搞定這8個Kafka生產級容量評估,每日10億+請求輕松拿捏!
一、kafka容量評估需求場景分析
1、集群如何每天hold住10億+請求
拿電商平臺為例,kafka 集群每天需要承載10億+請求流量數據,一天24小時,對于平臺來說,晚上12點到凌晨8點這8個小時幾乎沒多少數據涌入的。這里我們使用「二八法則」來進行預估,也就是80%的數據(8億)會在剩余的16個小時涌入,且8億中的80%的數據(約6.4億)會在這16個小時的20%時間 (約3小時)涌入。
通過上面的場景分析,可以得出如下:
QPS計算公式 = 640000000 ÷ (3 * 60 * 60) = 6萬,也就是說高峰期集群需要扛住每秒6萬的并發請求。
假設每條數據平均按20kb(生產端有數據匯總)來算, 那就是 1000000000 * 20kb = 18T,一般情況下我們都會設置3個副本,即54T,另外 kafka 數據是有保留時間周期的, 一般情況是保留最近3天的數據,即 54T * 3 = 162T。
2、場景總結
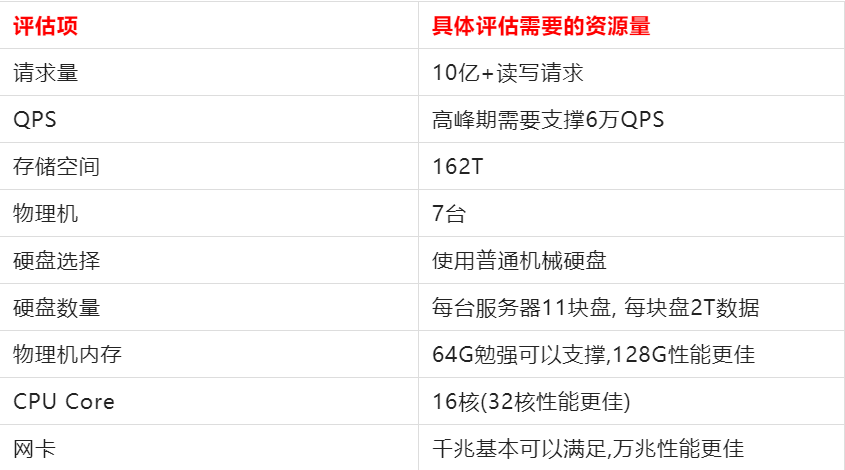
要搞定10億+請求,高峰期要支撐6萬QPS,需要大約162T的存儲空間。
二、kafka容量評估之物理機數量
1、物理機 OR 虛擬機
一般對于Kafka,Mysql,Hadoop 等集群自建的時候,都會使用物理機來進行搭建,性能和穩定性相對虛擬機要強很多。
2、物理機數量計算
在第一步中我們分析得出系統高峰期的時候要支撐6萬QPS,如果公司資金和資源充足的情況下,我們一般會讓高峰期的QPS控制在集群總承載QPS能力的30%左右,這樣的話可以得出集群能承載的總QPS能力約為20萬左右,這樣系統才會是安全的。
3、場景總結
根據經驗可以得出每臺物理機支撐4萬QPS是沒有問題的,從QPS角度分析,我們要支撐10億+請求,大約需要5臺物理機,考慮到消費者請求,需要增加約1.5倍機器,即7臺物理機。
三、kafka容量評估之磁盤
1、機械硬盤 OR 固態硬盤SSD
兩者主要區別如下:
- SSD就是固態硬盤,它的優點是速度快,日常的讀寫比機械硬盤快幾十倍上百倍。缺點是單位成本高,不適合做大容量存儲。
- HDD就是機械硬盤,它的優點是單位成本低,適合做大容量存儲,但速度遠不如SSD。
首先SSD硬盤性能好,主要是指的隨機讀寫能力性能好,非常適合Mysql這樣的集群,而SSD的順序讀寫性能跟機械硬盤的性能是差不多的。
Kafka 寫磁盤是順序追加寫的,所以對于 kafka 集群來說,我們使用普通機械硬盤就可以了。
2、每臺服務器需要多少塊硬盤
根據第一二步驟計算結果,我們需要7臺物理機,一共需要存儲162T數據,大約每臺機器需要存儲23T數據,根據以往經驗一般服務器配置11塊硬盤,這樣每塊硬盤大約存儲2T的數據就可以了,另外為了服務器性能和穩定性,我們一般要保留一部分空間,保守按每塊硬盤最大能存儲3T數據。
3、場景總結
要搞定10億+請求,需要7臺物理機,使用普通機械硬盤進行存儲,每臺服務器11塊硬盤,每塊硬盤存儲2T數據。
四、kafka容量評估之內存
1、Kafka 寫磁盤流程及內存分析
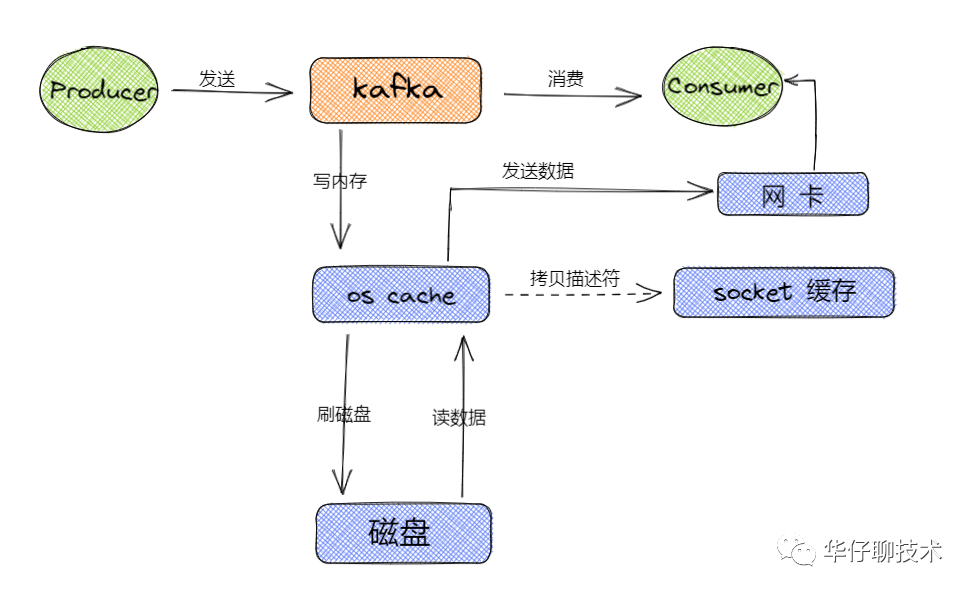
從上圖可以得出 Kafka 讀寫數據的流程主要都是基于os cache,所以基本上 Kafka 都是基于內存來進行數據流轉的,這樣的話要分配盡可能多的內存資源給os cache。
kafka的核心源碼基本都是用 scala 和 java (客戶端)寫的,底層都是基于 JVM 來運行的,所以要分配一定的內存給 JVM 以保證服務的穩定性。對于 Kafka 的設計,并沒有把很多的數據結構存儲到 JVM 中,所以根據經驗,給 JVM 分配6~10G就足夠了。
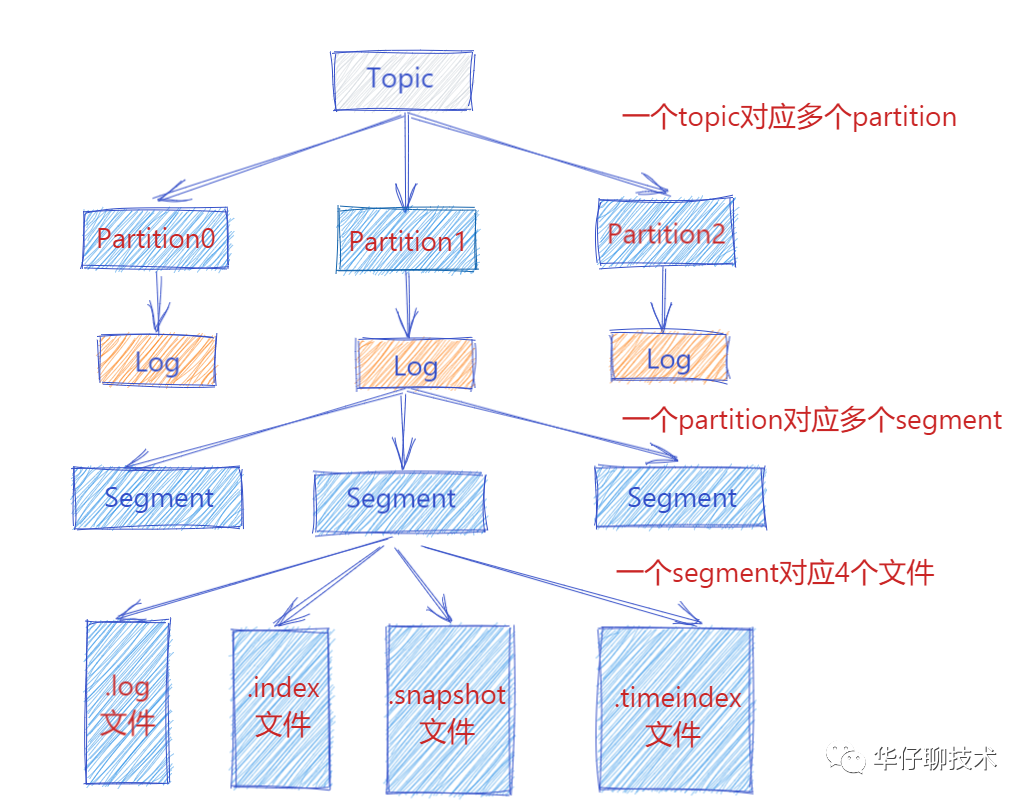
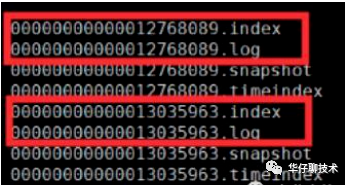
