模塊化的機器學習系統就夠了嗎?Bengio師生告訴你答案
深度學習研究者從神經科學和認知科學中汲取靈感,從隱藏單元、輸入方式,到網絡連接、網絡架構的設計等,許多突破性研究都基于模仿大腦運行策略。毫無疑問,近年來在人工網絡中,模塊化和注意力經常被組合使用,并取得了令人印象深刻的結果。
事實上,認知神經科學研究表明,大腦皮層以模塊化的方式表示知識,不同模塊之間進行通信,注意力機制進行內容選擇,這也就是上述提到的模塊化和注意力組合使用。在近期的研究中,有人提出,大腦中的這種通信方式可能對深度網絡中的歸納偏置有意義。這些高級變量之間依賴關系的稀疏性,將知識分解為盡可能獨立的可重組片段,使得學習更有效率。?
盡管最近的許多研究都依賴于這樣的模塊化體系架構,但研究者使用了大量的技巧以及體系架構修改,這使得解析真正的、可用的體系架構原則變得具有挑戰性。
機器學習系統正逐漸顯露出更稀疏、更模塊化架構的優勢,模塊化架構不僅具有良好的泛化性能,而且還能帶來更好的分布外(OoD) 泛化、可擴展性、學習速度和可解釋性。此類系統成功的一個關鍵是,用于真實世界設置的數據生成系統被認為由稀疏交互部分組成,賦予模型類似的歸納偏置將是有幫助的。然而,由于這些真實世界的數據分布是復雜和未知的,該領域一直缺乏對這些系統進行嚴格的定量評估。
由來自加拿大蒙特利爾大學的 Sarthak Mittal、Yoshua Bengio、 Guillaume Lajoie 三位研究者撰寫的論文,他們通過簡單且已知的模塊化數據分布,對常見的模塊化架構進行了全面評估。該研究強調了模塊化和稀疏性的好處,并揭示了在優化模塊化系統時面臨挑戰的見解。一作及通訊作者 Sarthak Mittal 為 Bengio 和 Lajoie 的碩士生。

- 論文地址:https://arxiv.org/pdf/2206.02713.pdf
- GitHub 地址:https://github.com/sarthmit/Mod_Arch
具體而言,該研究擴展了 Rosenbaum 等人的分析,并提出了一種方法來評估、量化和分析模塊化架構的常見組成部分。為此,該研究開發了一系列基準和指標,旨在探索模塊化網絡的效能。這揭示了有價值的見解,不僅有助于識別當前方法的成功之處,還有助于識別這些方法何時以及如何失敗的。
該研究的貢獻可總結為:
- 該研究基于概率選擇規則來開發基準任務和指標,并用基準和指標來量化模塊化系統中的兩個重要現象:崩潰(collapse)和專業化(specialization)。
- 該研究提煉出常用的模塊化歸納偏置,并通過一系列模型進行系統地評估,這些模型旨在提取常用的架構屬性(Monolithic, Modular, Modular-op、GT-Modular 模型)。
- 該研究發現,當一個任務中有很多潛在規則時,模塊化系統中的專業化可以顯著提高模型性能,但如果只有很少的規則,則不會如此。
- 該研究發現,標準的模塊化系統在專注于正確信息的能力和專業化能力方面往往都不是最優的,這表明需要額外的歸納偏置。
定義 / 術語
本文中,研究者探究了一系列模塊化系統如何執行常見的任務,這些任務由我們稱為規則數據的合成數據生成過程制定。他們介紹了關鍵組成部分的定義,包括(1)規則以及這些規則如何形成任務,(2)模塊以及這些模塊如何采用不同的模型架構,(3)專業化以及如何評估模型。詳細設置如下圖 1 所示。

規則。為了正確理解模塊化系統并分析它們的優缺點,研究者考慮采用的綜合設置允許對不同的任務要求進行細粒度的控制。尤其是必須在如下公式 1-3 中展示的數據生成分布上學習操作,他們稱之為規則。

給定上述分布,研究者定義了一個成為其專家的規則,也即規則 r 被定義為 p_y(·|x, c = r) ,其中 c 是表示上下文的分類變量,x 是輸入序列。
任務。任務是由公式 1-3 中展示的一組規則(數據生成分布)描述。不同的{p_y(· | x, c)}_c 集合意味著不同的任務。其中對于給定數量的規則,研究者在多個任務上訓練模型以消除任何對特定任務的偏見。
模塊。模塊化系統由一組神經網絡模塊組成,其中每個模塊都對整體輸出做出貢獻。通過如下函數形式可以看出這一點。

