車聯網平臺百萬級消息吞吐架構設計
前言
在之前的文章中,我們提到車聯網 TSP 平臺擁有很多不同業務的主題,并介紹了 ??如何根據不同業務場景進行 MQTT 主題設計??。車輛會持續不斷產生海量的消息,每一條通過車聯網上報的數據都是非常珍貴的,其背后蘊藏著巨大的業務價值。因此我們構建的車輛 TSP 平臺也通常需要擁有千萬級主題和百萬級消息吞吐能力。
傳統的互聯網系統很難支撐百萬量級的消息吞吐。在本文中,我們將主要介紹如何針對百萬級消息吞吐這一需求進行新一代車聯網平臺架構設計。

車聯網場景消息吞吐設計的關聯因素
車聯網的消息分為上行和下行。上行消息一般是傳感器及車輛發出的告警等消息,把設備的信息發送給云端的消息平臺。下行消息一般有遠程控制指令集消息和消息推送,是由云端平臺給車輛發送相應的指令。
在車聯網消息吞吐設計中,我們需要重點考慮以下因素:
(1) 消息頻率
車在行駛過程中,GPS、車載傳感器等一直不停地在收集消息,為了收到實時的反饋信息,其上報接收的消息也是非常頻繁的。上報頻率一般在 100ms-30s 不等,所以當車輛數量達到百萬量級時,平臺就需要支持每秒百萬級的消息吞吐。
(2) 消息包大小