從上圖可以看出一個 Topic 會對于多個 partition,一個 partition 會對應多個 segment ,一個 segment 會對應磁盤上4個log文件。假設我們這個平臺總共100個 Topic ,那么總共有 100 Topic * 5 partition * 3 副本 = 1500 partition 。對于 partition 來說實際上就是物理機上一個文件目錄, .log就是存儲數據文件的,默認情況下一個.log日志文件大小為1G。
如果要保證這1500個 partition 的最新的 .log 文件的數據都在內存中,這樣性能當然是最好的,需要 1500 * 1G = 1500 G內存,但是我們沒有必要所有的數據都駐留到內存中,我們只保證25%左右的數據在內存中就可以了,這樣大概需要 1500 * 250M = 1500 * 0.25G = 375G內存,通過第二步分析結果,我們總共需要7臺物理機,這樣的話每臺服務器只需要約54G內存,外加上面分析的JVM的10G,總共需要64G內存。還要保留一部分內存給操作系統使用,故我們選擇128G內存的服務器是非常夠用了。
2、場景總結
要搞定10億+請求,需要7臺物理機,每臺物理機內存選擇128G內存為主,這樣內存會比較充裕。
五、kafka容量評估之CPU壓力
1、CPU Core分析
我們評估需要多少個 CPU Core,主要是看 Kafka 進程里會有多少個線程,線程主要是依托多核CPU來執行的,如果線程特別多,但是 CPU核很少,就會導致CPU負載很高,會導致整體工作線程執行的效率不高,性能也不會好。所以我們要保證CPU Core的充足,來保障系統的穩定性和性能最優。
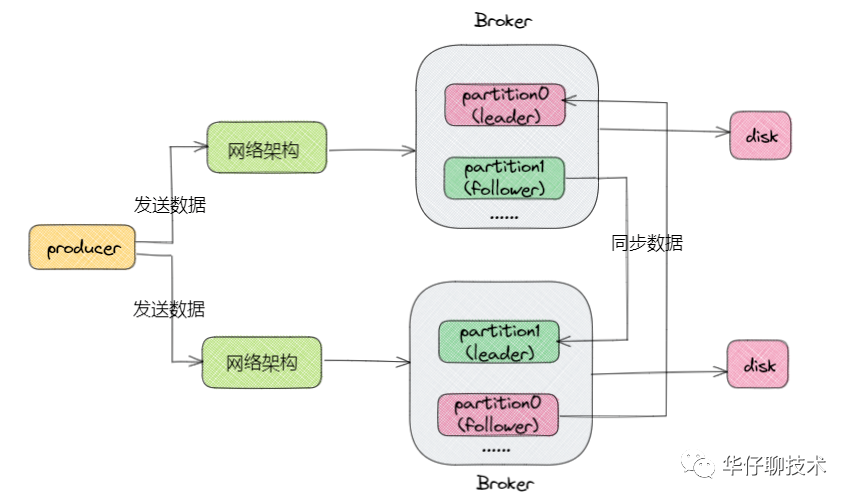
2、Kafka 網絡架構及線程數計算
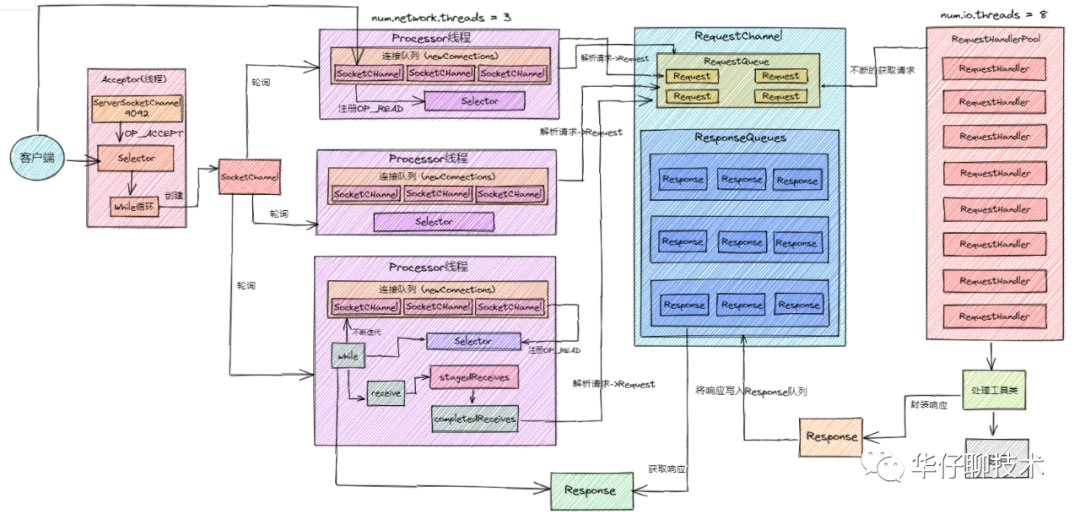
我們評估下 Kafka 服務器啟動后會有多少線程在跑,其實這部分內容跟kafka超高并發網絡架構密切相關,上圖是Kafka 超高并發網絡架構圖,從圖中我們可以分析得出:
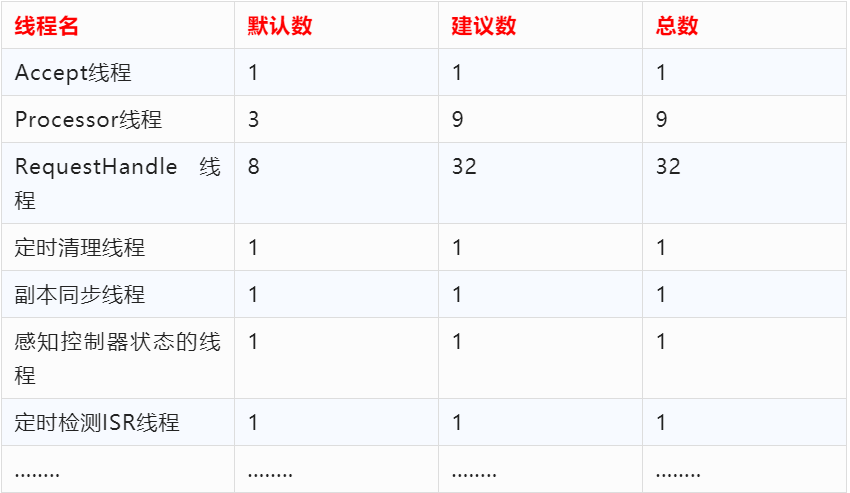