其中 y_m 表示輸出,p_m 表示 m^th 模塊的激活。
模型架構。模型架構描述了為模塊化系統的每個模塊或者單片系統的單個模塊選擇什么架構。在本文中,研究者考慮采用了多層感知機(MLP)、多頭注意力(MHA)和循環神經網絡(RNN)。重要的是,規則(或者數據生成分布)進行調整以適用于模型架構,比如基于 MLP 的規則。
數據生成過程
由于研究者的目標是通過合成數據來探究模塊化系統,因此他們詳細介紹了基于上文描述的規則方案的數據生成過程。具體地,研究者使用了簡單的混合專家(MoE)風格的數據生成過程,希望不同的模塊可以專門針對規則中的不同專家。
他們解釋了適用于三種模型架構的數據生成過程,它們分別是 MLP、MHA 和 RNN。此外,每個任務下面都有兩個版本:回歸和分類。
MLP。研究者定義了適用于基于模塊化 MLP 系統的學習的數據方案。在這一合成數據生成方案中,一個數據樣本包含兩個獨立的數字以及從一些分布中采樣的規則選擇。不同的規則生成兩個數字的不同線性組合以給出輸出,也即線性組合的選擇是根據規則進行動態實例化,如下公式 4-6 所示。


MHA。現在,研究者定義了針對模塊化 MHA 系統的學習而調整的數據方案。因此,他們設計了具有以下屬性的數據生成分布,即每個規則分別由不同的搜索、檢索概念以及檢索信息的最終線性組合組成。研究者在如下公式 7-11 中用數學方法描述了這一過程。

RNN。對于循環系統,研究者定義了一種線性動態系統的規則,其中可以在任何時間點觸發多個規則中的一個。在數學上,這一過程中如下公式 12-15 所示。

模型
以往一些工作宣稱端到端訓練的模塊系統優于單體系統,尤其是在分布式環境中。但是,對于這些模塊化系統的好處以及它們是否真的根據數據生成分布進行專業化處理還沒有詳細和深度的分析。
因此,研究者考慮了四類允許不同程度專業化的模型,它們分別是 Monolithic(單體)、Modular(模塊化)、Modular-op 和 GT-Modular。下表 1 展示了這些模型。

Monolithic。單體系統是一個大型神經網絡,它以整體數據 (x, c) 作為輸入,并依此做出預測 y^。系統中顯式 baked 的模塊化或稀疏性沒有出現歸納偏置,并完全取決于反向傳播來學習解決任務所需的任何函數形式。
Modular。模塊化系統由很多模塊組成,每個模塊都是給定架構類型(MLP、MHA 或 RNN)的神經網絡。每個模塊 m 將數據 (x, c) 作為輸入,并計算輸出 y?_m 和置信度分數,跨模塊歸一化為激活概率 p_m。
Modular-op。模塊化操作系統與模塊化系統非常相似,僅有一點不同。研究者沒有將模塊 m 的激活概率 p_m 定為 (x, c) 的函數,而是確保激活僅由規則上下文 C 決定。
GT-Modular。真值模塊化系統作為 oracle 基準,即完美專業化的模塊化系統。
研究者表明,從 Monolithic 到 GT-Modular,模型越來越多地包含模塊化和稀疏性的歸納偏置。
度量
為了可靠地評估模塊化系統,研究者提出了一系列度量,不僅可以衡量此類系統的性能優勢,還能通過崩潰和專業化這兩種重要的形式進行評估。
性能。第一組評估度量基于分布內和分布外(OoD)設置中的性能,反映了不同模型在各種任務上的表現。對于分類設置,研究者報告了分類誤差;對于回歸設置,研究者報告了損失。
崩潰。研究者提出了一組度量 Collapse-Avg 和 Collapse-Worst,以此來量化模塊化系統遭遇到的崩潰量(也即模塊未充分利用的程度)。下圖 2 展示了一個示例,可以看到模塊 3 未被使用。
專業化。為了對崩潰度量做出補充,研究者還提出了以下一組度量,即(1)對齊,(2)適應和(3)量化模塊化系統獲得的專業化程度的逆互信息。
實驗
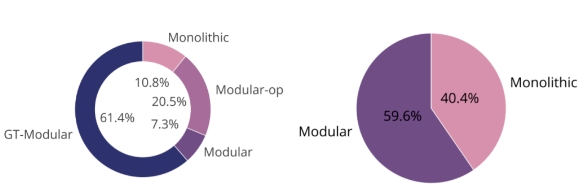
下圖表明,GT-Modular 系統在大多數情況下都最優(左)的,這表明專業化是有益處的。我們還看到,在標準端到端訓練的模塊化系統和 Monolithic 系統之間,前者的表現優于后者但差距不大。這兩個餅圖共同表明,當前的端到端訓練的模塊化系統沒有實現良好的專業化,因此在很大程度上是次優的。

然后,該研究查看特定架構選擇,并分析它們在越來越多的規則中的性能和趨勢。

圖 4 顯示,雖然完美的專業化系統 (GT-Modular) 會帶來好處,但典型的端到端訓練的模塊化系統是次優的,不能實現這些好處,特別是隨著規則數量的增加。此外,雖然這種端到端模塊化系統的性能通常優于 Monolithic 系統,但通常只有很小的優勢。

在圖 7 中,我們還看到不同模型的訓練模式在所有其他設置上的平均值,平均值包含分類錯誤和回歸損失。可以看到,良好的專業化不僅可以帶來更好的性能,而且可以加快訓練速度。

下圖顯示了兩個崩潰度量:Collapse-Avg 、Collapse-Worst。此外下圖還顯示了針對不同規則數量的不同模型的三個專業化指標,對齊、適應和逆互信息:
?
 ?
?