作者 | 劉昱明
一、背景
在游戲場景內,通常有著各種各樣的玩法數值設計。由于不同用戶在偏好、游戲經驗等方面存在差異,因此同一數值并不適用于所有用戶。例如一個闖關游戲,對于新手來說,設置關卡的難度系數可以比有豐富經驗的老玩家低一些。為了讓用戶能夠有更好的游戲體驗,我們可以基于算法對用戶進行個性化的數值調控,從而提升用戶在游戲內的時長、留存等。
傳統的監督學習方式聚焦于響應結果 Y 的預估,而我們場景更關注于變量的變化對于結果 Y 的影響。在業界,這類問題通常會放在因果推斷(Causal Inference)的框架下進行討論,我們通常將變量稱為 T(treatment),變量變化帶來結果 Y 的變化稱為 TE(treatment effect),用來預估 TE 的模型稱為因果模型(Uplift Model)。
目前業界中比較常用的因果模型有 meta-learner、dml、因果森林等,但是不同因果模型的優劣勢及實際表現還沒有做過很全面的對比。因此在我們場景中,我們對上述這些問題進行了詳細的探索。
本文將從理論及實踐兩方面,對比及分析不同因果模型的優缺點及適用場景,希望能夠為大家在后續處理相似問題時,提供啟發及幫助。
二、常見模型介紹
2.1 Meta-learner
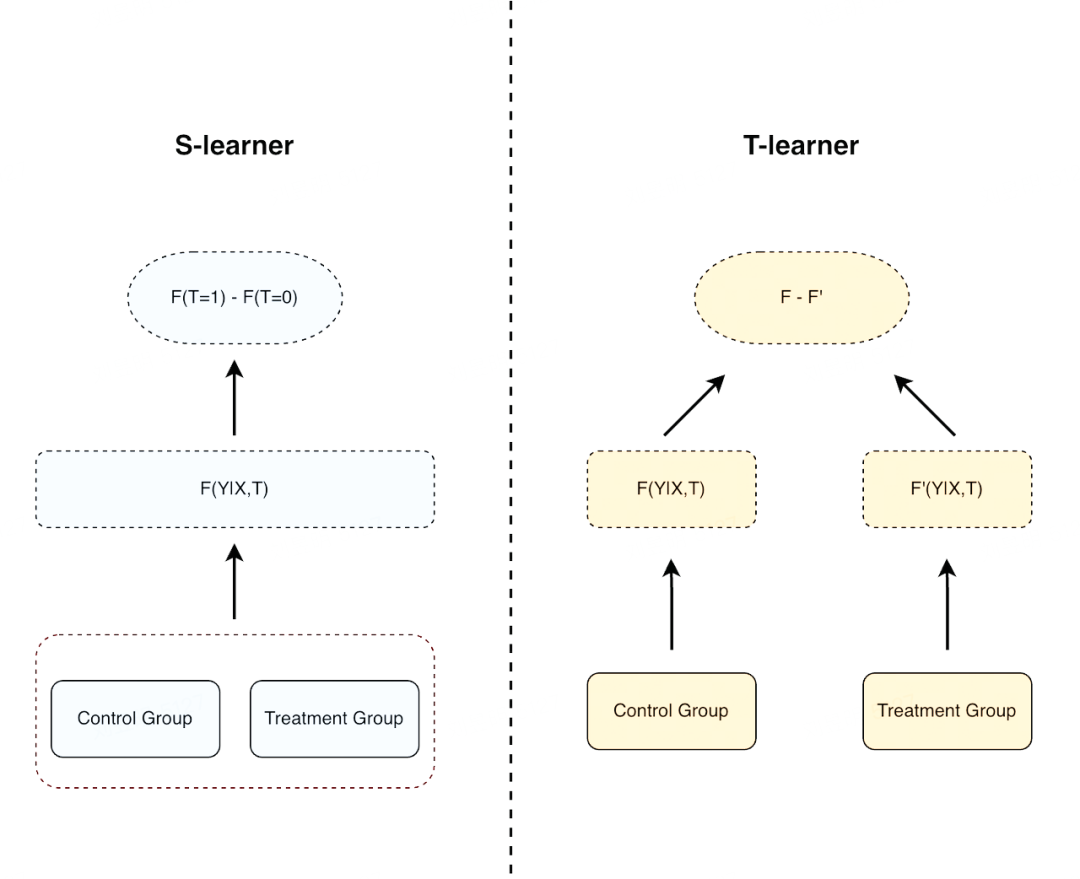
meta-learner 是目前主流的因果建模方式之一,其做法是使用基礎的機器學習模型去預估不同 treatment 的 conditional average treatment effect(CATE),常見的方法有:s-learner、t-learner。meta-learner 的思路比較簡單,本質上都是使用 base-learner 去學習用戶在不同 treatment 組中的 Y,再相減得到 te。