五分鐘搞懂分布式流控算法
流控是任何一個復雜系統都必須考慮的問題,本文介紹并比較了不同的流控算法,從而幫助我們可以基于系統需求和架構選擇合適的方案。原文:Distributed Rate-Limiting Algorithms [1]
當我們設計分布式流控系統(distributed rate-limiting system)時,需要用到哪些工具和算法?

Joshua Hoehne @Unsplash
Criteo是全球最大的廣告技術公司之一,隨著廣告市場的不斷發展,Criteo在過去幾年里一直致力于改進API,幫助客戶更好的通過可編程接口訪問需要的服務。
隨著越來越多的客戶使用新的API,很明顯,需要實現某種流量控制,以確保所有客戶端都能平等訪問資源,并保護API免受(惡意或錯誤的)頻繁調用。
流控似乎很簡單: 只允許給定的客戶端每分鐘執行X個調用。在單個服務器實例上實現流控非常容易,可以很容易找到相關的庫來實現。但問題是我們的API托管在6個數據中心(歐洲、北美和亞洲),每個數據中心都有多個實例,這意味著我們需要某種分布式流控系統。
流控不僅與調用次數有關,還需要和客戶端同步當前被限制的狀態(例如,使用專用的報頭和狀態碼)。但是本文將主要關注用于流控的算法和系統。
利用負載均衡
在嘗試開發自己的系統之前,更重要的是查看現有的基礎設施是否能夠提供想要的特性。
那么,部署在數據中心所有實例之前,并且已經在負責檢查、路由流量的是什么?負載均衡器。大多數負載均衡器都提供了流控特性或某種可用于實現流控的抽象。例如,HAProxy有現成的可用于設置流控的stick tables [2] ,可以在實例之間同步狀態,并且工作得很好。
不幸的是,負載均衡不支持我們需要的某些特性(動態限制、令牌自省token introspection、……),因此我們需要自己實現這些特定的需求。
初級方案
會話粘連(Sticky sessions)
說到負載均衡,如果給定客戶端的負載并不均衡,并且總是與單個實例交互 ,那么就不需要分布式流控系統。大多數客戶端訪問距離最近的數據中心(通過geo-DNS),如果在負載均衡器上啟用“stickiness”,客戶端應該總是訪問相同的實例,這種情況下我們可以使用簡單的“本地”速率限制。
這在理論上可行,但在實踐中行不通。Criteo系統面臨的負載不是恒定的,例如,黑色星期五/Cyber Week是一年中最重要的時段。在此期間,團隊隨時處于戒備狀態,準備擴大基礎設施,以應對客戶不斷增長的需求。但是會話粘連和可伸縮性不能很好的配合(如果所有客戶端都粘連在舊實例上,那么創建新實例又有什么用呢?)
