













聊聊Insert ... On Duplicate Key Update 和ReplaceInto有什么區別

前段時間和滴滴的一位同學聊到 insert ... on duplicate key update 插入一條記錄成功后,影響行數為 2 意味著什么?
以前沒有深挖過這里面的細節,最近幾天抽空翻了翻源碼,可以來扒一扒這背后的細節了。對了,insert ... on duplicate key update 還有個兄弟叫 replace into,一起帶飛吧。
為了方便描述,本文后面會用 insert duplicate 表示 insert ... on duplicate key update。
本文內容基于 MySQL 5.7.35 源碼。
1、 準備工作
示例表結構及插入初始化數據 SQL 如下:
CREATE TABLE `t_insert` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`i1` int(11) NOT NULL DEFAULT '0',
`i2` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_i1` (`i1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into t_insert(i1, i2) values
(101, 201),
(102, 202),
(103, 203),
(104, 204),
(105, 205)
2、先說結論
insert ... on duplicate key update 和 replace into 執行成功之后返回的影響行數,是個比較小的主題,我們先說結論,然后再分析這兩種 SQL 執行過程中計算影響行數的邏輯。
對執行過程細節不感興趣的朋友,直接看本小節就好,可以不需要看第 3 小節的執行過程分析了。
在源碼實現中,批量插入和單條插入記錄沒什么區別,批量插入實際上是循環執行單條插入。所以,結論和執行過程分析兩小節,都基于插入單條記錄進行分析。
(1) insert ... on duplicate key update
insert duplicate 語句,插入一條記錄,影響行數可能有 3 種取值:0、1、2,影響行數 = 插入行數 + 更新行數。
影響行數 = 1,表示插入記錄和表中記錄不存在主鍵或唯一索引沖突,插入操作可以直接成功。影響行數 = 插入行數(1) + 更新行數(0) = 1。
影響行數 = 0,表示插入記錄和表中記錄存在主鍵或唯一索引沖突,并且 insert duplicate 語句 update 字段列表中每個字段的字段值和沖突記錄中對應的字段值一樣。
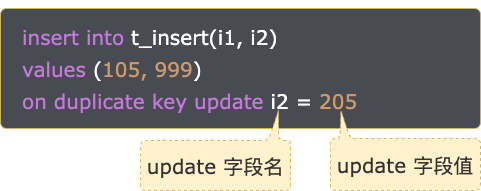
update 字段列表
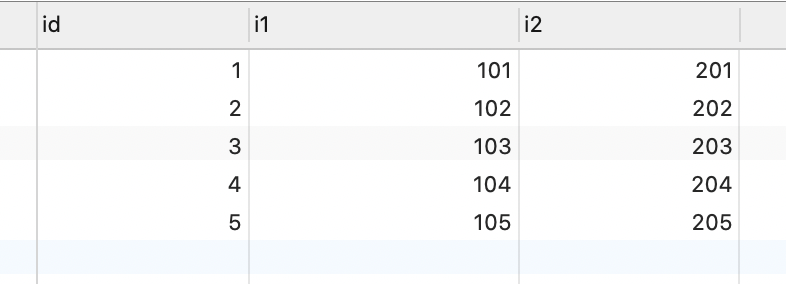
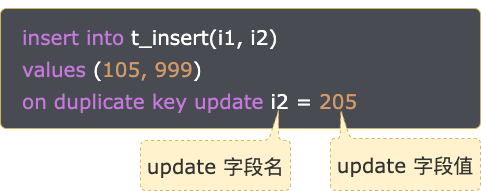
以 t_insert 表為例,i1 字段上有唯一索引,表中記錄如下:
示例 SQL 如下:
insert into t_insert(i1, i2)
values (105, 999)
on duplicate key update i2 = 205
示例 SQL 中,update i2 字段值和表中 i1 = 105 的記錄的 i2 字段值一樣。示例 SQL 既不會更新表中記錄,也不會往表中插入記錄。影響行數 = 插入行數(0) + 更新行數(0) = 0。
影響行數 = 2,表示插入記錄和表中記錄存在主鍵或唯一索引沖突,但是 insert duplicate 語句 update 字段列表中的字段值和沖突記錄中的字段值不一樣,插入語句會更新表中沖突的第 1 條記錄。
因為表中主鍵 + 唯一索引可能存在多個,插入一條記錄,該記錄中的多個字段可能和多條不同記錄存在沖突,這種情況下,insert duplicate 只會更新沖突的第 1 條記錄。
以 t_insert 表為例,i1 字段上有唯一索引,表中記錄如下:
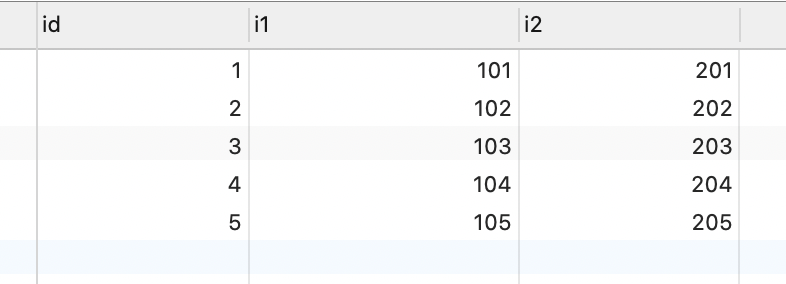
示例 SQL 如下:
-- i2 = 999 也可以寫成 i2 = values(i2)
insert into t_insert(i1, i2)
values (105, 999)
on duplicate key update i2 = 999
示例 SQL 中,update 字段列表中的 i2 字段值和表中 i1 = 105 的記錄的 i2 字段值(205)不一樣。
SQL 執行過程中,會把 i1 = 105 的記錄中的 i2 字段值更新為 999,執行結果為插入成功。插入行數加 1,但這個插入成功實際上是修改了表中已有記錄,修改行數也要加 1。影響行數 = 插入行數(1) + 更新行數(1) = 2。
(2) replace into
replace into 語句,插入一條記錄,影響行數可能的取值有兩種:1、N(大于 1)。影響行數 = 插入行數 + 刪除行數。
影響行數 = 1,表示插入記錄和表中記錄不存在主鍵或唯一索引沖突,插入操作可以直接成功。影響行數 = 插入行數(1) + 刪除行數(0) = 1。
影響行數 = N,表示插入記錄和表中的 N - 1 條記錄存在主鍵或唯一索引沖突,插入成功之前,會刪除這 N - 1 條沖突記錄。影響行數 = 插入行數(1) + 刪除行數(N - 1) = N。
主鍵和唯一索引中都不允許存在重復記錄,為什么 replace into 語句插入一條記錄會和表中多條記錄存在沖突?
因為一個表中,主鍵 + 唯一索引可能有多個,插入記錄中不同字段可能會和不同的記錄產生沖突。
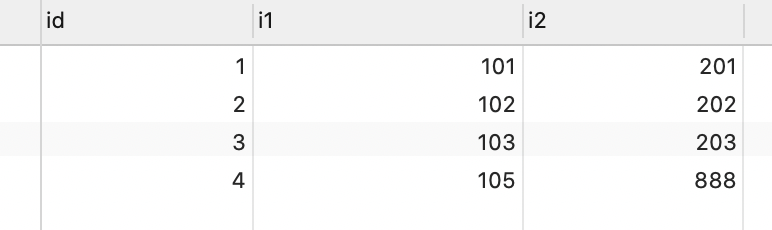
以 t_insert 表為例,id 為主鍵字段,i1 字段上有唯一索引。t_insert 表中記錄如下:
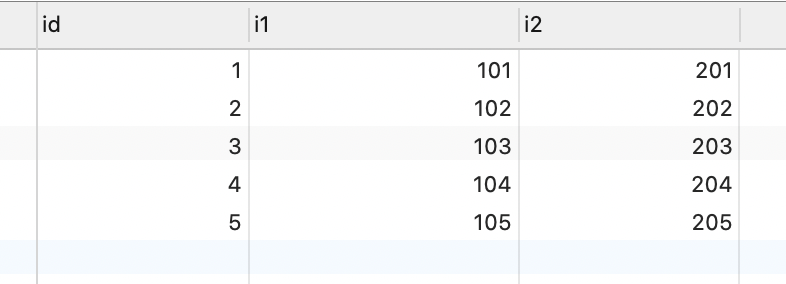
示例 SQL 如下:
replace into t_insert(id, i1, i2)
values (4, 105, 888)
示例 SQL 中,待插入記錄的 id = 4,和主鍵沖突;待插入記錄的 i1 = 105,和 i1 字段上的唯一索引沖突。
replace into 語句執行過程中,會刪除 id = 4 和 i1 = 105 的兩條記錄,插入 id = 4、i1 = 105、i2 = 888 這條記錄。
也就是先刪除 2 條記錄,再插入 1 條記錄,影響行數 = 插入行數(1) + 刪除行數(2) = 3。
插入之后表中數據如下:
3、 執行過程分析