消息是通過各種傳感器來采集自身環境和狀態信息(車聯網場景常見的有新能源國標數據和企標數據)。整個消息包大小一般在 500B 到幾十 KB 不等。當大量消息包同時上報時,需要車聯網平臺擁有更強的接收、發送大消息包的能力。
(3) 消息延時
車輛在行駛過程中,消息數據只能通過無線網絡來進行傳輸。在大部分車聯網場景下,對車輛的時延要求是 ms 級別。平臺在滿足百萬級吞吐條件下,還需要保持低延時的消息傳輸。
(4) Topic 數量和層級
在考慮百萬級消息吞吐場景時,還需要針對消息 Topic 數量和 Topic 樹層級進行規范設計。
(5) Payload 編解碼
當消息包比較大的時候,需要重點考慮消息體的封裝。單純的 JSON 封裝在消息解析時不夠高效,可以考慮采用 Avro、Protobuf 等編碼格式進行 Payload 格式化封裝。
對于百萬級消息吞吐場景,基于 MQTT 客戶端共享訂閱消息或通過規則引擎實時寫入關系型數據庫的傳統架構顯然無法滿足。目前主流的架構選型有兩種:一種是消息接入產品/服務+消息隊列(Kafka、Pulsar、RabbitMQ、RocketMQ 等),另外一種是消息接入產品/服務+時序數據庫(InfluxDB、TDengine、Lindorm等)來實現。
