













超優的純文本模型?GPT-4蓄勢待發

2020 年 5 月,在 GPT-2 發布一年后,GPT-3 正式發布,而 GPT-2 也是在原始 GPT 論文發表一年后發布的。按照這種趨勢, GPT-4 早在一年前就該發布了,但至今尚未面世。
OpenAI 的首席執行官 Sam Altman 幾個月前表示即將推出 GPT-4 ,預計將在 2022 年 7 月至 8 月發布。
GPT-3 的強大性能讓人們對 GPT-4 的期望頗高。然而關于 GPT-4 的公開信息甚少,Altman 在去年的一次 Q&A 中就 OpenAI 對 GPT-4 的想法給出了一些提示。他明確表示,GPT-4 不會有 100T 參數。
正因為 GPT-4 的公開信息很少,人們對其做出諸多預測。近期,一位分析師 Alberto Romero 基于 OpenAI 和 Sam Altman 透露的信息,以及當前趨勢和語言 AI 的最新技術,對 GPT-4 作出了一番新的預測,以下是他的預測原文。
1 模型大小:GPT-4 不會非常大
GPT-4 不會成為最大的語言模型,Altman 曾說它不會比 GPT-3 大多少。它的大小可能在 GPT-3 和 Gopher 之間 (175B -280B)。
這個推測有充分的理由。
NVIDIA 和微軟去年聯合創建的威震天 - 圖靈 NLG( MT-NLG)號稱是擁有 530B 參數的最大密集神經網絡,參數量已經是 GPT-3 的 3 倍,而最近谷歌的 PaLM 已有 540B 參數。但值得注意的是,在 MT-NLG 之后出現的一些較小的模型反而達到了更高的性能水平。
這意味著:更大不一定更好。
業內很多公司已經意識到模型大小不是性能的決定因素,擴大模型也不是提升性能的最好方法。2020 年,OpenAI 的 Jared Kaplan 及其同事得出結論:當增加的計算預算主要分配到增加參數的數量上時,性能的提高是最顯著的,并且遵循冪律關系。
然而,以超大規模的 MT-NLG 為例,它在性能方面并不是最好的。事實上,甚至在任何單一類別的基準測試中都不是最好的。較小的模型,如 Gopher (280B)或 Chinchilla (70B) 在一些任務上比 MT-NLG 好得多。
顯然,模型大小并不是實現更好的語言理解性能的唯一因素。
業內多家公司開始放棄「越大越好」的教條。擁有更多參數也會帶來一些副作用,例如計算成本過高、性能進入瓶頸期。當能夠從較小的模型中獲得相似或更好的結果時,這些公司就會在構建巨大模型之前三思而后行。
Altman 表示,他們不再專注于讓模型變得更大,而是讓更小的模型發揮最大的作用。OpenAI 是擴展假設(scaling hypothesis)的早期倡導者,但現在已經意識到其他未探索的路徑也能改進模型。
因此,GPT-4 不會比 GPT-3 大很多。OpenAI 將把重點轉移到其他方面,例如數據、算法、參數化和價值對齊(alignment)等,這可能會帶來更顯著的改進。關于 100T 參數模型的功能,我們只能等待了。
2 優化:GPT追求“最優”
語言模型在優化方面存在一個關鍵限制,即訓練成本非常高。以至于研發團隊不得不在準確性和成本之間進行權衡。這通常會導致模型明顯欠優化。
GPT-3 只訓練了一次,當在一些用例中出現錯誤時就要重新進行訓練。OpenAI 決定,GPT-4 不會采取這種方式,因為成本太高,研究人員無法找到模型的最佳超參數集(例如學習率、批大小、序列長度等)。
高訓練成本的另一個后果是,對模型行為的分析要受到限制。Kaplan 的團隊得出模型大小是提高性能最相關的變量時,他們并沒有考慮訓練 token 的數量,這需要大量的計算資源。
不得不承認,一些大型公司依照 Kaplan 團隊的結論,在擴大模型上「浪費」了數百萬美元。現在,以 DeepMind 和 OpenAI 為首的公司正在探索其他方法。他們試圖找到最優的模型,而不僅僅是更大的模型。
優化參數
上個月,微軟和 OpenAI 證實用優化后的超參數進行訓練,GPT-3 能夠獲得較大的改進。他們發現,6.7B 版本的 GPT-3 性能大幅提升,可與最初的 13B GPT-3 相媲美。超參數調優帶來的性能提升,相當于參數量增加了一倍。
他們利用一種稱為μP 的新型參數化方式,其中小模型的最佳超參數同樣適用于同類型的大模型。因此,μP 能夠以一小部分訓練成本優化任意大小的模型,幾乎毫無成本地將超參數遷移到更大的模型中。
優化計算模型
幾周前,DeepMind 重新審視了 Kaplan 等人的發現,并意識到:與人們認為的相反,訓練 token 的數量對性能的影響與模型大小的影響一樣大。DeepMind 得出結論:計算預算應該平均分配給擴展參數和數據。他們用大型語言模型 4 倍的數據量(1.4T token)訓練 Chinchilla(70B)證明了這個假設。
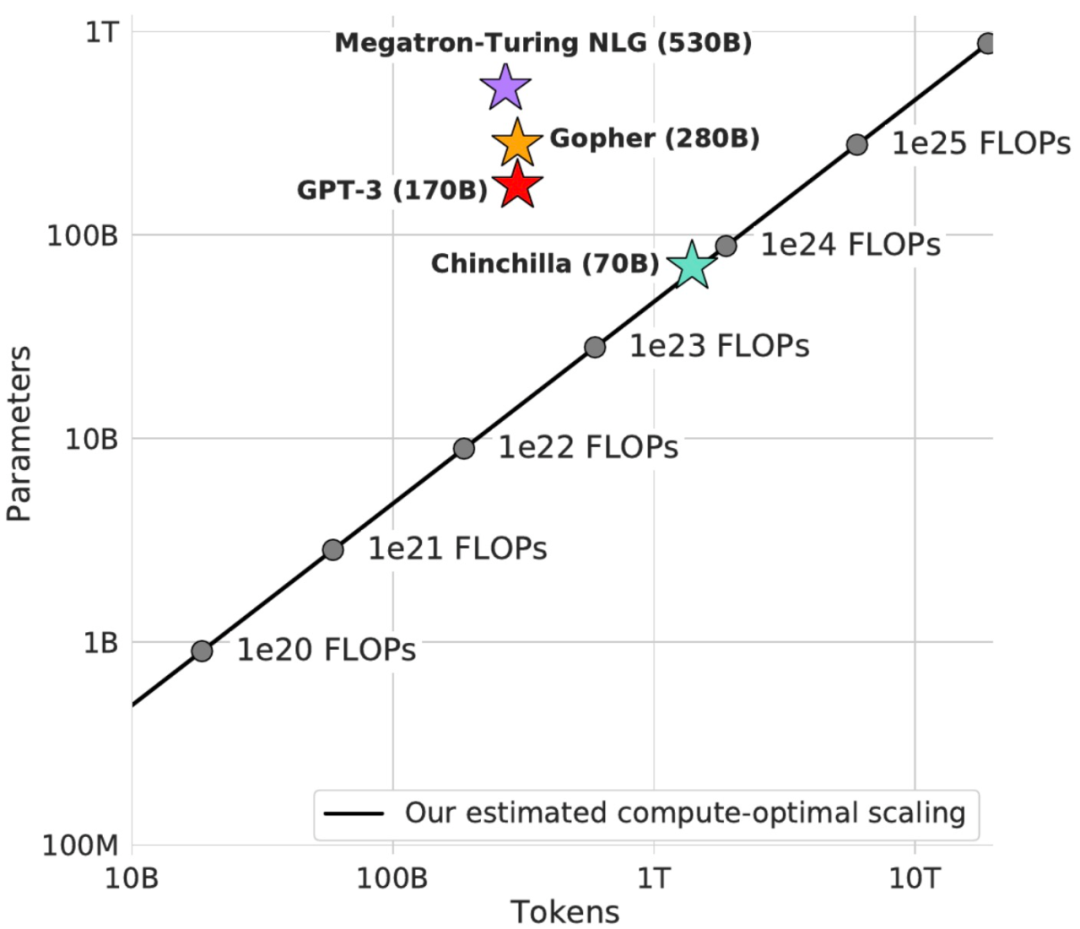
圖源:DeepMind
結果很明確,Chinchilla 在許多語言基準測試中「顯著」優于 Gopher、GPT-3、MT-NLG 等語言模型,這表明當前的大模型訓練不足且規模過大。
考慮到 GPT-4 將比 GPT-3 略大,根據 DeepMind 的發現,它達到計算最優所需的訓練 token 數量將約為 5 萬億,比當前數據集高出一個數量級。為了最小化訓練損失,訓練 GPT-4 所需的 FLOP 將是 GPT-3 的約 10-20 倍(參照 Gopher 的計算量)。
Altman 曾在 Q&A 中表示 GPT-4 的計算量將比 GPT-3 更大,他可能指的就是這一點。
可以肯定的是,OpenAI 將致力于優化模型大小以外的其他變量。找到最佳的超參數集以及最佳的計算模型大小和參數數量,這可能會讓模型在所有基準測試中獲得令人難以置信的提升。
3 多模態:GPT-4 將是純文本模型
人類的大腦是多感官的,因為我們生活在一個多模態的世界中。一次只以一種模態感知世界,極大地限制了人工智能理解世界的能力。因此,人們認為深度學習的未來是多模態模型。
然而,良好的多模態模型比良好的純語言或純視覺模型更難構建。將視覺和文本信息組合成單一的表征是一項非常艱巨的任務。我們對大腦如何做到這一點的認知還非常有限,難以在神經網絡中實現它。
大概也是出于此原因,Altman 在 Q&A 中也表示,GPT-4 不會是多模態的,而是純文本模型。我猜測在轉向下一代多模態 AI 之前,他們正試圖通過調整模型和數據集大小等因素達到語言模型的極限。
4 稀疏性:GPT-4 將是一個密集模型
近來,稀疏模型利用條件計算,使用模型的不同部分來處理不同類型的輸入,取得了巨大成功。這些模型可以輕松擴展到超過 1T 的參數 mark 上,而不會導致過高的計算成本,從而在模型大小和計算預算之間構建出正交關系。然而,這種 MoE 方法的優勢在非常大的模型上會有所減弱。
鑒于 OpenAI 一直專注于密集語言模型,我們有理由預期 GPT-4 也將是一個密集模型。
不過,人類的大腦嚴重依賴于稀疏處理,稀疏性與多模態類似,很可能會主導未來幾代神經網絡。
5 GPT-4 將比 GPT-3 更加對齊
OpenAI 為解決 AI 價值觀對齊(alignment)的問題付出了諸多努力:如何讓語言模型遵循我們的意圖并遵守我們的價值觀。這不僅需要數學上讓 AI 實現更準確的理解,而且需要在哲學方面考量不同人類群體之間的價值觀。OpenAI 已嘗試在 InstructGPT 上接受人工反饋訓練以學會遵循指令。
InstructGPT 的主要突破在于,無論其在語言基準上的結果如何,它都被人類評估者一致認為是一比 GPT-3 更好的模型。這表明,使用基準測試作為評估 AI 能力的唯一指標是不合適的。人類如何看待模型同樣重要,甚至更重要。
鑒于 Altman 和 OpenAI 對有益 AGI 的承諾,我相信GPT-4將實現并構建他們從InstructGPT中發現的成果。
他們將改進對齊模型的方式,因為 GPT-3 只采用了英文語料和注釋。真正的對齊應該包含來自不同性別、種族、國籍、宗教等方面的信息特征。這是一個巨大的挑戰,朝著這個目標邁進意義重大。
6 總結
綜上,我關于 GPT-4 的預測大致包括以下幾個方面:
模型大小:GPT-4 會比 GPT-3 大,但不會很大。模型大小不會是其顯著特征;
優化:GPT-4 將使用比 GPT-3 更多的計算,它將在參數化(最優超參數)和擴展定律(訓練 token 的數量與模型大小一樣重要)方面做出新的改進;
多模態:GPT-4 將是純文本模型,OpenAI 正試圖將語言模型發揮到極致,然后再轉變成像 DALL·E 這樣的多模態模型;
稀疏性:GPT-4 遵循 GPT-2 和 GPT-3 的趨勢,它將是一個密集模型,但稀疏性未來將占據主導地位;
對齊:GPT-4 將比 GPT-3 更符合人們的價值要求,它將應用從 InstructGPT 中學到的經驗。
Alberto Romero 根據 Altman 和 OpenAI 給出的信息作出了有理有據的推測,期待這些預測在幾個月后在即將面世的 GPT-4 中得到印證。?












