













開源神器 MegPeak,讓你更懂你的處理器!

在這個算力需求爆炸的大背景下,如何發揮出已有硬件的最大算力變得非常重要,直觀一點是:我們需要對現有算法,針對特定處理器,進行極致的性能優化,盡量滿足目前 AI 算法對算力高要求。
為了能夠做到極致的性能優化,可實現的方向有:
- 優化算法,使得算法能夠在滿足準確度前提下,訪存和計算量盡量小
- 優化程序,使得實現這些算法的程序最大限度發揮處理器性能
在優化程序的過程中,首先要解決的問題是:如何評估程序發揮了處理器幾成的算力,以及進一步優化空間和優化方向。
為了讓我們更懂處理器,MegEngine 團隊開發了一個處理器調試工具 MegPeak。
該工具主要用于幫助開發人員進行性能評估,開發指導等工作,項目代碼目前已完全開源,大家感興趣的話可以看下。
GitHub:??https://github.com/MegEngine/MegPeak???
下面我們來簡單看下,這款工具所擁有的功能,以及項目的技術實現細節。
MegPeak 介紹
通過 MegPeak,用戶可以測試目標處理器:
- 指令的峰值帶寬
- 指令延遲
- 內存峰值帶寬
- 任意指令組合峰值帶寬
雖然上面的部分信息可以通過芯片的數據手冊查詢相關數據,然后結合理論計算得到,但是很多情況下無法獲取目標處理器詳盡的性能文檔,另外通過 MegPeak 進行測量更直接和準確,并且可以測試特定指令組合的峰值帶寬。
MegPeak 使用方法
使用方法參考 MegPeak 的 Readme 文檔:
??https://github.com/MegEngine/MegPeak#build???
MegPeak 使用示例
測試 ArmV8 上通用指令峰值和延遲,編譯完成之后,在目標處理器上執行 megpeak,得到:
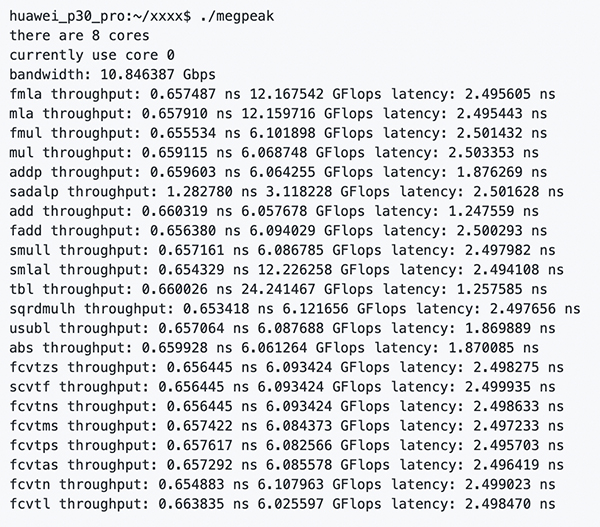
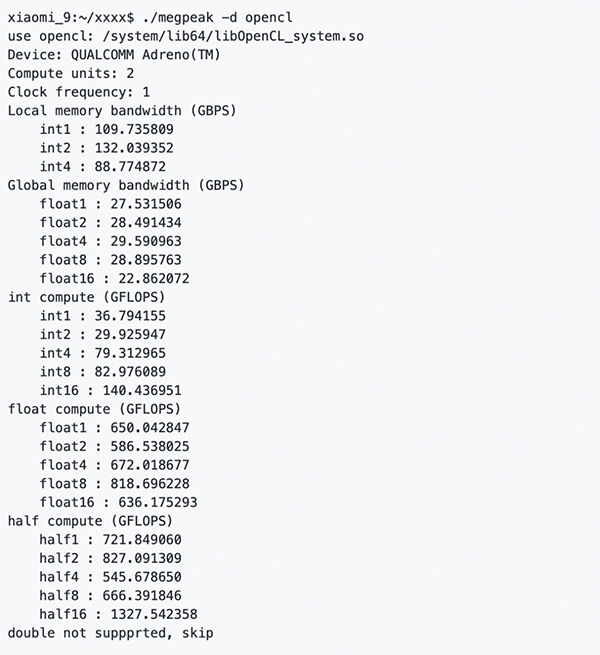
如上圖所示,MegPeak 可以精確測試出 CPU 上每條指令的計算峰值以及延遲周期。OpenCL 上將測試出不同數據類型進行訪存的 Local Memory,Global Memory 的帶寬,以及 int/float 不同數據類型進行計算的峰值。
這些數值,將有效指導我們評估目前程序的性能,并繪制 RoofLine,幫助用戶診斷出阻塞程序主要因素,是訪存或者計算。具體使用分析方法將在后面介紹。
MegPeak 原理
MegPeak 測試的主要參數是:
- CPU 不同指令的計算峰值,以及指令延遲,以及內存帶寬
- OpenCL 中不同內存的數據訪存帶寬,以及不同計算數據類型的計算峰值
要了解 MegPeak 是如何測試出上面這些性能數據,并且做到和數據手冊上查詢到盡量一致,因此需要讀者了解下面 CPU 流水線相關細節。