除了上圖所列的還有其他一些線程,所以估算下來,一個 kafka 服務啟動后,會有100多個線程在跑。

2、場景總結
要搞定10億+請求,需要7臺物理機,每臺物理機內存選擇128G內存為主,需要16個cpu core(32個性能更好)。
六、kafka容量評估之網卡
1、網卡對比分析

通過上圖分析可以得出千兆網卡和萬兆網卡的區別最大之處在于網口的傳輸速率的不同,千兆網卡的傳輸速率是1000Mbps,萬兆網卡的則是10Gbps萬兆網卡是千兆網卡傳輸速率的10倍。性能上講,萬兆網卡的性能肯定比千兆網卡要好。萬兆網卡現在主流的是10G的,發展趨勢正逐步面向40G、100G網卡。但還是要根據使用環境和預算來選擇投入,畢竟千兆網卡和萬兆網卡的性價比區間還是挺大的。
2、網卡選擇分析
根據第一二步分析結果,高峰期的時候,每秒會有大約6萬請求涌入,即每臺機器約1萬請求涌入(60000 / 7),每秒要接收的數據大小為: 10000 * 20 kb = 184 M/s,外加上數據副本的同步網絡請求,總共需要 184 * 3 = 552 M/s。
一般情況下,網卡帶寬是不會達到上限的,對于千兆網卡,我們能用的基本在700M左右,通過上面計算結果,千兆網卡基本可以滿足,萬兆網卡更好。
3、場景總結
要搞定10億+請求,需要7臺物理機,每臺物理機內存選擇128G內存為主,需要16個cpu core(32個性能更好),千兆網卡基本可以滿足,萬兆網卡更好。
4、kafka容量評估之核心參數
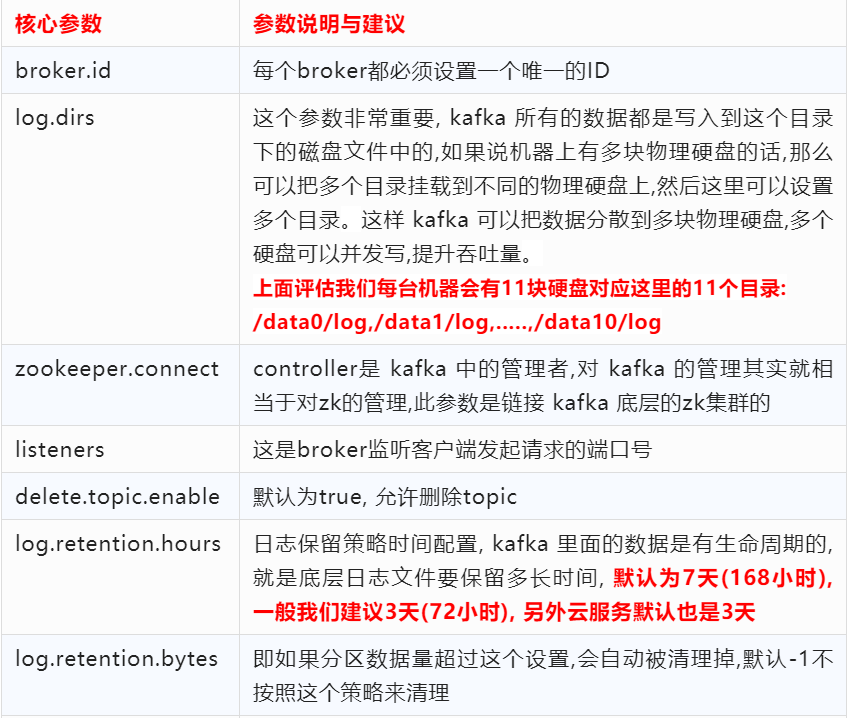

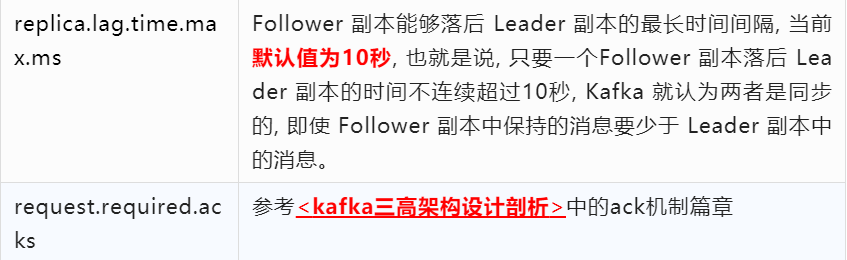
5、kafka容量評估之集群規劃
(1)集群部署規劃
這里我采用五臺服務器來構建 Kafka 集群,集群依賴 ZooKeeper,所以在部署 Kafka 之前,需要部署好 ZooKeeper 集群。這里我將 Kafka 和 ZooKeeper 部署在了一起,Kafka 集群節點操作系統仍然采用 Centos 7.7 版本,各個主機角色和軟件版本如下表所示:
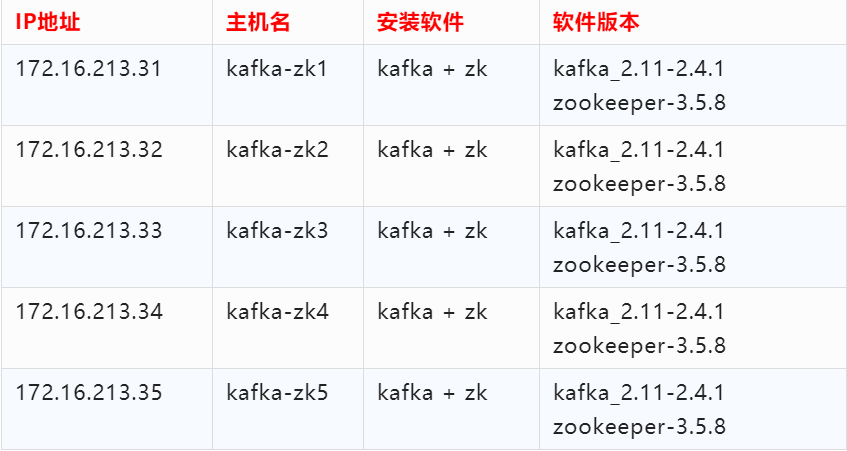
這里需要注意:Kafka 和 ZooKeeper 的版本,默認 Kafka2.11 版本自帶的 ZooKeeper 依賴 jar 包版本為 3.5.7,因此 ZooKeeper 的版本至少在 3.5.7 及以上。
(2)下載與安裝
Kafka 需要安裝 Java 運行環境,你可以點擊Kafka官網
(https://kafka.apache.org/downloads)獲取 Kafka 安裝包,推薦的版本是 kafka_2.11-2.4.1.tgz。將下載下來的安裝包直接解壓到一個路徑下即可完成 Kafka 的安裝,這里統一將 Kafka 安裝到 /usr/local 目錄下,我以在 kafka-zk1 主機為例,基本操作過程如下:
[root@kafkazk1~]# tar -zxvf kafka_2.11-2.4.1.tgz -C /usr/local
[root@kafkazk1~]# mv /usr/local/kafka_2.11-2.4.1 /usr/local/kafka
這里我創建了一個 Kafka 用戶,用來管理和維護 Kafka 集群,后面所有對 Kafka 的操作都通過此用戶來完成,執行如下操作進行創建用戶和授權:
[root@kafkazk1~]# useradd kafka
[root@kafkazk1~]# chown -R kafka:kafka /usr/local/kafka
在 kafka-zk1 節點安裝完成 Kafka 后,先進行配置 Kafka,等 Kafka 配置完成,再統一打包復制到其他兩個節點上。
broker.id=1
listeners=PLAINTEXT://172.16.213.31:9092
log.dirs=/usr/local/kafka/logs
num.partitions=6
log.retention.hours=72