區別在于在 s-learner 中,所有 treatment 的數據都是在一個模型中訓練,treatment 通常會作為模型的一個輸入特征。而 t-learner 會針對每個 treatment 組都訓練一個模型。
2.2 Double machine learning
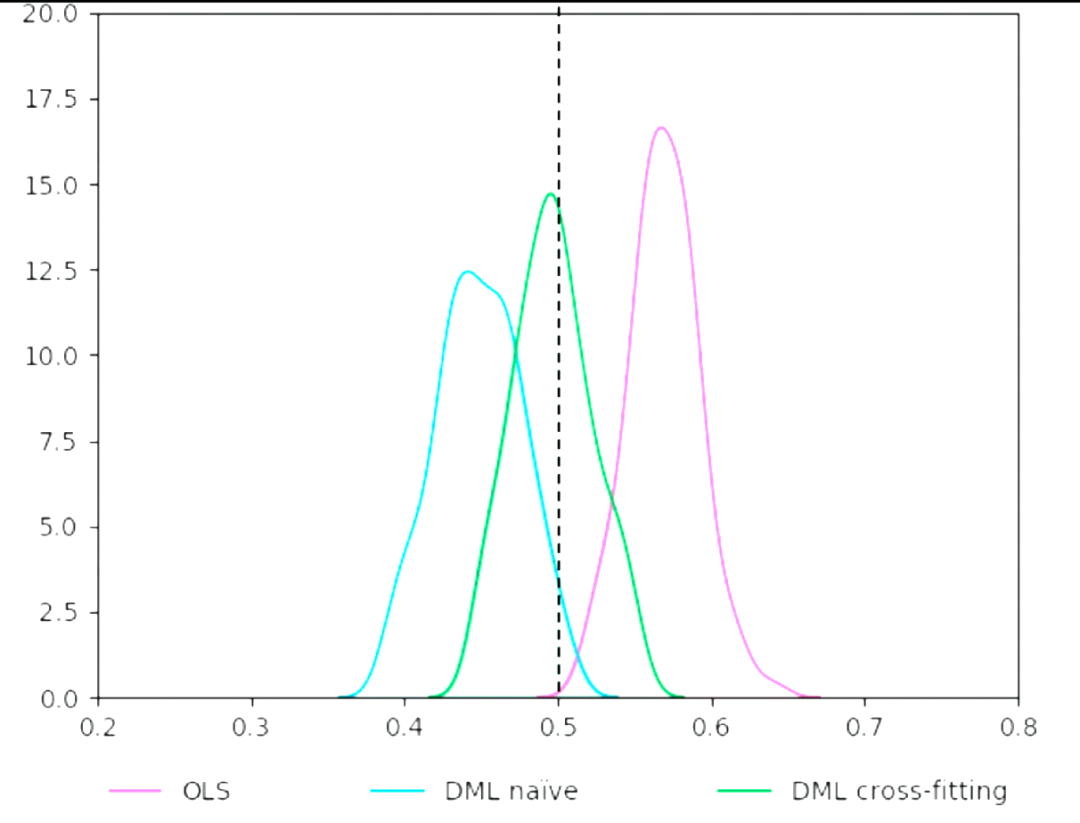
在 meta-learner 中,中間變量的預測誤差導致我們在進行 uplift 預估時天生存在 bias。為了解決該問題,DML 引入了殘差擬合、cross fitting 等方式進行消偏處理,最終得到了無偏估計。

DML 的核心思想就是通過擬合殘差,來消除中間變量的 bias 的影響。論文中證實了誤差的收斂速度快于 n^(-1/4),確保了最終預估結果的收斂性。下圖展示了論文中不使用 DML、使用 DML 但不使用 cross fitting、使用 DML-cross fitting 的效果對比:
2.3 Generalized Random Forests
GRF 是一種廣義的隨機森林算法,和傳統的隨機森林算法的不同點在于,傳統的隨機森林算法在做 split 時,是找 loss 下降最大的方向進行劃分,而 GRF 的思想是找到一種劃分方式,能夠最大化兩個子節點對于干預效果之間的差異。和隨機森林相同,GRF 也需要構建多棵樹。在每次建樹時,也需要隨機無放回的進行抽樣,抽取出來的樣本一半用來建樹、一半用來評估。
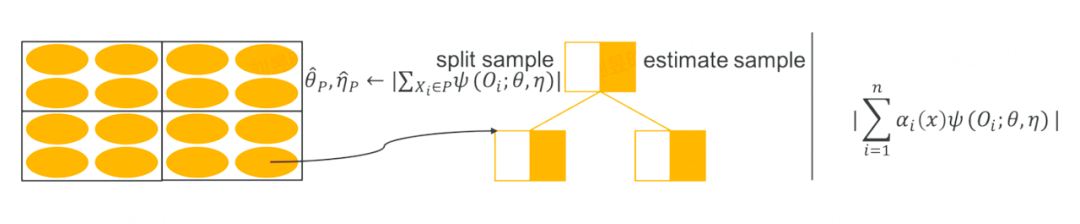
GRF 算法延續了 DML 的思想,在第一階段時,使用任意的機器模型去擬合殘差。第二階段時,GRF 算法引入了得分函數 Ψ(Oi)、目標函數 θ(x)和輔助函數 v(x),其中得分函數的計算公式為:
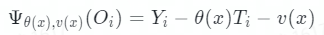
很容易看出,得分函數 Ψ(Oi)其實就是殘差,由公式 Y = θ(x)T + v(x)得到的。算法尋求滿足局部估計等式的 θ(x):對于所有 x,滿足:
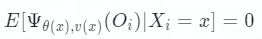
其實本質上也是學習 θ(x),使得實驗組和對照組數據的預估結果與真實值之差最小。
三、評估方式
目前因果模型常見的評估方式有兩種:uplift bins 及 uplift curve
3.1 Uplift bins
將訓練好的模型分別預測實驗組和對照組的測試集數據,可以分別得到兩組人群的 uplift score。按照 uplift score 的降序進行排列,分別截取 top10%、top20% .... top100%的用戶,計算每一分位下兩組人群分值的差異,這個差異可以近似認為是該分位下對應人群的真實 uplift 值。uplift bins 的缺陷在于,只能做一個定性的分析,無法比較不同模型效果好壞。
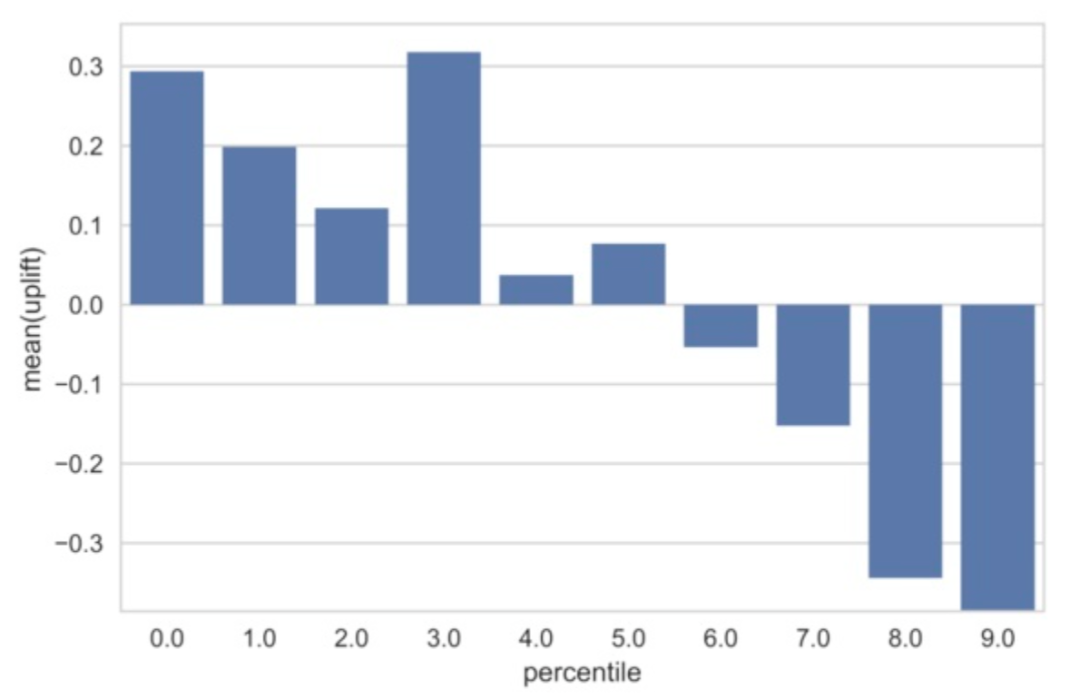
3.2 Qini curve
在 uplift bins 的基礎上,我們可以繪制一條曲線,用類似于 AUC 的方式來評價模型的表現,這條曲線稱為 uplift curve;我們將數據組的數據不斷細分,精確到樣本維度時,每次計算截止前 t 個樣本的增量時,得到對應的 uplift curve。
計算公式為:
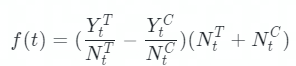
其中 Y_t^T 代表前 t 個樣本增量時,實驗組樣本轉化量,N_t^T 代表實驗組的累計到 t 時,實驗組樣本總量,對照組同理。
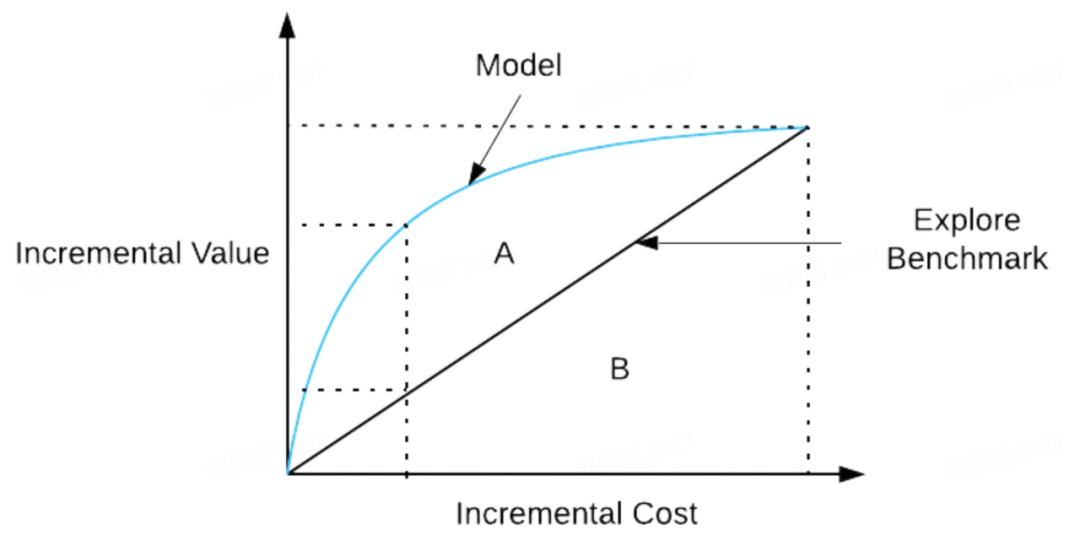
如上圖,藍線代表的 uplift curve,實黑線代表 random 的效果,兩者之間的面積作為模型的評價指標,其面積越大越好,表示模型的效果比隨機選擇的結果好的更多。與 AUC 類似,這個指標我們稱為 AUUC(Area Under Uplift Curve)。
四、業務應用
4.1 樣本準備
因果建模對于樣本的要求比較高,需要樣本服從 CIA(conditional independence assumption)條件獨立假設,即樣本特征 X 與 T 相互獨立。因此在進行因果建模前,需要進行隨機實驗進行樣本收集,通常是通過 A/B 的方式將用戶隨機的分配至不同的 treatment 中,觀測用戶在不同 treatment 下的表現。
4.2 樣本構造
樣本構造與常規機器學習的樣本構造步驟基本一致,但是需要特別關注以下方面:
特征關聯:用戶特征 X 必須嚴格使用進入隨機實驗組前的特征,例如:用戶 T 日進入實驗組,那么用戶的特征必須使用 T-1 日及以前的特征。這樣做的原因是用戶進入 treatment 后,部分特征可能已經受到 treatment 的影響發生了改變,使用受影響后的特征進行模型訓練有幾率造成信息泄露,對模型的效果造成比較大的影響甚至起反向的作用。
目標選擇:在某些場景中,treatment 的影響需要一段時間才能夠產生作用,例如道具數量的調整對用戶留存的影響可能需要過一段時間才能體現。因此在選擇目標時,可以選擇更長周期的目標,例如相比于次日留存,選擇 7 日留存或 14 日留存會更優。不過也不是越長周期越好,因為越長周期的目標有可能導致模型的學習成本增加從而效果下降,這種情形在小樣本的場景更為突出。選擇一個合適的目標能夠很大程度上提升模型的線上表現。
4.3 模型訓練
在我們的場景中,用戶每次完成任務發放的道具數量為 treatment,用戶留存以及用戶活躍時長變化為我們關注的 uplift。實驗過程中,我們先后對比了 s-learner、t-learner 以及 dml 的效果,三種模型選擇的 base-learner 都為 lightgbm。
在實驗的過程中,我們發現,當使用 s-learner 對活躍時長進行建模時,無論如何調試模型,得到的 treatment effect 都為 0,即用戶在不同 treatment 下的活躍時長預測結果相同。但是當我們將模型換成 t-learner 或 dml 時,treatment effect 數據恢復正常。輸出 s-learner 的特征重要度,我們發現 treatment 特征的重要度為 0。我們對用戶在不同 treatment 下活躍數據進行分析,發現不同組的活躍數據彈性很小,即用戶在不同 treatment 下的活躍改變很小。
而 s-learner 對于這種微弱的改動敏感度很低,因此效果不佳。而 t-learner 在進行訓練時,會針對每個 treatment 都訓練一個模型,相當于顯性的將 treatment 的特征重要度加大,而 dml 在訓練過程中主要關注訓練的殘差,因此這兩類模型的效果都要好于 s-learner。這也反映了 s-learner 在數據彈性不足時的效果缺陷,因此在后續的訓練中,我們放棄了 s-learner,主要關注在 t-learner 以及 dml 上。