處理器流水線
現代處理器為了增加指令的吞吐,引入了指令流水線,指令流水線可以將一條指令的執行過程劃分為多個階段,經典的 5 級流水線有:取指令,翻譯指令,執行指令,訪問寄存器,寫回數據。
這 5 個階段,處理器中執行每個階段的物理單元獨立,因此理想狀態下,每個時鐘周期每個階段對應的物理單元都能執行一次對應的操作,這樣就形成了流水線,這樣處理器每個時鐘周期就可以完成執行一條指令。
如下表所示,從第 5 個時鐘周期之后,每個時鐘周期都會完成一條指令執行:
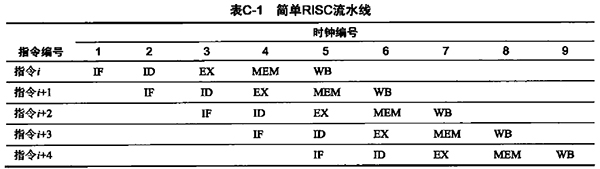
但是,流水線在實際執行時候不可能一直這樣流暢的執行下去,會存在以下的冒險,阻塞流水線。
- 結構冒險 —— 如果硬件無法同時支持指令的所有可能組合方式,就會出現資源沖突,從而導致結構冒險
- 數據冒險 —— 流水線指令存在先后順序,如果一條指令取決于先前指令的結果,就可能導致數據冒險
- 控制冒險 —— 分支指令及其他改變程序計數器的指令實現流水化時,可能導致控制冒險
MegPeak 中測量處理器指令的計算峰值和延遲就是通過控制指令間的數據冒險,盡可能排除結構冒險和控制冒險來實現的。因為 MegPeak 中需要通過寫 Code 來控制處理器的數據冒險,為了排除編譯器編譯 code 時候的優化帶來的干擾,所以在 MegPeak 在測試中的核心代碼使用匯編來實現的。
測試指令峰值
為了測量處理器上一條指令的計算峰值,我們需要寫出重復執行這條指令,但是沒有任何冒險的代碼,所以需要代碼控制數據冒險和控制冒險。
- 消除數據冒險 ---- 消除重復指令之間的數據依賴,讓前后指令之間沒有下面的數據相關,雖然 WAW,WRA 不是真正的數據相關,處理器可能會使用寄存器重命名來解決,但是我們還是盡量不要寫出這樣的數據相關。
- 寫后讀(RAW):上一條指令寫入,下一條指令讀取寫入數據,這時候后一條指令需要等上一條指令運行結束之后再運行
- 寫后寫(WAW):兩條指令前后寫入同一個寄存器,這時候數據寫入的先后順序很重要
- 讀后寫(WRA) :上一條指令讀取一個寄存器,下一條指令將新的數據寫入這個寄存器,他們的順序也同樣很重要
- 盡可能的消除控制冒險 ---- 為了重復多次執行同一條指令,我們可能會用循環來實現,但是循環里面有分支,可能會造成控制冒險,所以我們需要盡可能的循環展開,讓一個循環里面執行更多的數據無關的指令,但是這個數量會被處理器的寄存器數量限制。
下面是 MegPeak 測試 Arm64 上 fmla 指令計算峰值時候的核心 Code。
static int fmla_throughput() {
asm volatile(
"eor v0.16b, v0.16b, v0.16b\n"
"eor v1.16b, v1.16b, v1.16b\n"
...