log.segment.bytes=1073741824
zookeeper.connect=172.16.213.31:2181,172.16.213.32:2181,172.16.213.33:2181
auto.create.topics.enable=true
delete.topic.enable=true
num.network.threads=9
num.io.threads=32
message.max.bytes=10485760
log.flush.interval.message=10000
log.flush.interval.ms=1000
replica.lag.time.max.ms=10
Kafka 配置文件修改完成后,接著打包 Kafka 安裝程序,將程序復制到其他4個節點,然后進行解壓即可。注意,在其他4個節點上,broker.id 務必要修改,Kafka 集群中 broker.id 不能有相同的(唯一的)。
(3)啟動集群
五個節點的 Kafka 配置完成后,就可以啟動了,但在啟動 Kafka 集群前,需要確保 ZooKeeper 集群已經正常啟動。接著,依次在 Kafka 各個節點上執行如下命令即可:
[root@kafkazk1~]# cd /usr/local/kafka
[root@kafkazk1 kafka]# nohup bin/kafka-server-start.sh config/server.properties &
[root@kafkazk1 kafka]# jps
21840 Kafka
15593 Jps
15789 QuorumPeerMain
這里將 Kafka 放到后臺(deamon)運行,啟動后,會在啟動 Kafka 的當前目錄下生成一個 nohup.out 文件,可通過此文件查看 Kafka 的啟動和運行狀態。通過 jps 指令,可以看到有個 Kafka 標識,這是 Kafka 進程成功啟動的標志。
九、總結
整個場景總結:
要搞定10億+請求,經過上面深度剖析評估后需要以下資源: