有結(jié)點(diǎn),保留內(nèi)存以便重復(fù)使用。
這些一起寫入磁盤文件的數(shù)據(jù)會(huì)組成一個(gè)數(shù)據(jù)塊,數(shù)據(jù)塊的相關(guān)信息(在磁盤文件中的位置、記錄數(shù)量)保存在對(duì)應(yīng)的 Merge_chunk 中。
磁盤文件中可能會(huì)有多個(gè)數(shù)據(jù)塊。
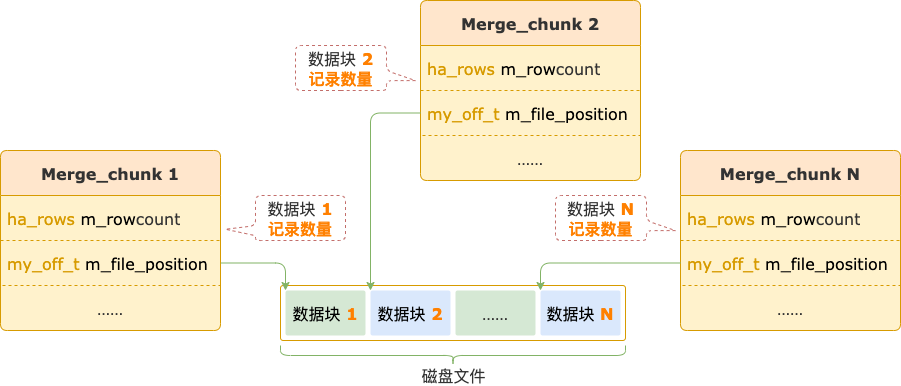
 數(shù)據(jù)塊相關(guān)信息
數(shù)據(jù)塊相關(guān)信息
數(shù)據(jù)塊中的數(shù)據(jù),因?yàn)閬?lái)源于紅黑樹,有兩個(gè)特點(diǎn):
- 記錄是按照字段內(nèi)容從小到大順序存放的。
- 記錄的字段內(nèi)容是唯一的,不存在重復(fù)。
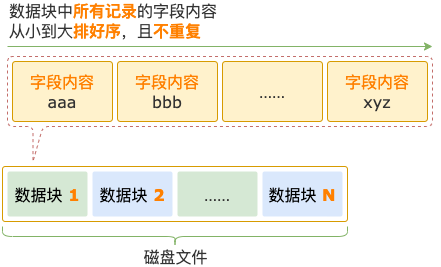
數(shù)據(jù)塊中的數(shù)據(jù)
6、合并緩沖區(qū)
通過(guò)上一小節(jié),我們知道紅黑樹占用內(nèi)存達(dá)到最大值之后,會(huì)生成一個(gè)數(shù)據(jù)塊寫入到磁盤文件。
所謂天下大勢(shì),合久必分,分久必合。
磁盤文件中的數(shù)據(jù)塊,雖然是分開寫入的,但終究要合并去重,并進(jìn)行分組計(jì)數(shù)。
磁盤文件中的每個(gè)數(shù)據(jù)塊內(nèi)部,記錄的字段內(nèi)容是不存在重復(fù)的。但是,多個(gè)數(shù)據(jù)塊之間的字段內(nèi)容可能存在重復(fù),合并過(guò)程中,需要對(duì)多個(gè)數(shù)據(jù)塊之間的字段內(nèi)容去重。
合并去重,有兩種可選的實(shí)現(xiàn)方案:
方案一,分為三步:
① 從磁盤文件的每個(gè)數(shù)據(jù)塊中讀取剩余記錄里最小的一條記錄到內(nèi)存中,最小的記錄其實(shí)就是剩余記錄里的第一條記錄。
② 找出第 ① 步讀取的那些記錄中最小的記錄。
③ 判斷當(dāng)前的最小記錄,是否和上一次最小的記錄相同,如果相同,說(shuō)明重復(fù),不處理;如果不同,進(jìn)行計(jì)數(shù)。
循環(huán)執(zhí)行第 ① ~ ③ 步,直到讀完當(dāng)前分組所有數(shù)據(jù)塊中的記錄,合并完成。
從以上描述中,想必大家已經(jīng)發(fā)現(xiàn)了這種方案存在的問(wèn)題:需要頻繁的從磁盤文件中讀取數(shù)據(jù),每次還只讀取一條記錄,頻繁磁盤 IO 必然會(huì)影響 SQL 語(yǔ)句執(zhí)行效率,為此,就有了方案二。