"eor v19.16b, v19.16b, v19.16b\n"
"mov x0, #0\n"
"1:\n"
"fmla v0.4s, v0.4s, v0.4s\n"
"fmla v1.4s, v1.4s, v1.4s\n"
...
"fmla v19.4s, v19.4s, v19.4s\n"
"add x0, x0, #1 \n"
"cmp x0, %x[RUNS] \n"
"blt 1b \n"
:
: [RUNS] "r"(megpeak::RUNS)
: "cc", "v0", "v1", "v2", "v3", "v4", "v5", "v6", "v7", "v8", "v9", "v10", "v11", "v12", "v13",
"v14", "v15", "v16", "v17", "v18", "v19", "x0");
return megpeak::RUNS * 20;
}上面的內嵌匯編代碼中,主要做了幾件事情:
- 初始化 0–19 號 neon 寄存器為零,這一步不是必須的,但可以避免計算過程中出現 nan 導致的潛在影響。
- 創建主循環,主循環中每條指令執行,從對應的寄存器讀取數據,并執行 fmla 指令,將計算結果寫到相同的寄存器中,同一條指令內部沒有數據相關。
這里有一個問題需要解釋,為什么選擇 20 個寄存器:
- 如果寄存器選擇太少,上一次循環可能還沒有計算完成,下一次循環讀取相同的寄存器,可能造成數據相關,因此循環里面執行的指令條數需要大于指令延遲和處理器單個周期內能夠執行的指令數的乘積,但是我們不知道這條指令延遲,但是可以估計,除了特殊的指令,延遲一般不超過 10 個時鐘周期。
- Arm64 有 32 個 neon 寄存器,為什么不選擇 32 個寄存器,因為 20 個寄存器已經可以避免數據和控制相關了,測試發現使用更多的寄存器影響很小。
執行上面的代碼,可以統計執行的時間,加上可以提前通過指令的數目以及循環的次數計算出真正的計算量,因此便可以計算出指令的計算峰值。
測試指令延遲
為了測量處理器上一條指令的執行延遲,我們需要寫出重復執行這條指令,并讓這些指令之間存在嚴格的數據冒險,盡量排除其他冒險。
- 制造數據冒險 ---- 讓前后兩條指令之間的數據存在真正的數據依賴(RAW),即上一條指令的輸出為下一條指令的輸入;
- 盡可能的消除控制冒險 ---- 同上。
下面是 MegPeak 測試 Arm64 上 fmla 指令延遲的核心 Code。
static int fmla_latency() {
asm volatile(
"eor v0.16b, v0.16b, v0.16b\n"
"mov x0, #0\n"
"1:\n"
"fmla v0.4s, v0.4s, v0.4s\n"
//重復 20 次
...
"fmla v0.4s, v0.4s, v0.4s\n"
"add x0, x0, #1 \n"
"cmp x0, %x[RUNS] \n"
"blt 1b \n"
:
: [RUNS] "r"(megpeak::RUNS)
: "cc", "v0", "x0"
);
return megpeak::RUNS * 20;
}上面的內嵌匯編代碼中,主要將
fmla v0.4s, v0.4s, v0.4s\n
這條指令重復了 20 次,這樣每條指令都依賴上一條指令的計算結果,所以存在嚴格的數據相關。
執行代碼,統計執行時間,通過執行的指令條數,可以計算出這條指令最終的延遲。
上面的代碼在 MegPeak 中實現,不是這么直接,而是通過宏來實現 code 的生成。
用 MegPeak 測到的數據,可以用來干什么
MegPeak 可以測試出處理器的內存帶寬,指令的理論計算峰值,指令的延遲等信息,因此可以幫助我們:
- 繪制 Roofline Model 指導我們優化模型性能
- 評估程序的優化空間
- 探索指令組合的理論計算峰值
另外 MegPeak 還可以提供對理論的驗證,如我們通過處理器頻率 單核單周期指令發射數量 每條指令執行的計算量可以計算出理論計算峰值,然后我們可以通過 MegPeak 進行實際測量進行驗證。
繪制指令相關的 Roofline Model
