作者 | 杜嘉平

為什么要探討這個話題
探討這個話題的本質原因是來源于為客戶提供數據戰略咨詢服務時的思考,很多客戶的痛點與訴求看似可以用機器學習解決,但實際上卻充滿風險,所以究竟機器學習什么時候該用,什么時候不該用,便成為了思考的對象。
機器學習起源于學術界,但再也不會是一件學術上的事情了。我們會在日常生活中聽到大量機器學習的應用,很多商業產品與業務流程中也紛紛開始了機器學習的應用。盡管機器學習一直在被廣泛的使用,但是并不是任何看起來像是機器學習能解決的事情,都能夠被機器學習所解決,或者說在很多情況下,機器學習并不是最優解。
一旦在解決問題的一開始就選擇了錯誤的解決方案,那么之后對于機器學習解決方案進行持續運營的MLOps也就變得毫無意義。在開始一項機器學習項目之前,我們必須反復對業務價值、業務流程、數據可行性、數據完備性等幾個維度進行研究,以確定使用機器學習的必要性。因為但凡公司決定使用機器學習,那么其前期沒有回報的投資成本將會是非常巨大的,投資回報率將是極小。
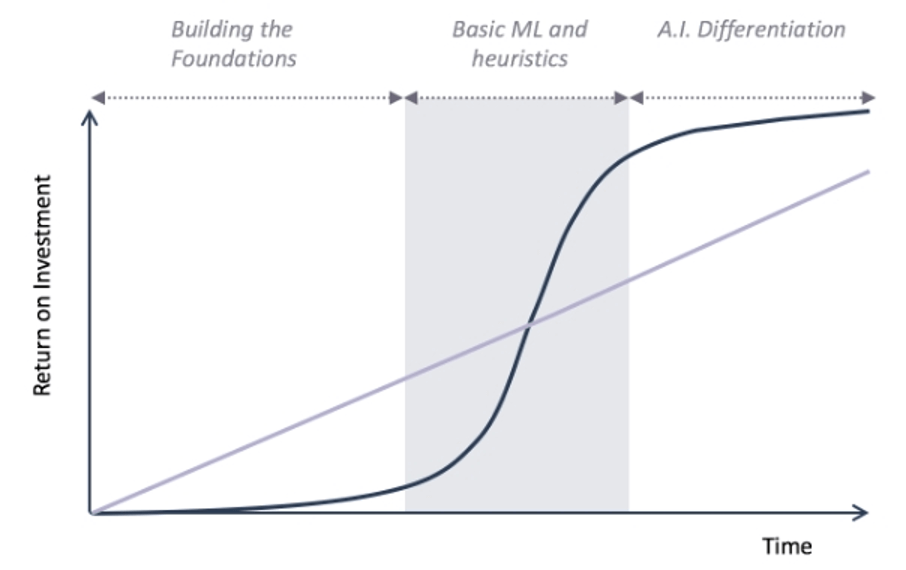
圖片來源:https://venturebeat.com/2018/11/24/before-you-launch-your-machine-learning-model-start-with-an-mvp/
什么時候該使用機器學習?
機器學習的目的:更精準地替代經驗以及更大面積復用人工。在這個文章中,要回答什么時候該用機器學習,我們需要回答一個更為本質的問題,什么是機器學習?