(1) insert ... on duplicate key update
insert duplicate 語句是 MySQL 對 SQL 標準的擴展,它有 2 種行為:
- 如果插入記錄和表中記錄不存在主鍵或唯一索引沖突,它和普通插入語句一樣。
- 如果插入記錄和表中記錄存在主鍵或唯一索引沖突,它不會插入失敗,而是會用 update 字段列表中的字段值更新沖突記錄對應的字段。
 update 字段列表
update 字段列表
insert duplicate 語句的影響行數,保存在 Statistics 類的實例屬性 copied 和 updated 中,計算公式:影響行數 = copied + updated。
copied 表示插入行數,updated 表示更新行數。
接下來,我們來看看 insert duplicate 語句的執行過程。
insert duplicate 執行流程圖
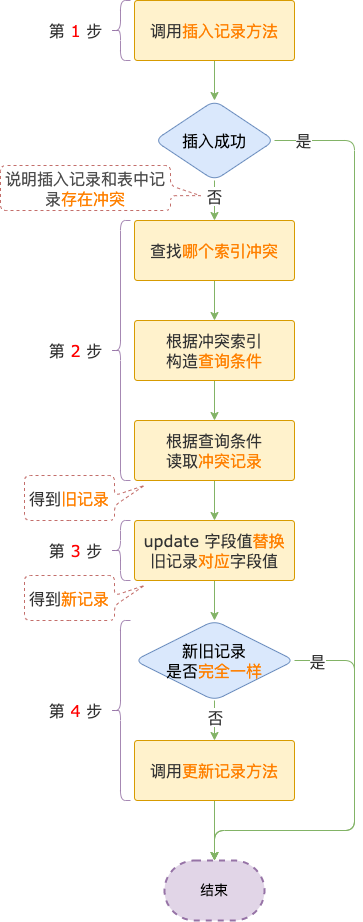
第 1 步,調用插入記錄方法,如果插入成功,插入操作主流程就完成了,不需要執行第 2 ~ 4 步。影響行數 = copied(1) + updated(0) = 1。
第 2 步,如果因為主鍵或唯一索引沖突導致插入失敗,MySQL 會找到是因為哪一個索引沖突造成的,然后構造由這個索引的所有字段組成的查詢條件,去存儲引擎讀取沖突的記錄,讀取出來的這條記錄叫作舊記錄。
第 3 步,用 insert duplicate 語句 update 字段列表中的字段值替換舊記錄中對應字段的值后得到新記錄。
第 4 步,判斷新記錄和舊記錄的內容是否完全一樣。
如果完全一樣,就不需要進行更新操作,影響行數 = copied(0) + updated(0) = 0。
如果不完全一樣,調用更新記錄方法,把新記錄各字段的值更新到表中,影響行數 = copied(1) + updated(1) = 2。
有一點需要注意,如果待插入記錄和表中多條記錄存在主鍵或唯一索引沖突,insert duplicate 只會更新沖突的第 1 條記錄。哪個索引報記錄沖突,就更新這個索引中沖突的這條記錄。
(2) replace into
replace into 語句也是對標準 SQL 的擴展,它也有 2 種行為:
- 如果插入記錄和表中記錄不存在主鍵或唯一索引沖突,它和普通插入語句一樣。
- 如果插入記錄和表中記錄存在主鍵或唯一索引沖突,它會先刪除表中的沖突記錄,然后插入新記錄,這很符合 replace into 語句替換的語義。
除了先刪除再插入,還有另一種方式:用 replace into 語句 values() 中各字段的值更新表中的沖突記錄。不過,要使用這種方式,需要滿足一些條件,后面會詳細說。
replace into 語句的影響行數,保存在 Statistics 類的實例屬性 copied 和 deleted 中,計算公式:影響行數 = copied + deleted。
copied 表示插入行數,deleted 表示刪除行數。
接下來,我們來看一下 replace into 語句的執行過程:
replace into 執行流程圖
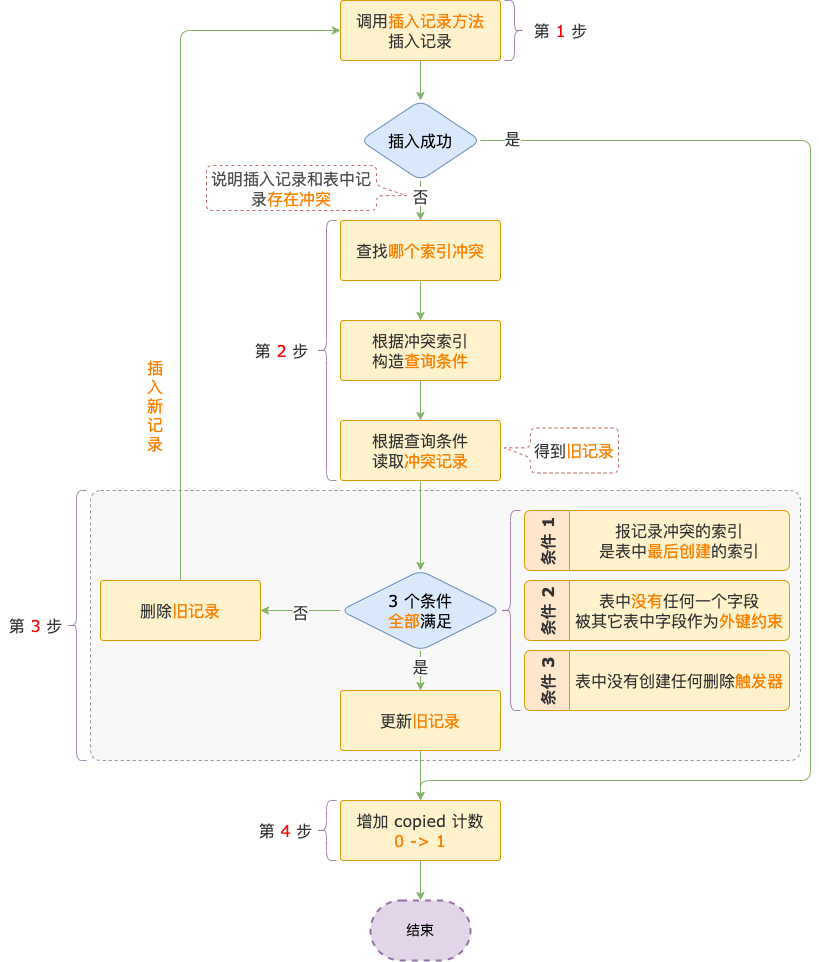
第 1 步,調用插入記錄方法,如果插入成功,插入操作主流程就完成了,不需要執行第 2 ~ 3 步。影響行數 = copied(1) + deleted(0) = 1。
這一步和 insert duplicate 語句是一樣的,因為它們倆在這一步執行的是同一行代碼,兄弟倆還沒有分家。
第 2 步,如果因為主鍵或唯一索引沖突導致插入失敗,MySQL 會找到是因為哪一個索引沖突造成的,然后構造由這個索引的所有字段組成的查詢條件,從存儲引擎讀取沖突的記錄,讀取出來的這條記錄叫作舊記錄。
舊記錄用于第 3 步中刪除沖突記錄,以及判斷需要把插入記錄中的哪些字段更新到表中。
這一步和 insert duplicate 語句也是一樣的,因為在這一步它們執行的是同一段代碼,兄弟倆還沒有分家。
第 3 步,從這一步開始,replace into 和 insert duplicate 的邏輯就不一樣了。
在這一步,MySQL 會根據一些條件判斷是用更新舊記錄,還是刪除舊記錄,插入新記錄的方式來實現 replace into 操作。
使用更新舊記錄方式,如果能夠使用這種方式實現 replace into,說明插入記錄只和表中的一條記錄沖突,把待插入記錄各字段的值更新到舊記錄中,增加 deleted 計數,replace into 主流程就完成了。
因為 replace into 的語義是替換,也就是刪除舊記錄,插入新記錄,所以,雖然這里用的是更新舊記錄的方式,但計數還是用了 deleted 而不是 updated。
使用刪除舊記錄,插入新記錄方式,第 1 ~ 3 步是一個循環,在第 3 步會直接把沖突的第一條記錄刪除,然后再回到第 1 步執行插入操作,循環執行第 1~ 3 步,直到刪除了所有沖突記錄之后,插入才能夠成功。
如果多次執行第 3 步,每次執行時,deleted 計數都會加 1。
第 4 步,增加 copied 計數,copied 值由 0 變為 1。
如果第 3 步使用更新舊記錄方式實現,影響行數 = copied(1) + deleted(1) = 2。
如果第 3 步使用刪除舊記錄,插入新記錄方式實現,第 3 步有可能會多次執行,執行幾次,deleted 值就是幾,影響行數 = copied(1) + deleted(N) = 1 + N。
其中,N 表示第 3 步的執行次數。
執行流程中還有一個邏輯沒有說,就是第 3 步中,怎么決定使用更新舊記錄方式還是刪除舊記錄,插入新記錄方式。
使用更新舊記錄方式,需要同時滿足 3 個條件:
條件 1,第 2 步中報記錄沖突的那個索引是表中最后創建的唯一索引(也可能是主鍵)。
條件 2,表中的所有字段,都沒有被其它表的字段作為外鍵約束。
條件 3,表上沒有定義過刪除觸發器。
外鍵約束和刪除觸發器都很少使用,不展開講了。
4、 總結
先說結論小節,先介紹了 insert ... on duplicate key update 語句執行成功之后,影響行數可能的 3 種取值:0、1、2,以及對每一種取值進行了比較詳細的說明。
然后介紹了 replace into 語句執行成功之后,影響行數可能的 2 種取值:1、N(大于 1 的整數),以及對這兩種取值進行了比較詳細的說明。
執行過程分析小節,詳細分析了 insert ... on duplicate key update 語句、replace into 語句的執行過程。
本文轉載自微信公眾號「一樹一溪」,可以通過以下二維碼關注。轉載本文請聯系一樹一溪公眾號。





