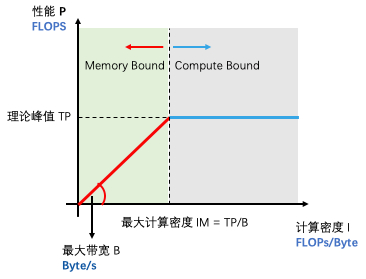
Roofline 模型被大量的使用在高性能計算中,是評估算法的可優化程度和優化方向的重要工具。使用 MegPeak 可以繪制出更加具體的關于指令對應的 Roofline 模型,如:在 CPU 中,不同的數據類型,雖然訪存帶寬不會改變,但是計算峰值差距比較大,比如在 arm 上 float 的計算峰值和 int8 的計算峰值差距很大。
評估代碼優化空間
在優化具體算法的時候,可以通過 MegPeak 測試出 kernel 里面的主要指令的最大峰值,如在 Arm 上優化 fp32 Matmul 的時候,主要用到的指令是 fmla 指令,這時候可以測試程序實際運行的峰值,如果指令的峰值和程序的峰值差距越小,說明代碼優化得越好。
另外,可以根據算法實現計算出計算量和訪存量,并使用 MegPeak 繪制出上面的 Roofline,通過計算實際的計算密度,然后再對應到 Roofline 中,如果計算密度落在上圖中的綠色區域,說明程序需要更多考慮優化訪存,提供更優的訪存模型,如分塊,提前 pack 數據等。如果計算強度的點落在灰色區域說明,代碼已經最優了,如果還想進一步提速,只能考慮從算法角度進行優化了,如:在卷積中使用 FFT,Winograd 等算法進行優化。
探索最優指令組合
很多 Kernel 的優化不是單純的某一條指令就可以衡量,可能需要多條指令的組合才能代表整個 Kernel 的計算,因此我們需要探索如何組織這些指令使其達到處理器最優的性能。下面列舉在 A53 小核優化 fp32 Matmul 的過程中,由于 Matmul 是計算密集型算子,考慮通過多發射隱藏訪存指令的開銷,使用 MegPeak 配合進行分析,探索如何組合指令實現盡可能多地多發射。
因為小核上面資源有限,指令多發射有很多限制:
- 首先使用 MegPeak 出測試 A53 上 fp32 的 fmla 指令的計算峰值,將其定義為 100% 峰值計算性能
- 測試哪些指令組合可以支持雙發射
- 在 MegPeak 中添加 vector load 和 fmla 1:1 組合的代碼,然后測試其峰值僅僅為 float 峰值的 36%,表明 Vector load 和 fmla 不能雙發射
- 同樣可以測得通用寄存器 load 指令 ldr+fmla 的組合可以達到 float 峰值的 93%,說明 ldr 可以和 fmla 雙發射
- 同上可以測得 ins + fmla 能雙發射,ins + vector load 64 位 可以雙發射
- 根據 Matmul 最內層 Kernel 的 計算原理,如最內層 Kernel 的分塊大小是 8x12,那最內層需要讀取:20 個 float 數據,計算 24 次 fmla 計算
- 結合上面的 MegPeak 測試的信息,我們需要找到用最少時鐘完成這:20 個 float 數據 load,和 24 次 fmla 數據計算的指令組合,因此需要將盡可能多的數據 load 和 fmla 進行雙發射,隱藏數據 load 的耗時
- 最后的指令組合是:
- 使用 vector load 64 指令 + ldr + ins 組合成為一個 neon 寄存器數據,因為 ldr 和 ins 都可以和 fmla 雙發射,把他們和 fmla 放在一起可以隱藏他們的耗時
- 在這 3 條指令中穿插 fmla 指令,并盡可能解決數據依賴
根據上面的指令組合可以使得 Matmul 在小核上達到計算峰值的 70% 左右。
總結
MegPeak 作為一個進行高性能計算的輔助工具,能夠使得開發人員輕松獲得目標處理器的內在的詳細信息,輔助進行對代碼的性能評估,以及優化方法設計。但是 MegPeak 也有一些需要豐富的方向:
- 支持獲取更多的處理器性能數據,如:L1,L2 cache 的大小,自動探索各種指令組合的雙發射情況,并大概繪制出一個處理器后端的縮略圖。如:en.wikichip.org/w/image
- 支持測量移動端 OpenCL 的更多細節信息,如:warp size,local memory 大小等。
如果有同學對上面的功能感興趣,可以到 GitHub 上提交代碼,或嘗試使用 MegPeak。