使用更智能的會話粘連(在擴展時重新分配令牌)會有所幫助,但這意味著每次擴展時,客戶端都可能切換到另一個實例上,而且并不知道客戶端在前一個實例上執行了多少調用。本質上說,這將使我們的流控在每次伸縮時不一致,客戶端可能在每次系統面臨壓力時會進行更多調用。
Chatty服務器
如果客戶端可以訪問任何實例,意味著“調用計數”必須在實例之間共享。一種方案是讓每個實例調用所有其他實例,請求給定客戶端的當前計數并相加。另一種方案反過來,每個服務器向其他服務器廣播“計數更新”。
這會造成兩個主要問題:
- 實例越多,需要進行的調用就越多。
- 每個實例都需要知道其他實例的地址,并且每次服務擴縮容時都必須更新地址。
雖然可以實現這個解決方案(本質上是一個點對點環,許多系統已經實現了),但成本較高。
Kafka
如果不想讓每個實例都和其他實例通信,可以利用Kafka同步所有實例中的計數器。
例如,當某個實例被調用時,就將一個事件推到對應的topic。這些事件會被滑動窗口聚合(Kafka Stream在這方面做得很好),每個客戶端最后一分鐘的最新計數會被發布到另一個topic上。然后,每個實例通過此topic獲得所有客戶端的共享計數。
問題在于Kafka本質上是異步的,雖然通常延遲很小,但當API負載增加時,也會增加延遲。如果實例使用了過時的計數器,那么可能會漏過那些本應被阻止的調用。
這些解決方案都有一個共同點: 當一切正常時,可以很好的工作,但當負載過重時,就會退化。我們的大部分系統都是這樣設計的,通常情況下沒有問題,但流控并不是典型組件,其目標就是保護系統的其他部分免受這種過重負載的影響。
流控系統的目標是在系統負載較重時工作良好,其構建目標是為最差的1%而不是好的99%的情況服務。
分布式算法
我們需要一個中心化的同步存儲系統,以及為每個客戶端計算當前速率的算法。內存緩存(如Memcached或Redis)是理想的系統,但并不是所有的流控算法都可以在緩存系統中實現。下面我們看看有什么樣的算法。
簡化起見,我們考慮嘗試實現“每分鐘100次調用”的流控。
看看有哪些工具可用。

Barn Images @Unsplash
基于事件日志的滑動窗口(Sliding window via event log)
如果想知道某個客戶端在過去一分鐘內進行了多少次調用,可以在緩存中為每個客戶端存儲一個時間戳列表。每次調用時,相應的時間戳都會添加到列表中。然后循環遍歷列表中的每一項,丟棄超過一分鐘的舊項,并計算新項。
:+1:優點:
- 非常精確
- 簡單
:-1:缺點:
- 需要強大的事務支持(處理同一客戶端的兩個實例需要更新相同的列表)。
- 根據不同的調用限制和次數,存儲對象(列表)的大小可能相當大。
- 性能不穩定(更多的調用意味著需要處理更多的時間戳)。
固定窗口(Fixed window)
大多數分布式緩存系統都有特定的、高性能的“計數器”抽象(一個可以自動增加的整數值,附加在一個字符串鍵上)。
以“ {clientId} ”為key為每個客戶端維護一個計數器非常容易,但只會計算自計數器創建以來客戶端調用的次數,而不是最后一分鐘的次數。以“ {clientId}_{yyyyMMddHHmm} ”為key可以每分鐘都為客戶端維護一個計數器(換句話說: 以1分鐘為固定窗口),查找與當前時間相對應的計數器可以告訴我們這一分鐘客戶端執行的調用數量,如果這個值超過上限,就可以阻止調用。