接下來我們將基于上述的關聯因素和客戶案例的最佳實踐,以云原生分布式物聯網消息服務器 EMQX 作為消息接入層,分別介紹這兩種架構的實現方式。
EMQX+Kafka 構建百萬級吞吐車聯網平臺
架構設計
Kafka 作為主流消息隊列之一,具有持久化數據存儲能力,可進行持久化操作,同時可通過將數據持久化到硬盤以及 replication 防止數據丟失。后端 TSP 平臺或者大數據平臺可以批量訂閱想要的消息。
由于 Kafka 擁有訂閱發布的能力,既可以從南向接收,把上報消息緩存起來;又可以通過北向的連接,把需要發送的指令通過接口傳輸給前端,用作指令下發。
我們以 Kafka 為例,構建 EMQX+Kafka 百萬級吞吐車聯網平臺:
- 前端車機的連接與消息可通過公有云商提供的負載均衡產品用作域名轉發,如果采用了 TLS/DTLS 的安全認證,可在云上建立四臺 HAProxy/Nginx 服務器作為證書卸載和負載均衡使用。
- 采用 10 臺 EMQX 組成一個大集群,把一百萬的消息吞吐平均分到每個節點十萬消息吞吐,同時滿足高可用場景需求。
- 如有離線離線/消息緩存需求,可選用 Redis 作為存儲數據庫。
- Kafka 作為總體消息隊列,EMQX 把全量消息通過規則引擎,轉發給后端 Kafka 集群中。
- 后端 TSP 平臺/OTA 等應用通過訂閱 Kafka 的主題接收相應的消息,業務平臺的控制指令和推送消息可通過 Kafka/API 的方式下發到 EMQX。
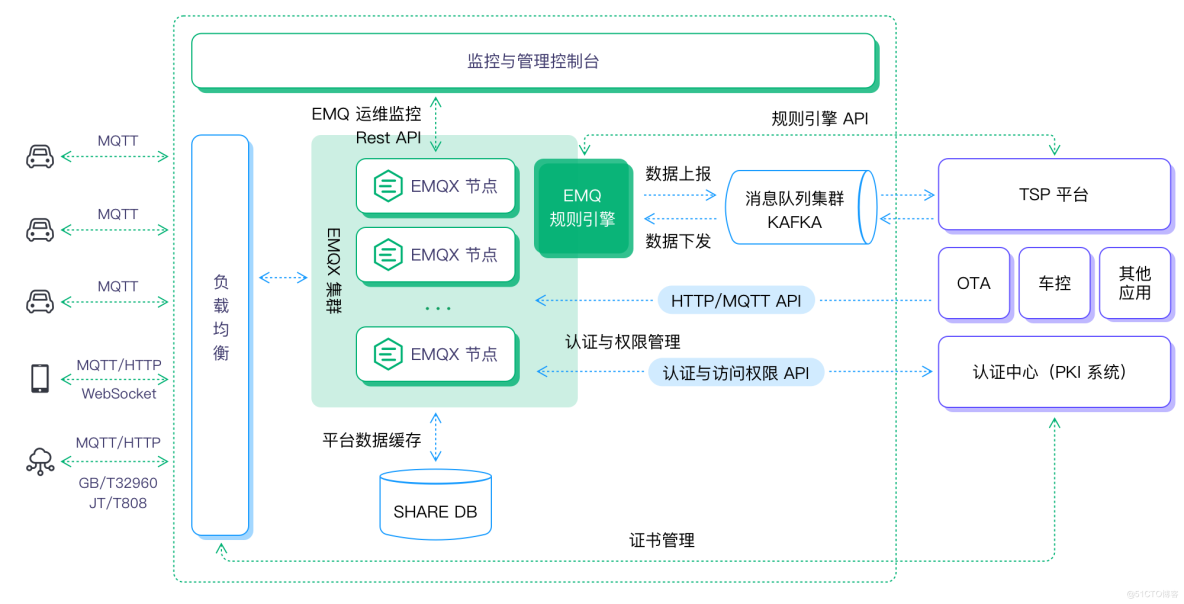
總體架構圖
在這一方案架構中,EMQX 作為消息中間件具有如下優勢,可滿足該場景下的需求:
- 支持千萬級車輛連接、百萬級消息吞吐能力。
- 分布式集群架構,穩定可靠,支持動態水平擴展。
- 強大的規則引擎和數據橋接、持久化能力,支持百萬級消息吞吐處理。
- 擁有豐富 API 與認證等系統能順利對接。
百萬吞吐場景驗證
為了驗證上述架構的吞吐能力,在條件允許的情況下,我們可以通過以下配置搭建百萬級消息吞吐測試場景。壓測工具可以選用 Benchmark Tools、JMeter 或 XMeter 測試平臺。共模擬 100 萬設備,每個設備分別都有自己的主題,每個設備每秒發送一次消息,持續壓測 12 小時。
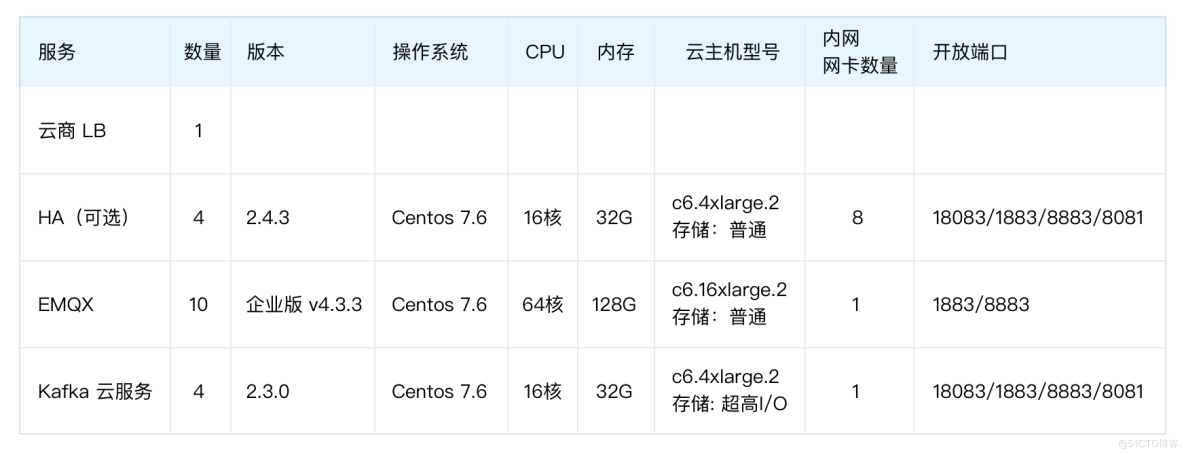
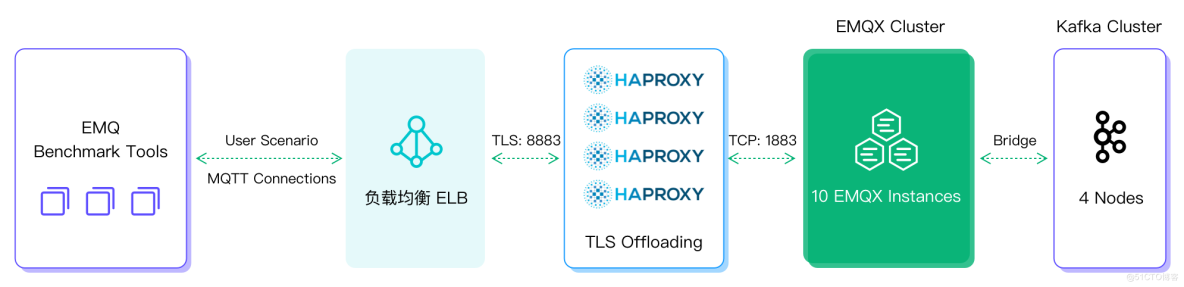
壓測架構圖如下:
性能測試部分結果呈現:

(1) EMQX 集群 Dashboard 統計
EMQX 規則引擎中可以看到每個節點速度為 10 萬/秒的處理速度,10 個節點總共 100 萬/秒的速度進行。
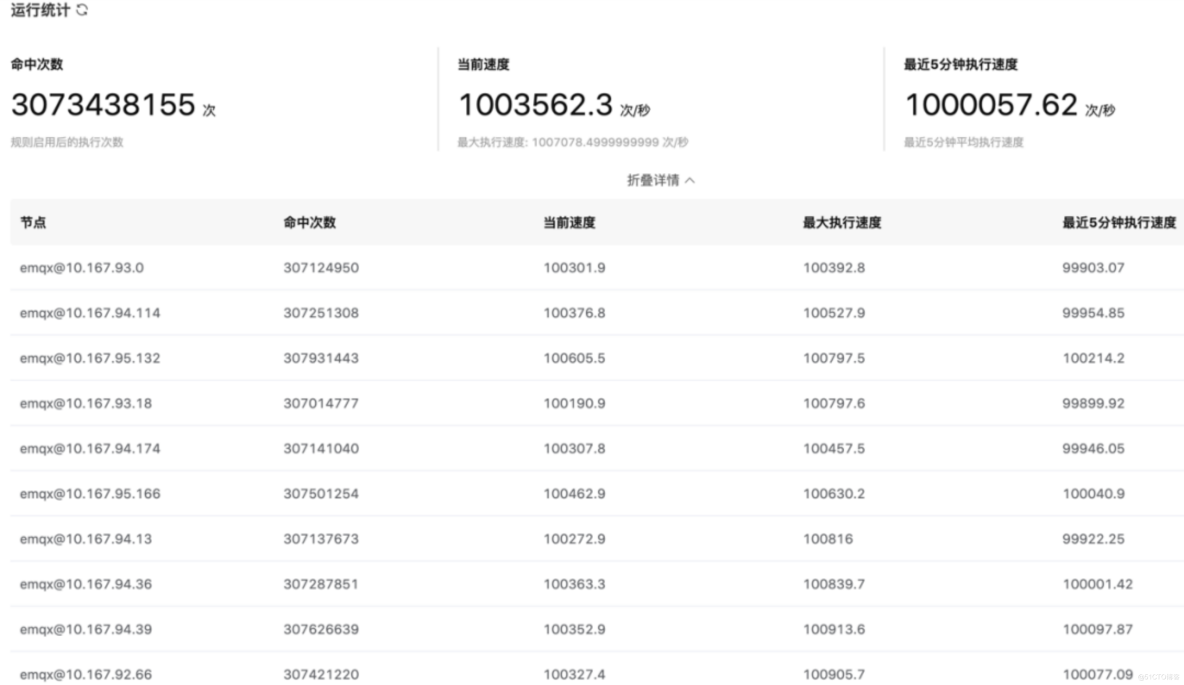
(2) EMQX 規則引擎統計
在 Kafka 中可以看到每秒 100 萬的寫入速度,并且一直持續存儲。

Kafka 管理界面統計
EMQX+InfluxDB 構建百萬級吞吐車聯網平臺
架構設計
采用 EMQX+ 時序數據庫的架構,同樣可以構建百萬級消息吞吐平臺。在本文我們以 InfluxDB 時序數據庫為例。
InfluxDB 是一個高性能的時序數據庫,被廣泛應用于存儲系統的監控數據、IoT 行業的實時數據等場景。它從時間維度去記錄消息,具備很強寫入和存儲性能,適用于大數據和數據分析。分析完的數據可以提供給后臺應用系統進行數據支撐。