后續在不同指標的離線評估上,dml 模型的效果都要顯著優于 t-learner。這也與理論相互印證:t-learner 由于引入中間變量,中間變量的誤差使得對于最終 uplift 的預估有偏,而 dml 通過擬合殘差,最終實現了無偏估計。
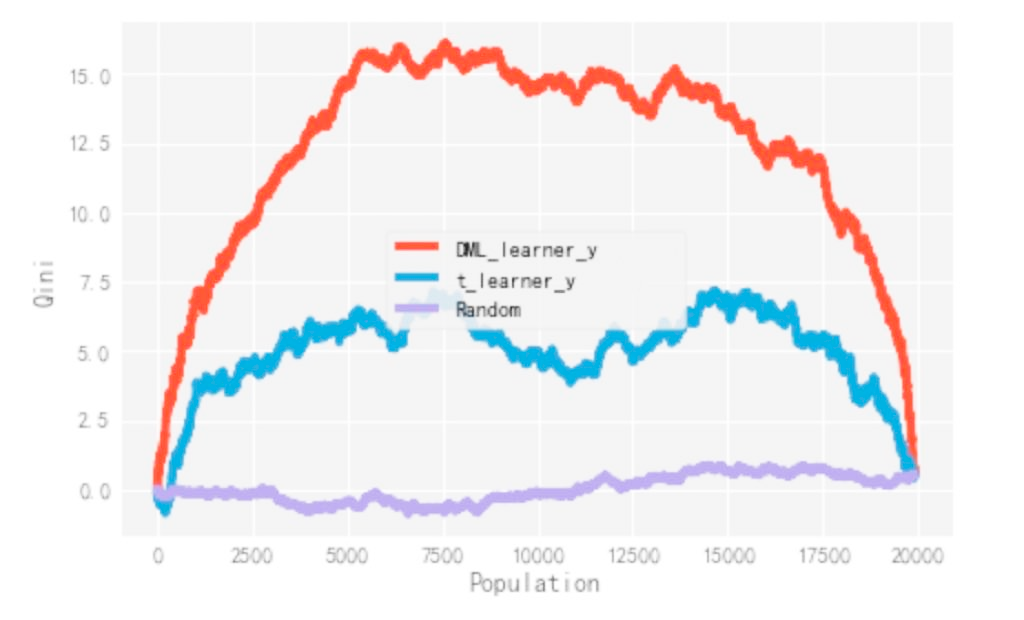
4.4 人群分配
根據訓練效果,我們選擇 dml 作為最終的預估模型,并得到了用戶在不同 treatment 下的 uplift 值。我們會根據用戶在不同 treatment 下的 uplift 值,對用戶做人群分配。分配方案基于實際情況主要分為兩種:有無約束條件下的人群分配及有約束條件下的人群分配。
無約束條件下的人群分配:只關心優化指標,不關心其他指標的變化。那么我們可以基于貪心的思想,選擇每個用戶 uplift 值最高的策略進行人群分配。
有約束條件下的人群分配:關注優化指標的同時,對于其他指標的變化也有一定的約束。我們可以通過約束求解的方式對該類問題進行求解。
在我們的業務場景下,我們同時對用戶留存、活躍時長、流水等目標都有限制,因此進行了有約束條件下的人群分配方案。
4.5 實驗效果
基于訓練好的 dml 模型及約束分配后的結果,我們開啟了線上 A/B 實驗。在經過多周的測試后,相較于基準策略,我們的策略在流水、活躍等指標不降的情況,取得了置信的 10%+留存收益。目前我們基于因果模型的策略已經全量上線。
五、總結及后續展望
因果模型目前在互聯網各大場景都得到了實踐及應用,并取得了不錯的收益。隨著營銷活動越來越多,營銷手段越來越復雜,treatment 的維度也由常見的多 treatment 逐漸變為連續 treatment,這對于樣本、模型學習能力等方面的要求也越來越嚴格。在后續工作開展,可以考慮從多目標建模、場景聯動、無偏估計、強化學習等方面繼續進行優化,為各個業務場景產生更大價值。