請注意,這與“最近一分鐘”不是一回事。如果在上午07:10:23有一次調用,固定窗口計數器會顯示在上午07:10:00到07:10:23之間調用的數量。但我們真正想要的是早上07:09:23到07:10:23之間的調用數量。
在某種程度上,固定窗口算法每過一分鐘都會“忘記”之前有多少次呼叫,因此客戶端理論上可以在07:09:59執行100次調用,然后在07:10:00執行100次額外的調用。
:+1:優點:
- 非常快(單個原子增量+讀取操作)
- 只需要非常基本的事務支持(原子計數器)
- 性能穩定
- 簡單
:-1:缺點:
- 不準確(最多會允許2倍調用)
令牌桶(Token bucket)
回到1994年,父母把你送到游戲廳和朋友們一起玩《超級街霸2》。他們給你一個裝了5美元硬幣的小桶,然后去了街對面的酒吧,并且每個小時都會過來往桶里扔5美元硬幣。因此你基本上被限制每小時玩5美元(希望你在《街頭霸王》中表現出色)。
這就是“令牌桶”算法背后的主要思想: 與簡單計數器不同,“桶”存儲在每個客戶端緩存中。桶是由兩個屬性組成的對象:
- 剩余“令牌”的數量(或剩余可以進行的調用的數量)
- 最后一次調用的時間戳。
當API被調用時,檢索桶,根據當前調用和最后一次調用之間的時間間隔,向桶中添加新的令牌,如果有多余令牌,遞減并允許調用。
所以,和“街頭霸王”的例子相反,沒有“父母”幫我們每分鐘重新裝滿桶。桶在與令牌消耗相同的操作中被有效的重新填充(令牌的數量對應于上次調用之后的時間間隔)。如果最后一次調用是在半分鐘之前,那么每分鐘100次調用的限制意味著將向桶中添加50個令牌。如果桶太“舊”(最后一次調用超過1分鐘),令牌計數將重置為100。
事實上,可以在初始化的時候填充超過100個令牌(但補充速度為100令牌/分鐘): 這類似于“burst”功能,允許客戶端在一小段時間內超過流控的限制,但不能長期維持。
注意:正確計算要添加的令牌數很重要,否則有可能錯誤的填充桶。
該算法提供了完美的準確性,同時提供了穩定的性能,主要問題是需要事務(不希望兩個實例同時更新緩存對象)。
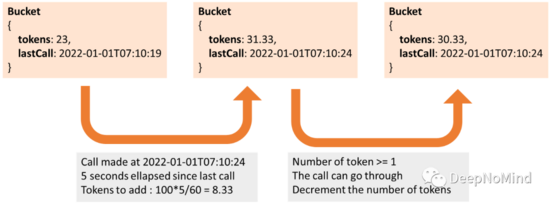
100次調用/分鐘的令牌桶的分步示例
:+1:優點:
- 非常精確
- 快速
- 性能穩定
- 優化初始令牌數量可以允許客戶端“burst”調用
:-1:缺點:
- 更復雜
- 需要強大的事務支持
漏桶(Leaky bucket):該算法的另一個版本。在這個版本中,調用堆積在bucket中,并以恒定的速率(匹配速率限制)處理。如果桶溢出,則拒絕調用。這實現起來比較復雜,但可以平滑服務負載(這可能是您想要的,也可能不是)。
:trophy:最好的算法?
比較這三種算法,令牌桶似乎在性能和準確性方面提供了最好的折衷。但只有當系統提供良好的事務支持時,才有可能實現。如果有Redis集群,這是完美方案(甚至可以實現基于Lua的算法,直接運行在Redis集群上,以提高性能),但Memcached只支持原子計數器,而不是事務。
可以基于Memcached實現令牌桶的樂觀并發(optimistic concurrent)版本 [3] ,但這更加復雜,而且樂觀并發的性能在負載較重的情況下會下降。