這里我將這個答案拆分成由幾個要素組成的一句話:
通過(1)重復(2)學習(3)復雜(4)歷史數據的(5)規律特征,將學習成果(6)規模化地應用于(7)未來數據中以得到(8)預測結果,來倒推所有要素的滿足條件,所有要素都滿足條件,那么才是真正該用機器學習的時候。
1. 重復:相對大量的訓練集數據
如果教一個沒有見過貓狗的小朋友區別貓狗,我想只需要給他10張左右的貓貓和狗狗的照片之后,他就能很好的識別出貓和狗的特征以區分貓狗了。但是如果只給機器學習模型提供10張圖片進行學習,那學習效果一定是很差的。所以我們需要利用擁有同樣特征規律的重復性的數據,對模型進行訓練,所以機器學習的使用,一定是要在大量訓練集數據的前提下進行的。如果我們存在的歷史數據不能夠滿足模型的學習效果,那么我們可能需要再等等,積攢更多的數據了。

圖片來源:https://ypw.io/dogs-vs-cats/
2. 學習:機器學習應該有足夠能力去學習
在我的一些咨詢項目中,很多業務人員都會使用Excel通過對于一列或兩列數據的規則計算得到第三列數據(前提不是時間序列數據)。這是一個很常見的Excel應用場景,因為在整個過程中不存在很強“學習”的過程。當他們提出希望,能夠通過機器學習智能化地得到結果這種需求,我一定不會建議客戶上機器學習,因為這點小事,機器學習不夠學。
對于機器學習的學習過程而言,首先必須要有足夠的知識讓模型去學習,這個知識就是數據。通過對于大量數據學習,產生相應的結果是機器學習的普遍過程,例如在預測Airbnb租價,模型需要學習大量房屋特征、房屋地理屬性、以及歷史租價等數據對于“數據->結果”這一關系進行學習,在新數據喂進模型時,才能夠通過學習成果預測出相應的租價。
當然,模型和學生一樣,有好學生和壞學生,如何評判學得好還是學得差,就是需要用一個objective function來判別的,舉個簡單的例子:MAE(Mean Absolute Error)。這個function在驗證(validation)的時候就會寫入驗證方法,以對于模型的學習效果產生最終的客觀評價。
總而言之,對于機器學習不要大材小用,所應用的場景應該是有能力去學習、有潛力去學習、有數據去學習,那才能夠滿足“學習”這個元素的要求。
3. 復雜:數據的規律特征要復雜
A,B,C
1,1,2;
2,2,4;
2,3,5;
給你上面一組數據,你是否能看出其中的規律特征?大膽地說,只要你上過小學2年級,就一定能夠一眼看出這是C=1A+1B的簡單規律。這樣的數據可以使用機器學習進行學習嗎?可以,就是個最簡單不過的線性回歸模型(Liner regression model)。但應該使用機器學習模型嗎?當然不應該。再比如通過郵箱編碼來識別所在地區或是通過身份證號識別你的戶口所在地這些簡單應用,也是簡單規律,規則引擎就可以實現這樣的預測。
但是通過學習房屋特征(地板材質、墻面材質、面積大小、房屋年齡、房屋建造結構)以及地理屬性(是否臨街、所在區域、是否存在地鐵、周圍配套情況)以及歷史二手房交易價格,得到的二手房交易價格預測模型,就是一個很典型的機器學習應用場景。因為盡管我們知道房屋特征、地理屬性這些多維度的變量與二手房交易價格之間存在規律特征,但這種規律特征足夠復雜,以至于有必要借助機器學習對于規律特征進行探索。
4. 歷史數據:必須存在可以采集的歷史數據
之所以要強調這一點,是因為在以往對于某些500強企業的數字化戰略咨詢中,有一些很常見的需求就是領導希望預測一些目標值,并且預測的場景也確實足夠具有業務價值,但問題是歷史數據全部靠手工采集,通過Excel每天進行手動記錄,客戶希望我們通過智能模型來滿足領導對于目標值預測的需求。
接到這種需求和問題,我會自動將其識別為“數字化需求”而不是“智能化”需求,解決方案也是會幫助客戶梳理業務流程與系統觸點,幫助其采集模型所需要的數據形成數據資產。只有對于數據的數字化采集才能形成大量歷史數據,并且能夠在未來MLOps中,提供相應的運營依據與模型優化條件。
所以在這一點,歷史數據存在并且可采集,才是滿足機器學習應用在“歷史數據”這一要素的滿足條件。
5. 規律特征:規律特征是可學習的
