













平安云原生數據庫開發與實踐
本期分享嘉賓:平安科技資深研發工程師 宋歌
簡介:平安科技研發工程師,熟悉Kubernetes contributor、TiDB contributor,熱愛開源,同時也是《TiDB in action》作者之一。
摘要:TiDB作為開源分布式關系型數據庫,具備良好的擴展性,結合云環境靈活的基礎設施,可以充分發揮分布式數據庫的優勢。至于,為什么TiDB一定要上云?云原生數據庫改造之前最大的挑戰是什么?平安科技給出的答案是效率、成本和故障自愈需求!那么,在上云過程中,TiDB使用了哪些關鍵組件?如何在K8S上有效管理TiDB集群?如何充分利用云環境穩定運行TiDB?TiDB上云后如何提供更好的用戶體驗?本文結合平安科技實際業務環境,具體介紹了開發與應用實踐過程!
云原生時代,以Kubernetes為代表的編排系統成為新應用的事實標準,甚至被稱為是提升開發效率的“殺手锏”級應用,其無狀態的彈性伸縮以及自動故障轉移能力,無疑實現了生產力的又一次解放。
事實上,狀態本身從未消失,而是下沉到底層的數據庫、對象存儲等有狀態的應用上。那么,以TiDB為代表的有狀態應用,如何在“負重前行”過程中,充分利用云以及Kubernetes的潛力,獲得進一步的成功呢?平安科技總結出的關于TiDB與Kubernetes的“愛恨情仇”,或許能為更多企業的云原生實踐帶來參考和借鑒意義!
分布式數據庫TiDB技術回顧
2018年,平安科技開始使用TiDB;2019年首次完成了線上業務部署。2019年以后,平安科技開始著手實現TiDB的上云。2021年,平安科技推出了UbiSQL云原生分布式數據庫。
之所以要引入TiDB,主要是為了支持平安集團重大業務活動——平安1.8財神節。在短短10天活動高峰期,TiDB平穩地度過了活動大促。活動中,TiDB表現出卓越的延展性,可以支持快速擴縮容,實現業務峰值的覆蓋。
眾所周知,TiDB是一款開源分布式NewSQL數據庫服務,源于谷歌發布的Spanner,支持OLTP和OLAP;同時,TiDB在橫向擴展能力上,具有非常強的水平擴展能力,這是天然架構上的優勢;TiDB支持分布式事務,高度兼容MySQL5.7協議,是HTAP交易分析混合型應用,適用于海量數據存儲、高并發、高吞吐、高增速的業務場景,能使遷移成本降到極低。
為什么TiDB需要上云?
TiDB為什么要上云?運維成本是最大挑戰!
當時,集群管理非常多,運維效率難以滿足用戶的交付時效。而從故障自愈的角度看,傳統環境難以實現自動化。比如:當一個服務器掛掉以后,其實服務能力是受損的狀態,需要DBA晚上爬起來去看這個問題怎么解決。如果業務晚上有高峰,還要新建一個實例去擴容,這些都需要去手動操作。
上云自動化以后,對用戶來說最直接的感受就是成本和效率。在傳統環境去部署TiDB的時候,比較碎片化,管理成本較高,通過配置腳本做自動化部署,缺少對整個集群狀態的維護和自動管理能力,也很難做資源調度,并且資源調度依賴于外部的算法或者框架來做。另外,傳統環境很難實現故障自愈、彈性服務;但是上云以后,數據庫實例超過一定時間沒有響應后,Operator會幫你把新的節點自動拉起來,提供數據庫服務故障自愈能力。而從用戶應用交付來看,我們原來從準備資源到到交付一套生產集群可能需要數天時間,因為需要申請服務器,還需要規劃一些端口;而上云以后的交付時效是分鐘級別,這是非常明顯的用戶體驗上的提升。
基于上述幾點因素,TiDB上云成為最佳選擇!
在云化過程中,我們用了TiDB Operator這個組件,同時做了一些二次開發,在K8S集群上去交付一套TiDB容器化的集群,可以很好地將資源利用率提高到一個比較高的水平。在傳統環境下,需要人工去管理資源,比如:通過粗糙的資源算法去管理,資源利用率比較低;而云化以后,可統一管理資源池,通過K8s編排和調度充分利用主機資源,使主機資源使用率得到大幅提升。同時,云上是使用容器化的方式去部署的,節點失效了以后可以由Controller自動拉起,很好地做到節點的容災,確保節點在一臺主機掛掉以后,在其他節點或者計算層可以維持副本數量。
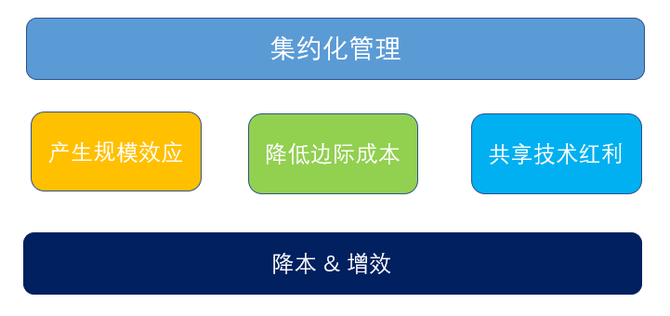
尤為重要的是,TiDB上云把所有的TiDB集群做了集約化管理以后,可以很明顯看到規模效應。分布式數據庫集群組件很多,節點也很多,管理大量集群的時候,會導致信息管理成本、集群的管理成本、運維成本陡然上升,而把所有的集群進行集中化管理后會產生規模效應。TiDB上云以后,可以有效降低每套集群的邊際管理成本。
換言之,管理的集群越多,每個節點所需要消耗的技術、人力成本就越少。同時,集約化管理還帶來另一個好處,集團各公司用戶可以共享技術紅利。我們在做代碼的提升時,發布了新的功能,比如:快速備份、基于時間點恢復、參數調優等,都可以在云上集約化管理方式下,把技術能力提供給被托管集群,最終效果就是降本增效。
如何在云上管理TiDB集群?
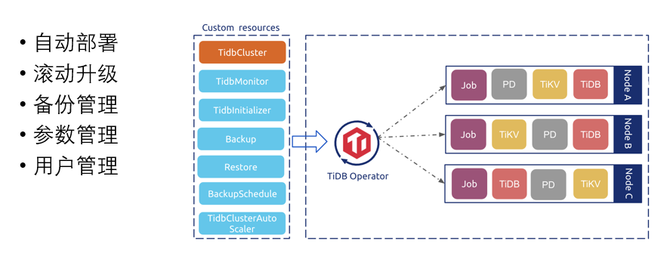
那么,我們如何在K8S集群上管理TiDB集群呢?大概構建了以下5個核心能力!
自動化部署。首先,使用TiDB Operator做了一些二次開發,實現了一些云上自動化的管理能力。比如:自動化交付,讓用戶在平安云界面上一鍵點擊,創建集群,選擇規格、實例,然后選擇存儲的空間大小,自動在后端創建TiDB集群,交付這個集群。
2.滾動升級。TiDB社區版的升級頻率非常高,前幾年,大概一個半月,就升級一個小版本。所以,在線上,我們也會有一些碎片化的小版本,在做滾動升級的時候, DBA可以在運維時間段,將集群做一個小版本的一個升級,目前可以做到一鍵滾動升級。
3.備份管理。基本做到了全量備份、增量備份、全量恢復、按時間點恢復(PITR)。
4. 參數管理。DBA可以在平安云頁面上做參數配置,同時這個參數配置可以記錄你的參數修改歷史,給你一些默認參數;并且,根據不同的套餐給你一些默認的參數。你去修改調整以后,會記錄誰什么時候修改的什么東西。并且,還有可以修改參數的時間段,設置控制參數生效規則,比如:不要在業務高峰期調整這個參數,然后由用戶在頁面上配置。
5. 用戶管理。目前,主要針對集團內部子公司,對于數據庫的用戶管理有一些管理規范,結合內部系統的一些建設規范和審批流程,通過審批以后按照規范去創建用戶的功能。
如何充分利用云環境穩定運行TiDB?
第一,容器網絡。使用了K8S比較常見的Calico作為網絡插件,相比Flannel的好處在于,可以在網絡層面通過BGP的方式實現容器網絡互連,避免overlay 模型隧道開銷。另外,我們還在驗證基于自研的K8S網絡插件實現靜態IP的網絡方案。
第二,Load Balancer。數據庫實例增加后,業務訪問的時候就需要一個負載均衡,目前我們使用了K8S的Service 作為它的一個負載均衡;同時,在做灰度升級、滾動升級的時候,利用了負載均衡的標簽選擇能力,來做流量的控制。
第三,Service Discovery。基于DNS實現服務自動發現。所謂“服務發現”,在搭建PD的時候,要去配置一些靜態節點。PD有幾種集群搭建方式,一種是配置一個靜態的集群,各節點相互知道其他節點IP。也可以基于服務發現機制,節點自動組建集群。采用服務發現的好處是,集群的規模比較靈活,比較容易做一個動態的集群,而非采用靜態的方式。
第四,Backup&Restore。基于社區工具和對象存儲實現備份恢復數據。之前備份恢復功能,基于MySQL、Lightning做TiDB層的數據備份和恢復,Lightning還涉及寫KV。而Backup&Restore工具直接從KV層備份數據。由于是在每個TiKV節點上直接備份,所以還可以支持更高的并發和吞吐。并且避免計算層的SQL解析,恢復速度也比較快。目前來看,這個工具很快,我們集成了Backup&Restore工具。同時,可以基于云備份到對象存儲,再從對象存儲做數據恢復。
另外用戶更多關心采用容器化以后,如何確保穩定性,如何在一個復雜的系統里使用一個新的技術,讓整個系統變得更好而非更糟糕。
這里有幾項相對來說比較智能化的技術:
Automatic Failover。相當于你的TiKV本身具備故障自愈能力,假設指定了三個副本,當Operator檢測到有個副本掛掉了,超過30分鐘沒有恢復,他就會做一個故障的自愈,這是傳統的Ansible沒有的特性,是TiDB Operator獨有的一個特性,這也是基于云帶來的一個好處。假設有三個副本,有一個副本做了健康檢查失敗了,時間已經超過30分鐘,就會自動恢復一個新的副本。不用管原來的副本了,這個時候依然保持彈性的服務能力。當然,等待故障節點恢復了以后,會有一個超出期望的4個副本,這個時候DBA再去根據故障情況去判斷,要不要把新增的副本下線掉。當然,這個30分鐘的限制,也是Operator自身的一個參數,可以配置多長時間以后Operator才能新建節點。
Auto-scaling,結合Prometheus、TiDB的Pod及K8S的HPA能力,基于Metrics的一些關鍵指標,實現實例節點的擴容。當我們發現節點、業務特別繁忙的時候,會基于資源池進行擴容。用戶可以指定擴容規則,比如最大的擴容上線,擴容的等待時間,可以有在用戶端的頁面按需設置。同時,有擴容就會有縮容策略,比如:有一個冷卻的時間,超過這個時間以后,關鍵指標沒有達到縮容的最低值,管控組件就自動縮容,告訴這個進程結束了,數據庫會終止接受新的會話,并把當前會話進行處理完成,不會出現事務長時間的等待,超過等待時間被清除的情況。
Self-Driving,數據庫集群整體有波動、有異常,如何把異常平滑地處理掉?通過監控、日志等自動地分析和識別參數,可以通過Self-Driving來實現。
TiDB上云后如何獲得更好的用戶體驗?
一般情況下,DBA比較習慣在Linux里面去維護數據庫,比如查看日志,但在分布式系統里很麻煩,因為需要登錄到各個節點去看不同的路徑,所以上云之后我們就接入了一些云本身的能力,包括集中日志管理,我們內部叫日志云,把K8S Pod上的日志等集中收集上來,然后在另外的產品頁面里去做一些關鍵字的過濾、分析等。
另外,就是統一的監控頁面,方便DBA做更好的分析,幫助用戶做數據庫性能的分析。該能力可以基于云平臺的產品頁面去添加,包括可以擴縮容,調整購買規格,調整付費方式,比如預付費還是按量付費等。
最后,云原生數據庫也是一個持續演進的過程,為了讓應用性能達到最佳,我們在底層技術支撐方面也在做一些新的探索,進行持續發力。
1、 縱向擴縮容(VPA)。我們在2021年推出的UbiSQL分布式數據庫,在這方面在做進一步的探索,比如:如何基于實例進行縱向擴縮容(VPA)。原來的CPU有限定,但業務突然遇到高峰期,如果是水平擴容,首先能力和時間有限;另外,水平擴容有些大的SQL在單個實例上還是有瓶頸。于是套餐的規格需要擴大,在應用不用重啟的情況下,原地增加可用資源限制,然后再去做縱向的套餐規格的擴容。
2、 異構集群( Heterogeneous Cluster )。存儲節點在擴縮容的時候,包括底層存儲,每個TiKV對應的存儲塊不一樣,我們在構建集群的時候,允許加入不同的內存、CPU還有存儲磁盤的比例,整個TiKV允許他有不同磁盤每一個塊的比例。同時,異構集群還有一個特性,就是可以隔離AP和TP的請求。比如:有個做數據中臺的業務找過來,有些業務是交易型,希望打在某個節點上;另外,有些業務是分析型的,希望打在另外的計算節點上,并且這些節點資源規格是不一樣的,如何把這塊功能以產品化的形式提供給用戶,也是我們目前在做的事情。
3、 數據庫自治能力( Database Autonomy )。我們也在做一些數據庫自治探索。首先,構建數據庫治理體系,因為治理體系是數據庫自治的關鍵路徑,先有一個治理的過程,有數據、有治理能力。接下來,再根據數據和治理能力再去做自動化,包括基于數據的分析、參數的調優。
TiDB可以優化的參數非常多,加上分布式架構組件,兩者結合起來調優過程就非常復雜。而數據庫自治可以解決很多問題。首先是,參數調優,根據不同的環境和業務負載,可以把數據庫的一些參數調整到相對較好的狀態。因為交付的集群都是默認的參數,這些參數要么是基于專家模型,專家覺得這個套餐能面向80%的業務,都在用這個參數,那就用這樣的。但是,集群交付了以后,部分參數可以根據實際業務負載特性進行適當調整。我們通過數據庫自治可以把參數調優變成一個自動化的過程。
然后是,積累下來的慢日志數據如何去優化?過去,很多日志數據都是基于人工的經驗去做分析,我們希望把慢日志的分析能力自動化。現在,這些能力都依賴于所使用的基礎設施,先把所有慢日志采集下來,然后再根據專家模型轉化成自動化過程。
4、使用新型硬件優化KV存儲(KVSSD)。將Rocksdb集成到SSD硬件中,從而直接使用硬件KV接口能力,上層應用原來需要通過Rocksdb訪問SSD硬件。而現在硬件廠商直接就把KV能力集成到硬件中,類似于存算一體的硬件,可以顯著提升SSD的KV讀寫性能。
總之,TiDB能超越傳統數據庫,讓數據發揮更大價值,與容器相關的關鍵組件發揮了重要作用,而從云原生數據庫設計的未來發展來看,還有更多可能性以及更大的探索空間!
