此架構中通過 EMQX 規則引擎進行消息轉發,InfluxDB 進行消息存儲,對接后端大數據和分析平臺,可以更方便地服務于時序分析。
- 前端設備的消息通過云上云廠商的負載均衡產品用作域名轉發和負載均衡。
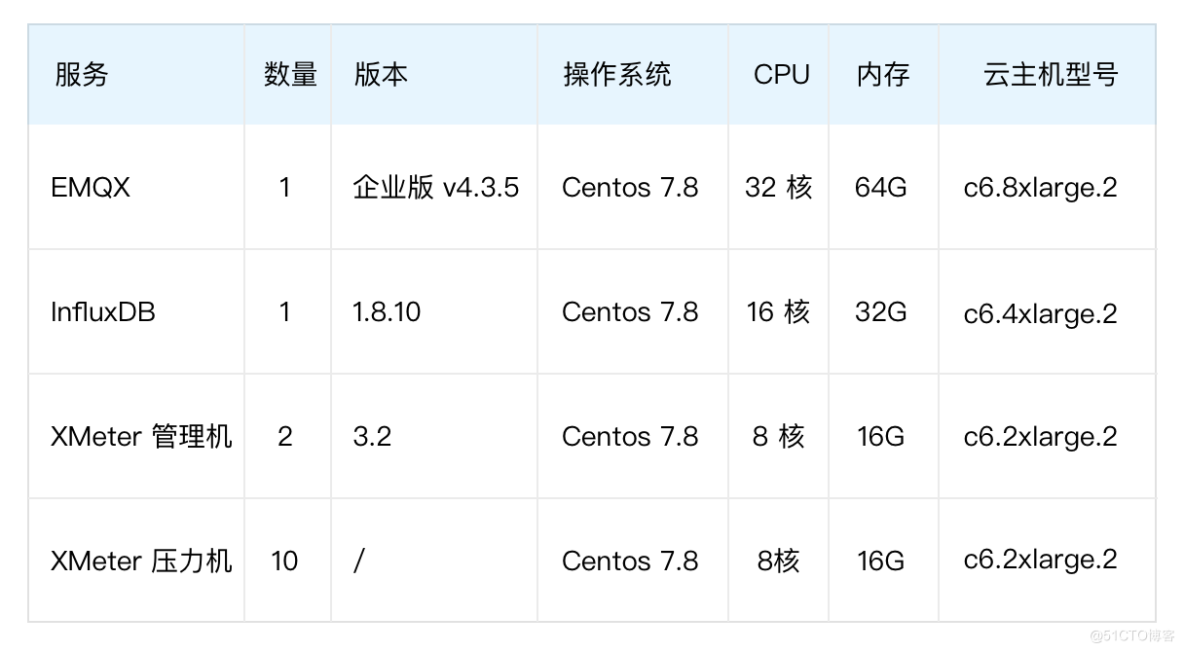
- 本次采用 1 臺 EMQX 作為測試,后續需要時可以采用多節點的方式,組成相應的集群方案(測試 100 萬可以部署 10 臺 EMQX 集群)。
- 如有離線離線/消息緩存需求,可選用 Redis 作為存儲數據庫。
- EMQX 把全量消息通過規則引擎轉發給后端InfluxDB進行數據持久化存儲。
- 后端大數據平臺通過 InfluxDB 接收相應的消息,對其進行大數據分析,分析后再通過 API 的方式把想要的信息傳輸到 EMQX。
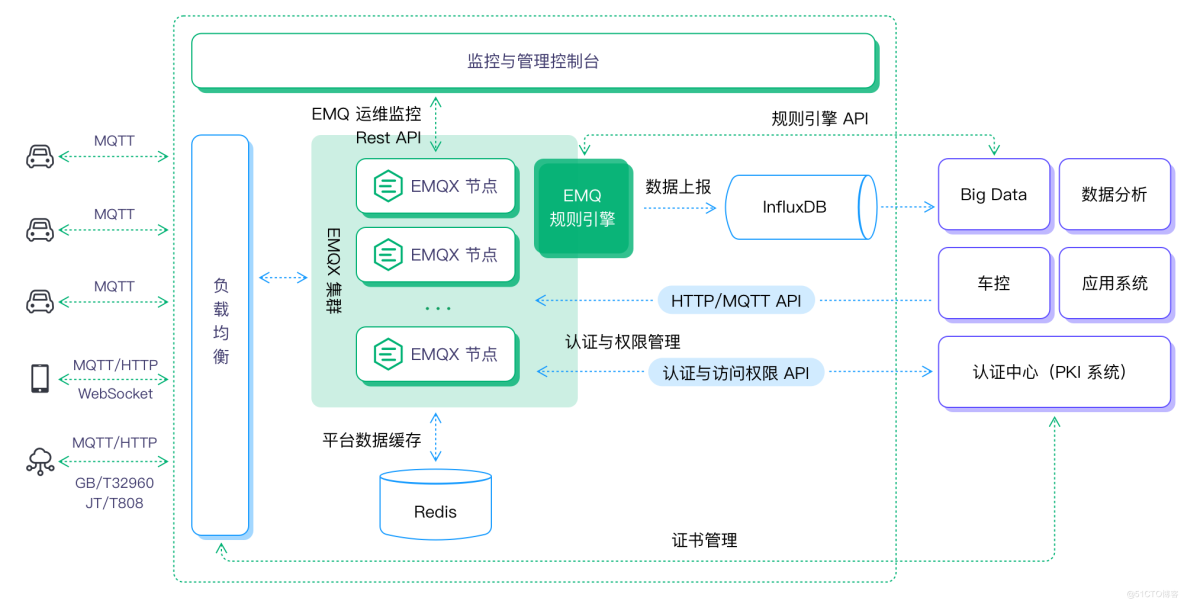
總體架構圖
場景驗證
如測試架構圖中所示,XMeter 壓力機模擬 10 萬 MQTT 客戶端向 EMQX 發起連接,新增連接速率為每秒 10000,客戶端心跳間隔(Keep Alive)300 秒。所有連接成功后每個客戶端每秒發送一條 QoS 為 1、Payload 為 200B 的消息,所有消息通過 HTTP InfluxDB 規則引擎橋過濾篩選并持久化發至 InfluxDB 數據庫。
測試結果呈現如下:

EMQX Dashboard 統計:
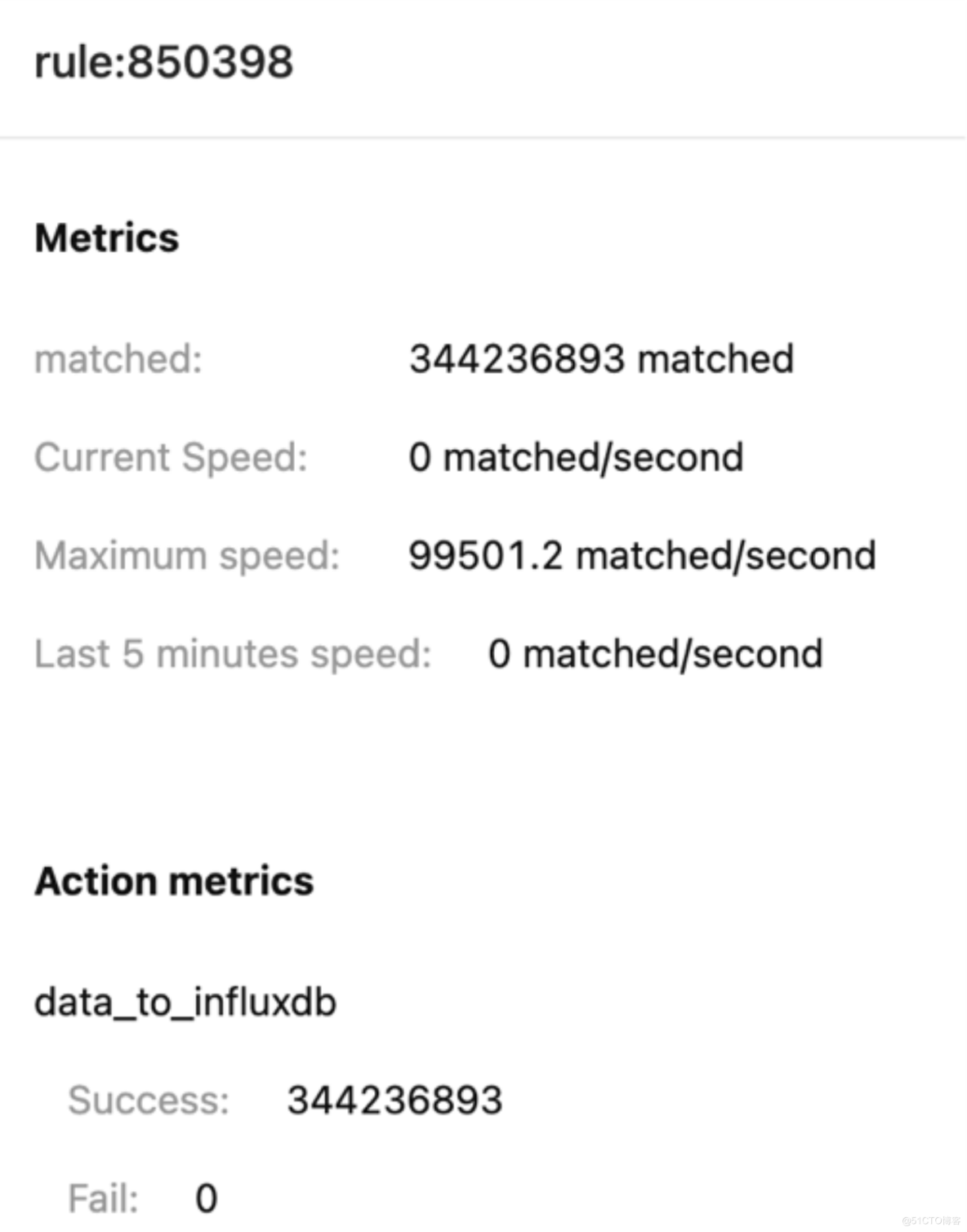
EMQX 規則引擎統計:
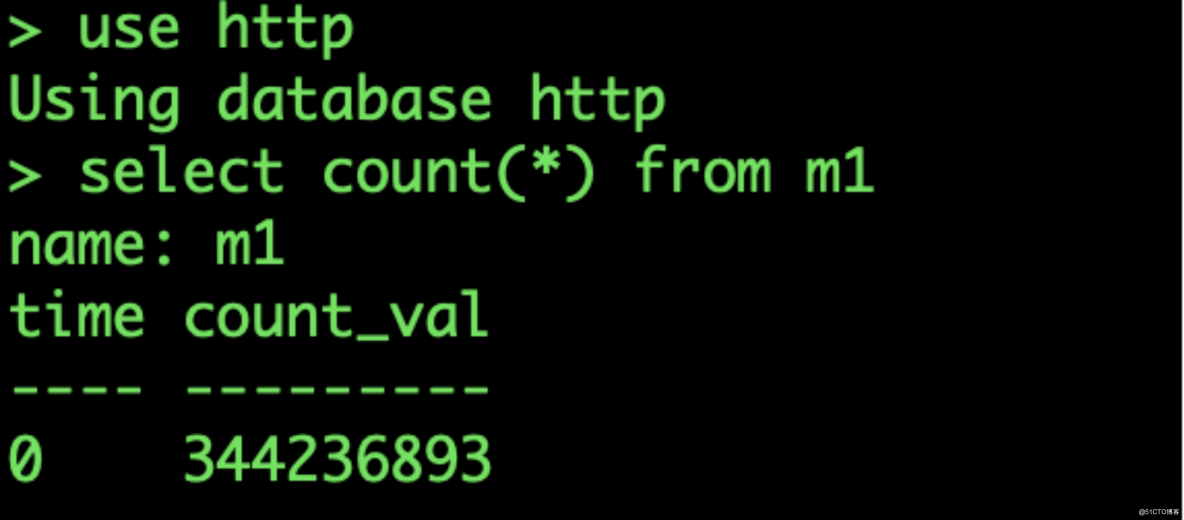
InfluxDB 數據庫收到數據:
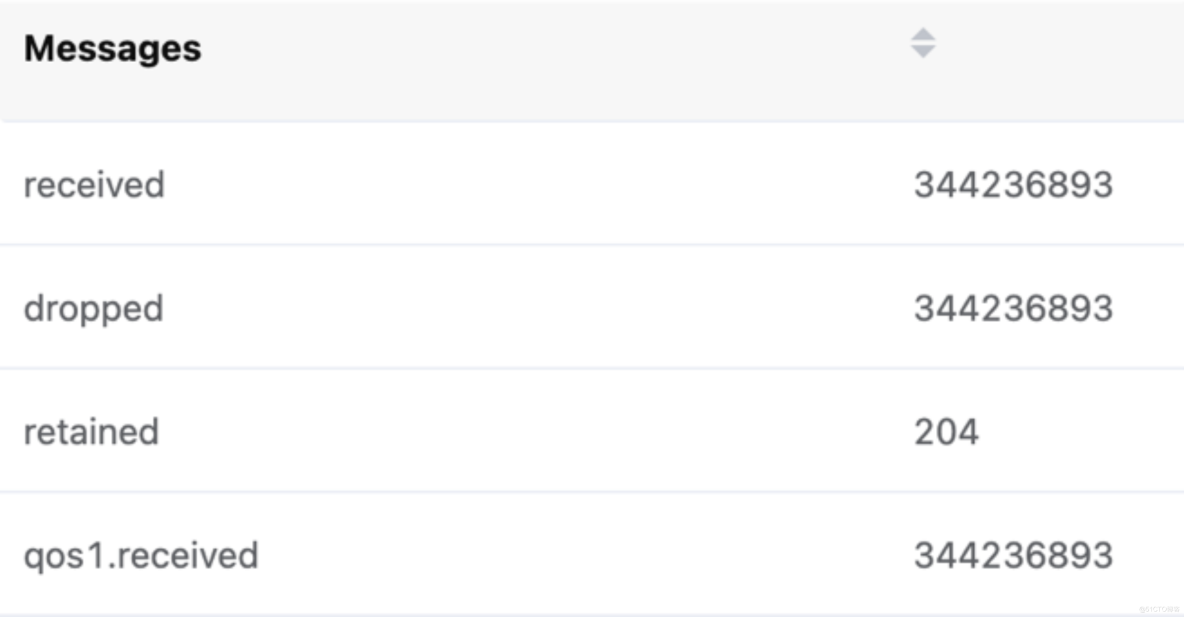
EMQX Dashboard 消息數統計
單臺 EMQX 服務器實現了單臺服務器 10 萬 TPS 的消息吞吐持久化到 InfluxDB 能力。參考 EMQX+Kafka 架構的測試場景,將 EMQX 的集群節點擴展到 10 臺,就可以支持 100 萬的 TPS 消息吞吐能力。
結語
通過本文,我們介紹了車聯網場景消息吞吐設計需要考慮的因素,同時提供了兩種較為主流的百萬級吞吐平臺架構設計方案。面對車聯網場景下日益增加的數據量,希望本文能夠為相關團隊和開發者在車聯網平臺設計與開發過程中提供參考。?