方案二,既然不能頻繁從磁盤中讀取數(shù)據(jù),那就換個(gè)方式,每次讀取一批記錄,減少讀取次數(shù)。
但是,一批記錄和一條記錄不一樣,需要找個(gè)大點(diǎn)的地方臨時(shí)存放,于是就有了合并緩沖區(qū)。
合并緩沖區(qū)的大小和紅黑樹占用內(nèi)存最大值一樣,也是由 tmp_table_size、max_heap_table_size 兩個(gè)系統(tǒng)變量中較小的那個(gè)控制的,默認(rèn)大小為 16M。
合并緩沖區(qū)會(huì)分成 N 份(N = 磁盤文件中數(shù)據(jù)塊的數(shù)量),每一份對(duì)應(yīng)一個(gè)數(shù)據(jù)塊,用于存放從數(shù)據(jù)塊中讀取的一批記錄。
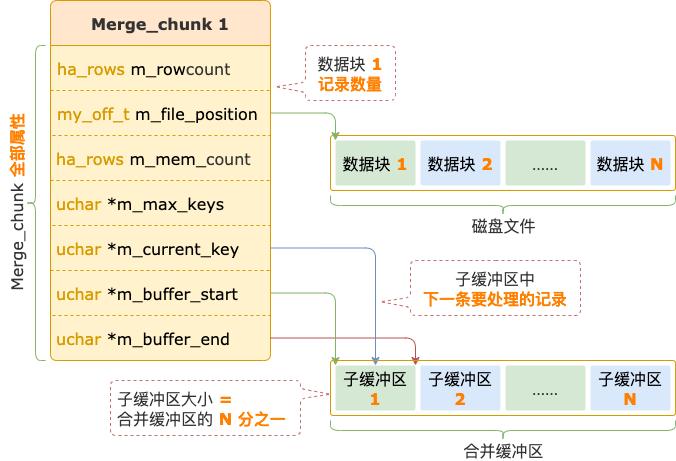
 合并緩沖區(qū)
合并緩沖區(qū)
7、 紅黑樹怎么去重和分組計(jì)數(shù)?
介紹完了前置知識(shí)點(diǎn),重頭戲來(lái)了,該說(shuō)說(shuō)紅黑樹去重和分組計(jì)數(shù)的過(guò)程了。
為了方便描述,我們還是結(jié)合一個(gè)具體 SQL 來(lái)介紹,示例表及 SQL 如下:
CREATE TABLE `t_group_by` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`e1` enum('北京','上海','廣州','深圳','天津','杭州','成都','重慶','蘇州','南京','哈爾濱','沈陽(yáng)','長(zhǎng)春','廈門','福州','南昌','泉州','德清','長(zhǎng)沙','武漢') DEFAULT '北京',
`i1` int(10) unsigned DEFAULT '0',
`c1` char(11) DEFAULT '',
`d1` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_e1` (`e1`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
select
e1, count(distinct i1)
from t_group_by
group by e1
在調(diào)試過(guò)程中,我給 t_group_by 表的 e1 字段建了索引,所以 SQL 執(zhí)行時(shí)就不需要先對(duì)表中記錄進(jìn)行排序了。
先來(lái)看一下去重及分組計(jì)數(shù)過(guò)程的示意圖。
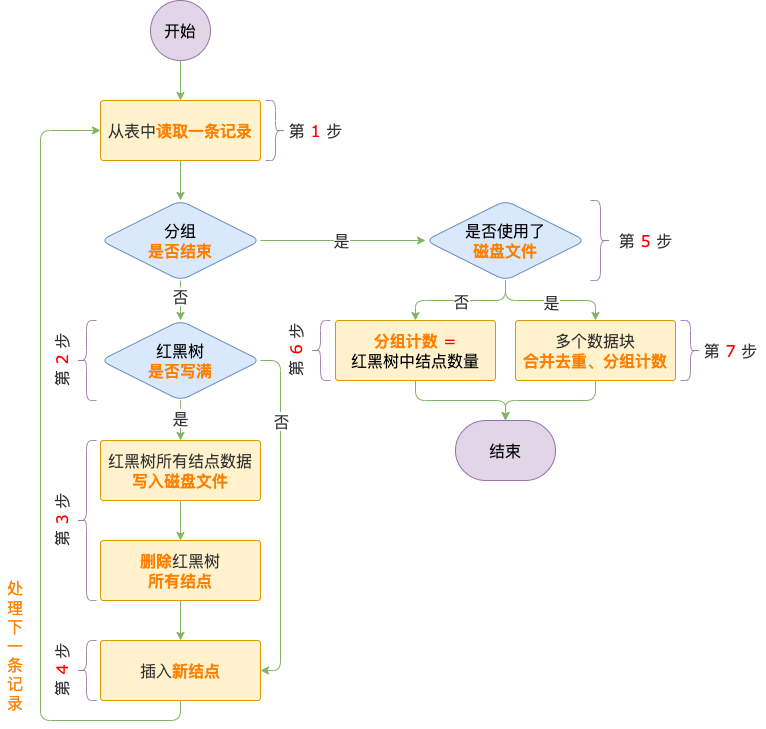
 去重及分組計(jì)數(shù)主流程
去重及分組計(jì)數(shù)主流程
看完上面的示意圖,想必大家對(duì)整個(gè)過(guò)程有個(gè)大致的印象了,我們?cè)龠M(jìn)一步看看過(guò)程中的每一步都會(huì)做哪些事情。
第 1 步,讀取記錄。
從 from 子句的表中讀取一條記錄,示例 SQL 中為 t_group_by 表。
第 2 步,判斷紅黑樹是否寫滿。
前面介紹過(guò),紅黑樹的一個(gè)結(jié)點(diǎn)中包含兩類信息:
- 結(jié)點(diǎn)元數(shù)據(jù),占用 24 字節(jié)。
- 結(jié)點(diǎn)數(shù)據(jù),示例 SQL 中結(jié)點(diǎn)數(shù)據(jù)就是 i1 字段內(nèi)容,長(zhǎng)度為 4 字節(jié)。
示例 SQL 中,一個(gè)紅黑樹結(jié)點(diǎn)占用 24 + 4 = 28 字節(jié)。
知道紅黑樹最大能占用的內(nèi)存,每個(gè)結(jié)點(diǎn)占用的內(nèi)存,就能夠算出紅黑樹最多可以插入多少個(gè)結(jié)點(diǎn)了,也就能夠很方便的判斷出紅黑樹是不是滿了。
如果紅黑樹已滿,進(jìn)入第 3 步,把紅黑樹中所有結(jié)點(diǎn)數(shù)據(jù)寫入磁盤文件。
如果紅黑樹沒(méi)滿,進(jìn)入第 4 步,插入新結(jié)點(diǎn)。
第 3 步,把紅黑樹所有結(jié)點(diǎn)數(shù)據(jù)寫入磁盤文件。
按照中序遍歷,把紅黑樹中所有結(jié)點(diǎn)數(shù)據(jù)按順序?qū)懭氪疟P文件。結(jié)點(diǎn)元數(shù)據(jù)此時(shí)就不需要了,不會(huì)寫入磁盤文件。
前面介紹過(guò)這些數(shù)據(jù)會(huì)組成一個(gè)數(shù)組塊,每個(gè)數(shù)據(jù)塊的相關(guān)信息保存在對(duì)應(yīng)的 Merge_chunk 類實(shí)例中。
數(shù)據(jù)寫入磁盤后,紅黑樹會(huì)刪除所有結(jié)點(diǎn),但是內(nèi)存空間會(huì)保留復(fù)用。此時(shí),紅黑樹就是空的了,進(jìn)入第 4 步,把剛剛因?yàn)榧t黑樹已滿沒(méi)有插入的節(jié)點(diǎn)插入到空的紅黑樹中。
第 4 步,插入新結(jié)點(diǎn)。
從 t_group_by 表讀取一條記錄之后,i1 字段值作為新結(jié)點(diǎn)的數(shù)據(jù)插入到紅黑樹中,然后回到第 1 步繼續(xù)執(zhí)行。
第 1 ~ 4 步是循環(huán)執(zhí)行的,直到一個(gè)分組的所有數(shù)據(jù)都插了入紅黑樹,循環(huán)過(guò)程結(jié)束,進(jìn)入第 5 步。
第 5 步,處理 count(distinct) 聚合邏輯。
處理聚合邏輯分兩種情況:
- 沒(méi)有使用磁盤文件,分組記錄少,紅黑樹一次都沒(méi)有寫滿過(guò),所有數(shù)據(jù)都在內(nèi)存中。
- 使用了磁盤文件,分組記錄多,紅黑樹寫滿過(guò),前面 N - 1 次寫滿之后,數(shù)據(jù)寫入磁盤文件,最后一次數(shù)據(jù)留在內(nèi)存中。
如果沒(méi)有使用磁盤文件,進(jìn)入第 6 步。
如果使用了磁盤文件,進(jìn)入第 7 步。
第 6 步,分組計(jì)數(shù)。
紅黑樹所有結(jié)點(diǎn)都在內(nèi)存中,紅黑樹中的結(jié)點(diǎn)數(shù)量就是 count(distinct) 函數(shù)的結(jié)果。這個(gè)步驟處理完,流程結(jié)束。
第 7 步,多個(gè)數(shù)據(jù)塊合并去重,然后分組計(jì)數(shù)。
紅黑樹寫滿過(guò),部分?jǐn)?shù)據(jù)在磁盤文件中,部分?jǐn)?shù)據(jù)在內(nèi)存中。需要先把內(nèi)存中紅黑樹所有結(jié)點(diǎn)數(shù)據(jù)寫入到磁盤文件中,組成最后一個(gè)數(shù)據(jù)塊。
所有數(shù)據(jù)都寫入磁盤文件之后,就可以開始進(jìn)行合并去重和分組計(jì)數(shù)了。
首先,分配一塊內(nèi)存作為合并緩沖區(qū)。
然后,把緩沖區(qū)平均分成 N 份,為了描述方便,我們把緩沖區(qū)的 N 分之一叫作子緩沖區(qū)。假設(shè)示例 SQL 在磁盤文件中有 4 個(gè)數(shù)據(jù)塊,就會(huì)對(duì)應(yīng) 4 個(gè)子緩沖區(qū)。
每一個(gè)數(shù)據(jù)塊對(duì)應(yīng)的 Merge_chunk 中保存著子緩沖區(qū)的開始和結(jié)束位置、能夠存放的記錄數(shù)量、指向子緩沖區(qū)中下一條要處理的記錄的位置。

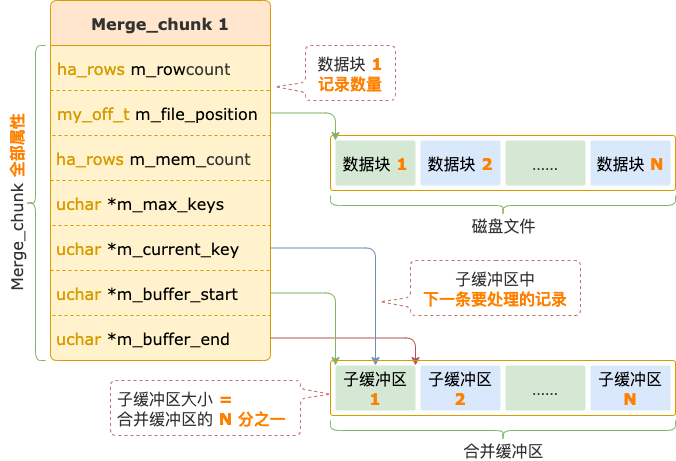
合并緩沖區(qū)
每個(gè)數(shù)據(jù)塊內(nèi)部的記錄都是按照字段內(nèi)容從小到大排好序的,多個(gè)數(shù)據(jù)塊合并去重的過(guò)程不算復(fù)雜,步驟如下:

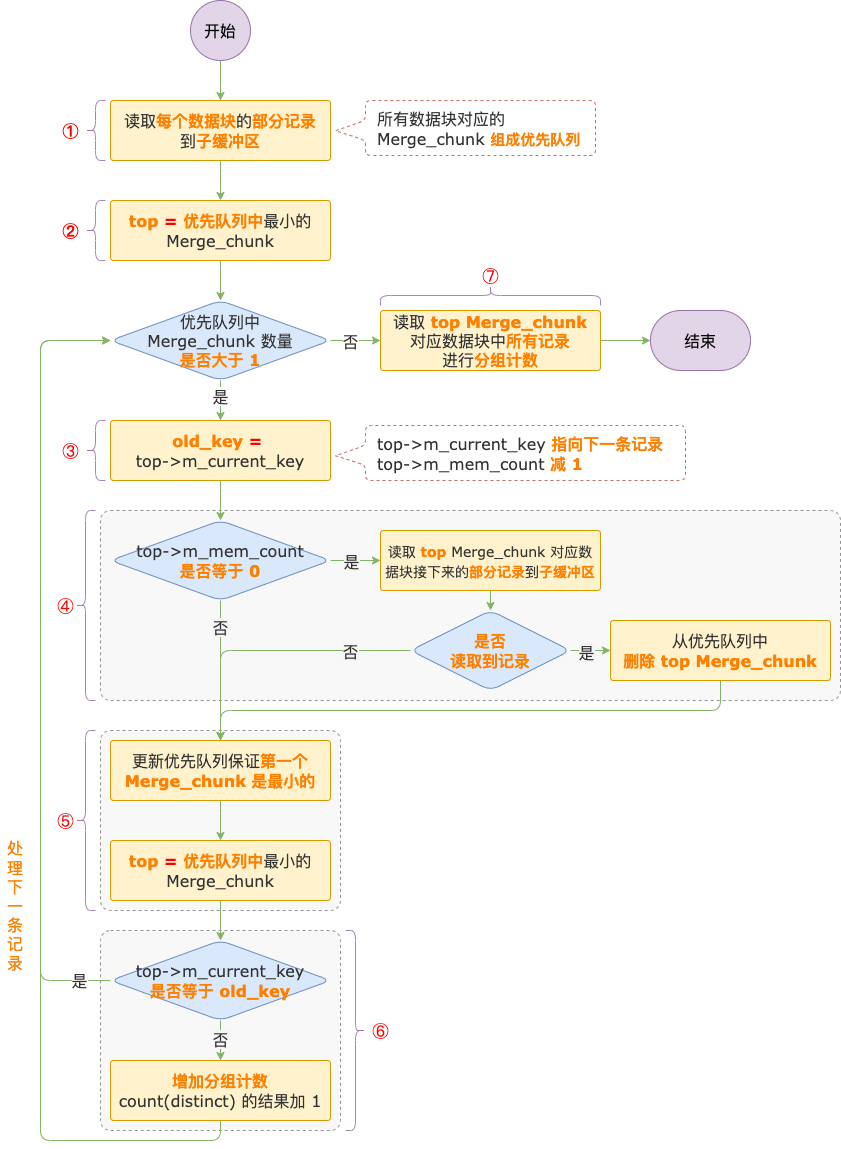
合并去重及分組計(jì)數(shù)流程
① 讀取磁盤文件中的數(shù)據(jù)塊到子緩沖區(qū)。
從每個(gè)數(shù)據(jù)塊讀取一部分記錄到子緩沖區(qū),所有數(shù)據(jù)塊對(duì)應(yīng)的 Merge_chunk 組成一個(gè)優(yōu)先隊(duì)列。
此時(shí),每個(gè) Merge_chunk 的 m_current_key 都指向數(shù)據(jù)塊的第一條記錄,也是該數(shù)據(jù)塊中最小的記錄,這條記錄的內(nèi)容就代表 Merge_chunk 的值。
Merge_chunk 的 m_mem_count 表示已讀取到子緩沖區(qū)中尚未處理的記錄數(shù)量。
② 獲取優(yōu)先隊(duì)列中最小的 Merge_chunk,用top表示。
優(yōu)先隊(duì)列中第一個(gè) Merge_chunk 就是所有 Merge_chunk 中最小的。
③ 讀取 top Merge_chunk 的 m_current_key 指向的記錄的內(nèi)容到 old_key。
m_current_key 指向的記錄就是 top Merge_chunk 中的最小記錄,記為 old_key。
然后,m_current_key 指向數(shù)據(jù)塊中下一條記錄,m_mem_count 減 1,表示已讀取到子緩沖區(qū)中的尚未處理的記錄減少 1 條。
④ 如果 m_mem_count 等于 0,說(shuō)明該數(shù)據(jù)塊對(duì)應(yīng)子緩沖區(qū)中的記錄已處理完,需要再?gòu)拇疟P文件中讀取該數(shù)據(jù)塊的一部分記錄到子緩沖區(qū)。
如果數(shù)據(jù)塊中的數(shù)據(jù)都已處理完,把數(shù)據(jù)塊對(duì)應(yīng)的 Merge_chunk 從優(yōu)先隊(duì)列中刪除,對(duì)應(yīng)子緩沖區(qū)的內(nèi)存空間全部并入相鄰的子緩沖區(qū)。
⑤ 更新優(yōu)先隊(duì)列中的 top Merge_chunk。
③、④ 兩步執(zhí)行之后,最小的 Merge_chunk 可能發(fā)生了變化,所以需要更新優(yōu)先隊(duì)列,保證優(yōu)先隊(duì)列中的第一個(gè) Merge_chunk 是最小的。
⑥ 真正的去重操作。
比較新的 top Merge_chunk 中最小記錄的內(nèi)容和 old_key的值,如果一樣,說(shuō)明字段內(nèi)容重復(fù),不需要進(jìn)行分組計(jì)數(shù),回到 ③ ,繼續(xù)進(jìn)行下一輪循環(huán)。
如果不一樣,說(shuō)明字段內(nèi)容不重復(fù),對(duì) top Merge_chunk 中的最小記錄進(jìn)行分組計(jì)數(shù),然后回到 ③ ,繼續(xù)進(jìn)行下一輪循環(huán)。
③ ~ ⑥ 是循環(huán)執(zhí)行的,直到優(yōu)先隊(duì)列中 Merge_chunk 的數(shù)量小于等于 1 個(gè),循環(huán)結(jié)束。
⑦ 處理最后一個(gè)數(shù)據(jù)塊中剩余的數(shù)據(jù)。
經(jīng)過(guò) ③ ~ ⑥ 循環(huán)執(zhí)行過(guò)程,優(yōu)先隊(duì)列中還會(huì)剩下 1 個(gè) Merge_chunk,需要對(duì) Merge_chunk 對(duì)應(yīng)數(shù)據(jù)塊中剩下的記錄進(jìn)行分組計(jì)數(shù),因?yàn)槭且粋€(gè)數(shù)據(jù)塊內(nèi)部的記錄,就不需要去重了。
前面那個(gè)按下不表的問(wèn)題也該有下文了:
因?yàn)閷?duì)磁盤文件多個(gè)數(shù)據(jù)塊中的記錄合并去重時(shí),需要使用字段內(nèi)容做比較,而 MEMORY 引擎的 HASH 索引中沒(méi)有保存字段內(nèi)容,只保存了表中數(shù)據(jù)行的首地址,這就是 MySQL 選擇使用紅黑樹去重,而沒(méi)有選擇 HASH 的原因。
8、 sum(distinct)、avg(distinct) 不一樣
sum(distinct)、avg(distinct) 也需要去重,但是和 count(distinct) 不一樣的地方在于:sum(distinct)、avg(distinct) 只會(huì)對(duì)整數(shù)、浮點(diǎn)數(shù)求和或求平均數(shù),并且只能有一個(gè)參數(shù),需要的內(nèi)存空間比較小,這意味著 sum(distinct)、avg(distinct) 去重時(shí)不需要用磁盤臨時(shí)表。
因此,對(duì)于 sum(distinct)、avg(distinct) 來(lái)說(shuō),只會(huì)選擇使用紅黑樹去重,并且也不會(huì)創(chuàng)建一個(gè)空的 MEMORY 臨時(shí)表,這兩點(diǎn)和 count(distinct) 不一樣。
如果 sum()、avg() 函數(shù)參數(shù)中的字段不是整數(shù)或浮點(diǎn)數(shù)類型的字段,不會(huì)報(bào)錯(cuò),字段值都會(huì)被轉(zhuǎn)換為浮點(diǎn)數(shù),然后對(duì)浮點(diǎn)數(shù)求和或求平均數(shù)。