用固定窗口近似模擬滑動窗口
如果沒有強大的事務支持,是否注定要使用不準確的固定窗口算法?
算是吧,但還有改進的空間。請記住,固定窗口的主要問題是它每過一分鐘都會“忘記”之前發生的事情,但我們仍然可以訪問相關信息(在前一分鐘的計數器中),所以可以通過計算加權平均值來估計前一分鐘的調用次數。
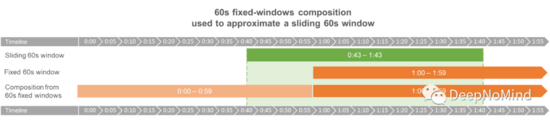
通過60s固定窗口組合近似模擬60s滑動窗口
例如:如果在00:01:43進行了一次調用,遞增得到“00:01”計數器的值。由于這是當前的日歷分鐘,現在包含00:01:00至00:01:43之間的調用數(最后17秒還沒有發生)。
但我們想要的是60s滑動窗口中的調用數,意味著我們錯過了00:00:43到00:01:00這段時間的計數。為此我們可以讀取“00:00”計數器,并以17/60的因子進行調整,從而說明我們只對最后17秒感興趣。
如果負載不變,這一近似是完美的。但如果大多數調用都集中在前一分鐘,那就會獲得一個高估的值。而當大多數調用都集中在前一分鐘結束后,這個數字就會被低估。
比較
為了更準確的了解精度差異,最好是在相同的條件下模擬兩種算法。
下面的圖顯示了“固定計數器”算法在輸入隨機流量時將返回什么。灰色的線是一個“完美”的滑動窗口輸出,該窗口在任何時間點對應于過去60秒內的呼叫次數,這是我們的目標。 橙色虛線表示固定窗口算法對相同流量的“計數”。
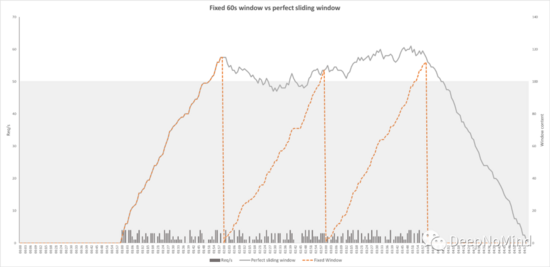
它們在第一分鐘的輸出是相同的,但很快就可以看到固定窗口版本在每分鐘標記處有很大的下降。固定窗口算法很少會超過100個調用的限制,這意味著會允許很多本應被阻止的調用。
下面的圖表示相同的場景,具有相同的流量,但使用了近似的滑動窗口。同樣,灰色線代表“完美”滑動窗口。 橙色虛線表示近似算法。
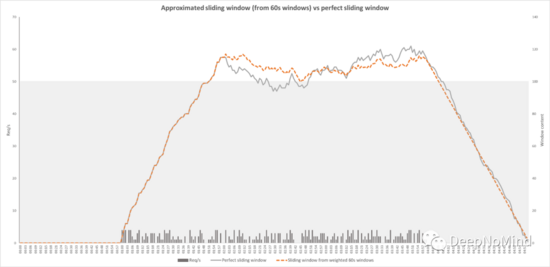
在每分鐘標記附近不再看到下降,可以看到新版本算法與完美算法更接近,它有時略高,有時略低,但總體上是巨大的進步。
收益遞減
但我們能做得更好嗎?
我們的近似算法只使用當前和以前的60秒固定窗口。但是,也可以使用幾個更小的子窗口,一種極端方法是使用60個1s窗口來重建最后一分鐘的流量。顯然這意味著為每個調用讀取60個計數器,這將極大增加性能成本。不過我們可以選擇任意固定窗口時間,從中擬合近似值。窗口越小,需要的計數器就越多,近似值也就越精確。
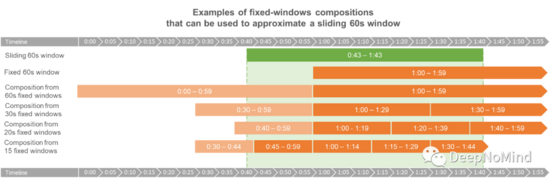
我們看看組合5個15秒窗口會有什么效果:
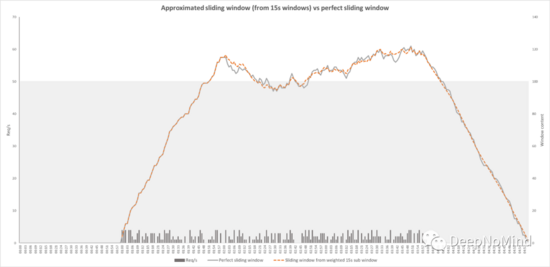
正如預期的那樣,準確率有所提高,但仍然不夠完美。
我們處在一個經典的 更好的準確性=更差的性能 的情況下。沒有絕對的最佳方案,必須平衡對于準確性和性能的要求,找到最適合的解決方案。如果你只關心保護自己的服務不被過度使用,而不需要持續控制,那么甚至最簡單的固定窗口就可能是可行的解決方案。
結論
流控是一種非常容易描述但卻隱藏了很多復雜性的特性。希望本文能夠幫助你理解在復雜分布式系統中實現流控所涉及的工具和算法。