機器學習模型的應用必須要在有規律可以學習的情況下產生作用的。一個智商正常的人肯定不會投資大量金錢來建立一個用來預測骰子投擲結果的機器學習系統,因為擲骰子結果的產生方式是沒有規律的。
當然,規律特征是否存在,有些時候確實不是那么明顯,所以這就需要引入ML MVP的概念,通過經驗無法判斷是否存在規律特征的項目,我們需要進行快速驗證,通過模型的結果來得到一個更加理性客觀的結果,以判斷規律特征是否存在,是否可學習。
6. 可以規模化使用
在我建模在后,策略先行這篇文章中,提到機器學習的兩大作用,1)超越人類經驗,2)重復利用替代人工。所以一個機器學習的重復利用能力是非常重要的。投資人投入金錢建立模型,不會就想模型利用一兩次然后就廢掉。所以一個可以將機器學習重復利用的應用場景是非常重要的。
7. 未來數據:未來數據的特征和模型訓練數據特征相符
機器學習的核心是經驗的復用。所以只有未來數據的特征與訓練模型時訓練集數據的特征相符時,機器學習模型才能夠把經驗復用,否則將派不上任何用場。如果用2010年的房產數據訓練的二手房成交價預測模型來預測2021那年的二手房成交價,很顯然模型將不會準確預測出結果,因為整個描述房屋與價格的訓練集數據應該算是今非昔比。
這也更加說明了機器學習模型更新的重要性,因為數據會逐步迭代,所以模型的訓練也要進行逐步迭代以保證保質期的延長。
但是這存在一個問題,你怎么知道你的未來數據能夠與模型訓練時的數據特征相符?好問題,我們沒辦法知道,所以需要進行假設,我們一般認為如果不發生業務上的大變化,只要時間跨度不長,那么新老數據就是特征相符的。當然,這一點大可不必過多擔心,以為MLOps的數據監控與模型監控能夠很好的對于數據特征變化進行識別,一旦出現識別出數據特征的變化,整個體系會立即觸發Pipeline Trigger對于模型啟動重新訓練機制。關于pipeline trigger內容可以參考之前寫過的文章:不要讓機器學習模型成為孤兒。
8. 預測:解決的問題是一個預測類的問題
機器學習算法就是用來進行預測的,所以機器學習所能夠解決的問題,就是一個預測性的問題。回歸算法預測數值、分類算法預測分類值、聚類算法預測聚類組,雖然所預測的結果維度不一樣,但是他們最終得到的結果都是一個我們在使用模型前想要去得到的預測結果。
什么時候不該使用機器學習?
首先,上面說的8條一旦無法滿足,那么就要警惕是否要進行機器機器學習了。除此之外還有哪些?我以快速回答的方式進行闡述:
1. 不相信機器學習(沒有信仰)
如果你的客戶老板,領導,機器學習使用方是不信任機器學習的,就算機器學習能夠發揮再大的價值,也是很難進行推動落地的。
2. 解決簡單的問題
如果需要的解決的問題非常簡單,通過一些規則其實也能夠達到預測的效果,那么不要用,可以使用性價比更高的“規則引擎”來替代機器學習。
3. 一個微不足道的預測錯誤會引來很大的災難
機器學習模型雖然整體上的質量在部署使用前會經過保證,但是這不代表它能夠對于每一個個體產生相同的預測效果,所以在一些單獨個體的預測上可能會存在著較大的錯誤。如果這個錯誤會導致巨大的損失和災難性的后果,那么不要用。
4. 性價比不高
機器學習的建立以及后期的運營都是需要成本的,如果這件事情的投入無法獲得相應的投入,那么就慎用機器學習模型。
5. 業務流程中人工經驗過多
我提到機器學習模型策略建立的本質,是通過預測量化的人工經驗,以取代經驗判斷變成模型判斷。但是如果人工的一個判斷需要非常多維度的經驗才能夠去做出,那么這就不是一個很好的應用的場景。因為就算我們通過機器學習模型給出了一個經驗判斷的預測值,那么最終的決定還是會經過其他多個人工經驗的權衡。
最理想的結果就是,這個預測值給到你,你就可以直接落地一個行為,這是一個1對1的結果,即1個經驗或1個指標決定1個行為,而不是多對1 。就算機器學習解決了“多”里面的1個或2個經驗的預測,那么還有很多的人工經驗影響最終決定最后的行為策略。所以如果人工經驗過多,機器學習恐怕就算給出了其中一條經驗的預測結果,也是無法直接落地讓業務使用并做出相應判斷的。
寫在最后
以上是通過調研與個人總結后對于使用機器學習條件的小小歸納。在開始考慮使用機器學習之前請先從這些方面去仔細思考機器學習的必要性。如果在不合適的場景下使用了機器學習,那么后面要面臨的風險還是非常多的。