非整數(shù)、浮點(diǎn)數(shù)類型字段轉(zhuǎn)換為浮點(diǎn)數(shù),和開發(fā)語(yǔ)言中的轉(zhuǎn)換邏輯基本相同,對(duì)于字符串內(nèi)容,就是把字符串前面的數(shù)字作為字段的數(shù)字值,例如:91 測(cè)試轉(zhuǎn)換為浮點(diǎn)數(shù)是 91.0,測(cè)試轉(zhuǎn)換為浮點(diǎn)數(shù)是 0.0。
9、 總結(jié)
第 2 小節(jié),介紹了 MEMORY 引擎支持的兩種索引結(jié)構(gòu):HASH 索引、B-TREE 索引。
HASH 索引適用于單值查找多的場(chǎng)景;B-TREE 索引適用于范圍查詢、需要排好序的記錄的場(chǎng)景。
第 3 小節(jié),以循序漸進(jìn)的方式介紹了 MySQL 為什么選擇使用紅黑樹實(shí)現(xiàn) count(distinct) 的去重功能。
第 4 小節(jié),介紹了紅黑樹單個(gè)結(jié)點(diǎn)的結(jié)構(gòu),每個(gè)結(jié)點(diǎn)包含結(jié)點(diǎn)元數(shù)據(jù)、結(jié)點(diǎn)數(shù)據(jù)兩類信息。
第 5 小節(jié),介紹了紅黑樹占用內(nèi)存超過(guò)最大值之后,會(huì)把所有結(jié)點(diǎn)數(shù)據(jù)寫入磁盤文件,然后刪除所有結(jié)點(diǎn),保留內(nèi)存重復(fù)使用。
第 6 小節(jié),以循序漸進(jìn)的方式介紹了為什么需要合并緩沖區(qū),以及緩沖區(qū)的大小由 tmp_table_size、max_heap_table_size 兩個(gè)系統(tǒng)變量控制。
第 7 小節(jié),介紹了磁盤文件中所有數(shù)據(jù)塊合并去重、分組計(jì)數(shù)的詳細(xì)過(guò)程。合并去重及分組計(jì)數(shù)分為紅黑樹寫滿過(guò)、沒(méi)寫滿過(guò)兩種情況,處理邏輯不一樣。
第 8 小節(jié),介紹了 sum(distinct)、avg(distinct) 只能用于整數(shù)、浮點(diǎn)數(shù)求和、求平均數(shù),它們和 count(distinct) 不一樣的地方在于:只會(huì)選擇使用紅黑樹去重,不需要?jiǎng)?chuàng)建 MEMORY 臨時(shí)表,更不需要磁盤臨時(shí)表。
本文轉(zhuǎn)載自微信公眾號(hào)「一樹一溪」,可以通過(guò)以下二維碼關(guān)注。轉(zhuǎn)載本文請(qǐng)聯(lián)系一樹一溪公眾號(hào)。